





让我们考虑一下语言建模:从先前的单词上下文预测即将出现的单词。与前面ngram语言模型相比,基于神经网络的语言模型具有许多优点。其中包括,神经语言模型不需要平滑处理,它们可以处理更长的历史记录,并且可以在相似单词的上下文中进行泛化。对于给定大小的训练集,神经语言模型比n-gram语言模型具有更高的预测精度。此外,神经语言模型是我们将介绍的用于机器翻译、对话和语言生成等任务的许多模型的基础。另一方面,这种性能的提高是有代价的:神经网络语言模型的训练速度明显慢于传统语言模型,因此对于许多任务,n-gram语言模型仍然是正确的工具。我们将描述简单前馈神经语言模型。现代神经语言模型通常不是前馈的,而是递归的,
前馈神经LM是一种标准的前馈网络,它在t时刻将若干个先前单词(
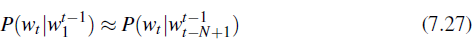
在下面的例子中,我们将使用一个4-gram的例子,所以我们将展示一个网络来估计概率
Embeddings
在神经语言模型中,先前的上下文由先前单词的嵌入(也就是词向量)表示。将先前的上下文表示为嵌入,而不是用n-gram语言模型中使用的精确单词表示,这使得神经语言模型能够比n-gram语言模型更好地泛化为不可见的数据。例如,假设我们在训练中见过这个句子:
I have to make sure when I get home to feed the cat.但是我们从来没有见过“feed the”这个词后面跟着“dog”这个词。在我们的测试集中,我们试图预测前缀“I forgot when I got home to feed the”之后会发生什么。一个n-gram语言模型可以预测“cat”,但不能预测“dog”。但是,神经LM可以利用“cat”和“dog”具有类似嵌入的事实,将能够为“dog”和“cat”分配相当高的概率,仅仅因为它们有相似的向量。
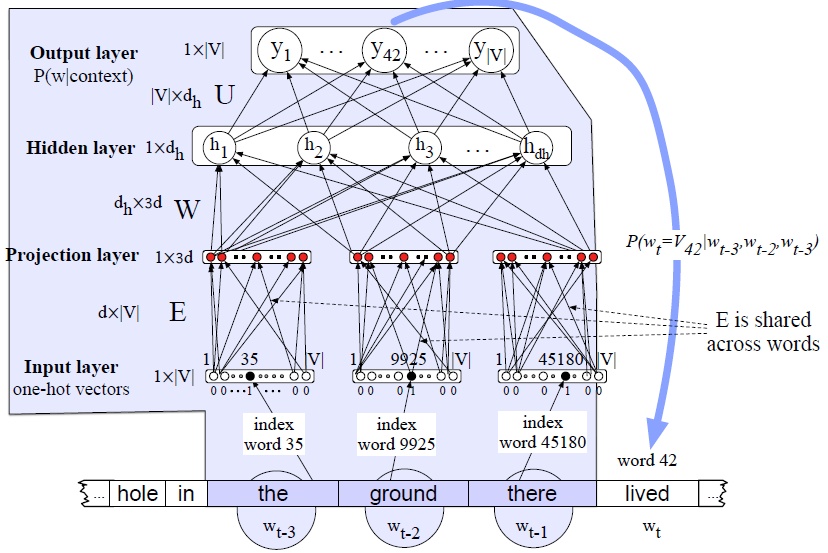
让我们看看这在实践中是如何工作的。假设我们有一个嵌入字典E,对于词汇表V中的每个单词,这个单词的嵌入,可能是由word2vec算法预先计算出来的。图7.12为简化后的FFNNLM示意图,N=3,我们有一个在时间t移动窗口,其中有一个嵌入向量代表每个3之前的单词( 词
图7.12所示的模型是足够的,假设我们通过word2vec方法来单独学习嵌入。使用另一种算法学习我们用于输入单词的嵌入表示的方法称为预训练。如果这些预先训练好的嵌入足以满足您的目的,那么这就是您所需要的。然而,我们常常希望在训练网络的同时学习嵌入。当网络所设计的任务(情感分类、翻译或解析)对什么是好的表示设置了严格的限制时,这是正确的。因此,让我们展示一个允许学习嵌入式的体系结构。为此,我们将在网络中添加一个额外的层,并将错误传播回嵌入向量,从带有随机值的嵌入开始,然后慢慢地向合理的表示方式移动。为了使它在输入层工作,而不是预先训练好的嵌入,我们将把前面的N个单词表示为长度为|V|的一个one-hot vector,即,每个单词对应一个维度。一个one-hot vector是一个向量,它的一个元素在对应于词汇表中该单词的索引的维数中等于1,而所有其他元素都设置为零。
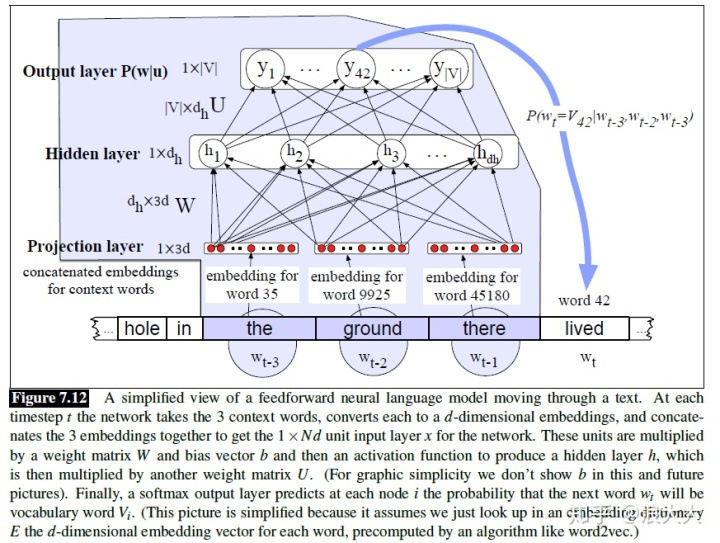
最后,一个softmax输出层在每个节点i预测下一个单词
因此,在“toothpaste”一词的one-hot表示中,假设单词中索引为5,

图7.13显示了LM训练中学习嵌入所需的额外层。这里,N=3个上下文单词表示为3个one-hot向量,通过E嵌入矩阵的3个实例完全连接到嵌入层。注意,我们不想学习将前三个单词映射到投影层的独立权重矩阵,我们想要在这三个单词之间共享一个嵌入字典E(已经学习到的词向量矩阵)。这是因为随着时间的推移,许多不同的单词会以
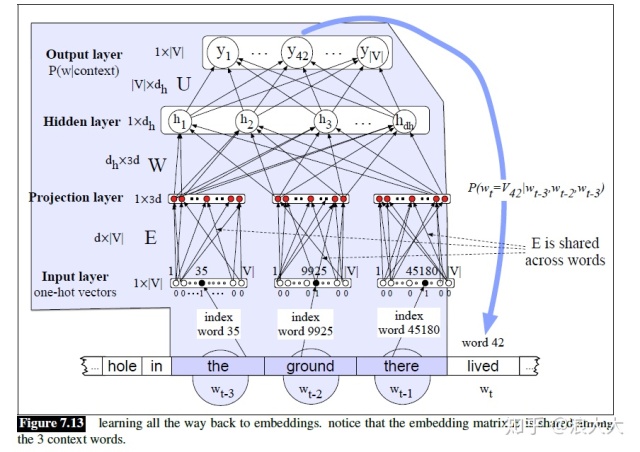
让我们通过图7.13的前向计算:
- 从E中选择三个嵌入: 给定前面的三个单词,我们查找它们的索引,创建3个one-hot向量,然后将每个向量乘以嵌入矩阵E。考虑
。“The”(索引35)的一个热向量乘以嵌入矩阵E,得到第一个隐藏层的第一部分,称为投影层。因为输入矩阵E的每一行只是一个单词的嵌入,而输入为one-hot列向量
,对应单词
i,输入w的投影层为
,对应单词i的嵌入。
- 乘以W: 现在我们乘以W(加上b),通过修正的线性(或其他)激活函数得到隐含层h。
- 乘以U: h现在乘以U。
- 应用softmax: 在softmax之后,输出层的每个节点i估计概率
综上所述,如果我们用e表示投影层,将三个上下文向量的3个嵌入连接起来形成,神经语言模型的方程为:
训练神经语言模型
为了训练模型,即设置所有参数
一般的训练过程是把很长的文本作为输入,把所有的句子连接起来,以随机权重开始,然后迭代地遍历文本,预测每个单词的
该损失的梯度为:
这种梯度可以以任何标准神经网络计算框架,将通过U, W, b, Ef反向传播 .训练参数以减少损失将结果在一个算法语言建模(一个单词预测),但还一套新的嵌入E,可以用作其他词表示的任务。















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









