





作者:
侯宇,业务架构师,Milvus 社区用户
在深度学习的浪潮下,无论是文本、语音、图像、时间序列还是消费者特征,都可以用一组形如 [0.6, 0.3, 0.7,......0.19] 的实数来表征。 这一组实数被称为特征向量。 那什么是向量检索呢[1]?向量检索就是在一个给定向量数据集合中,检索出与查询向量最相近的 Topk 个向量。| 常见应用场景
图片、视频、语音、文本等非结构化数据可以通过人工智能技术(深度学习算法)提取特征向量,然后通过对这些特征向量的计算和检索来实现对非结构化数据的分析与检索。针对向量检索常见的应用场景有[2]:- 图片识别:以图搜图,通过图片检索图片。具体应用如:车辆检索和商品图片检索等。
- 视频处理:针对视频信息的实时轨迹跟踪。
- 自然语言处理:基于语义的文本检索和推荐,通过文本检索近似文本。
- 声纹匹配,音频检索。
- 文件去重:通过文件指纹去除重复文件。
- 新药搜索,基因筛选。
向量检索面临的挑战主要在以下几个方面:
- 高维数据:向量数据维度通常是 256/512 维。
- 海量数据:在常用的图片或视频处理场景中,向量数据通常在亿级别。
- 高召回:为保证检索效果,精度召回率通常要求 95% 以上。
- 高性能:为保证用户体验,向量检索的响应要求毫秒级。
目标
我们知道向量的维度很高,并且规模庞大,这就决定了向量数据在计算时会占用较多内存。比如在 NLP 中,一个词向量可以表示成一个 256 维的矩阵,内存占用将是:
一个词向量:4 (float浮点数) * 256 = 1,024 bytes = 1 K
百万数据集:1,000,000 * 1 K / 1,024 ≈ 1 G
亿级数据集:1 G * 100 ≈ 100 G
可以看出在亿级别的词向量数据规模下,占用内存达到上百 GB。那么除了应对以上挑战,如何减少内存占用也是向量检索服务的目标。
本质
向量检索服务的本质就是把高维空间的数据切分到子空间进行搜索。通过对向量建立索引,减少搜索范围,实现高性能的向量数据分析。关于向量索引的分类有:
- 基于量化的索引
- 基于图的索引
- 基于树的索引
- 基于哈希的索引
- 向量索引构建与向量查询分离,索引作为离线服务,查询作为在线服务。优点是查询与索引构建分离,对于查询和构建的并发任务而言互相不干涉;缺点是需要较多的服务器,并且离线与在线的数据一致性也是一个问题。
- 向量索引构建与向量查询不分离,以 Milvus 为例。优点是可以利用较少的硬件资源来完成查询和索引构建的任务,可以充分利用磁盘资源存储原始向量,提供查询原始向量的能力;缺点是向量查询和索引构建无法并发,会出现资源抢占,限制了多个业务并发处理的能力。
Milvus 是一款开源向量相似度搜索引擎,建立在 Faiss、NMSLIB、Annoy 等向量索引库基础之上,具有功能强大、稳定可靠以及易于使用等特点。本文将介绍一个基于 Milvus 实现的文本召回解决方案。
在推荐系统、搜索系统中,文本召回是整个系统架构的重要组成部分。在深度学习来临之前,文本召回使用的是倒排索引技术。但是随着文本内容的增多和场景含义的丰富, 同一个词在不同文本中的意思可能不尽相同。然而倒排索引中的词本身是无法表征文本含义的,导致召回的文本充满了歧义。
利用文本向量化技术可以对文本含义进行表征,再利用向量检索技术来召回相似文本,可以在一定程度上避免倒排召回的缺点。
文本向量化
在本文的应用场景中,用户问句是最重要的文本形式。问句长度一般情况下为10~30 个词左右。目前生成句向量的方式有很多种:
- Tfidf:此方式同倒排一样,无法表征句子的意思。
- 分词,训练词向量模型,然后将问句中的词的词向量相加求平均;这在一定程度上表征了句子信息,在绝大多数场景下够用。
- 利用 Bert 等预训练模型获取相关的句向量。
- 支持基于 Python / Java / Go / C++ 的 SDK 和 RESTful API
- 支持 Annoy、Faiss、HNSW 等多种算法库
- 支持 CPU 和 GPU 运算
- 以 collection 为基本的管理单元,在 collection 中再划分 partition 为基准,支持粗粒度与细粒度的数据管理
- 支持原始向量存储与查询
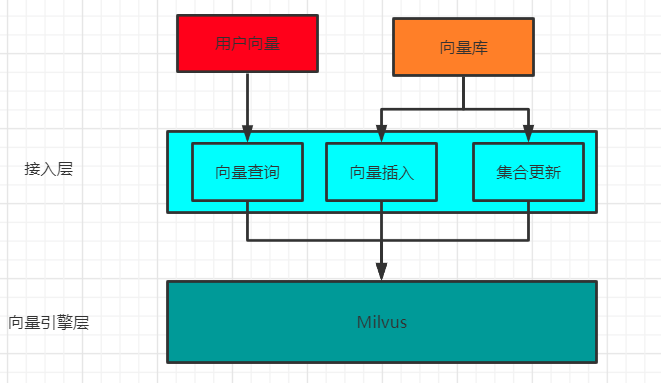
- 创建一个 collection,用于插入向量和构建向量索引。
- 在查询时,指定 collection 进行向量检索,返回 Topk 个向量。
- 当存在索引更新的时候,则建立一个新的 collection,重复步骤1。当新的 collection 及索引建立完毕,手动释放掉旧的 collection。此步骤一般放在低频访问时段。
 | 总结
从向量检索中间件的角度来衡量,Milvus 是极具市场潜力的开源组件。Milvus 本身的丰富特性就在一定程度上可以灵活地支持业务场景。
从业务场景的角度考虑, 拥有了 Milvus 可以更加专注地做业务逻辑上的处理和适配,而不用担心向量检索的速度与读取。这使得业务开发人员更专注于业务上的逻辑变更,更有利于业务的快速迭代和演进。此外,Milvus 的 RoadMap 能看出它当前是一个向量检索引擎,但是后续会向混合查询方向优化,具备更强的非结构化数据的存储和查询能力。
参考文献
| 总结
从向量检索中间件的角度来衡量,Milvus 是极具市场潜力的开源组件。Milvus 本身的丰富特性就在一定程度上可以灵活地支持业务场景。
从业务场景的角度考虑, 拥有了 Milvus 可以更加专注地做业务逻辑上的处理和适配,而不用担心向量检索的速度与读取。这使得业务开发人员更专注于业务上的逻辑变更,更有利于业务的快速迭代和演进。此外,Milvus 的 RoadMap 能看出它当前是一个向量检索引擎,但是后续会向混合查询方向优化,具备更强的非结构化数据的存储和查询能力。
参考文献
- [1]https://zhuanlan.zhihu.com/p/90677337
- [2]https://milvus.io/cn/docs/v0.6.0/reference/application.md
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









