






最近有同学反馈更新太频繁,有点跟不上节奏,我们也改变了策略,由之前的一周更新四篇改为一周更新一到两篇,而内容也会更聚合,主要分为基础和应用两块内容。基础则包括操作系统、网络通信、数据结构与算法等,应用则包括数据库、Java相关的一些知识点。
端午节跟一位前辈聊了聊关于技术人员的发展,在聊到后端技术这块的时候,前辈特别提到了微服务。现在对于后端开发动不动就提到微服务,或者也只剩下微服务可以提了。首先微服务不是一个万能解药,其次微服务相关技术人才已经非常饱和了,在面试的时候仅仅是微服务作为你的亮点,这恰恰会变成你的弱点。
我非常认可他说的这点,微服务在大型企业级项目中确实有非常大的优势,但在一些对实时性要求非常高的业务中却并不太适合,而且微服务的相关人才已经有点烂大街了,我们非常需要一个强有力的技术突破点。
我理解的突破点是在贴合公司业务的前提下,团队创建一个更贴合公司业务本身的技术框架(一个工具或者一个产品),这个技术框架拥有自身的一些技术特点,甚至可以做成相关细分领域的saas产品,可以作为团队的强有力的技术支撑点。这个突破点并不是每个人都能找到,因为这个跟公司或者团队有非常大的关系,那在没有找到相关突破口之前,我们又能做点什么呢?
基础!基础!基础! 重复三遍。把基础打牢固,学习不同角度分析问题,以及前辈们是如何解决问题的,百变不离其中,这些都可以在以后应用到实际项目中去。
以上说了一大堆废话,但也是我最近的一些小小的感悟,今天我们再来看看TCP的拥塞控制算法。上一次我们谈到了TCP的其中一种也是默认的一种拥塞控制算法(【网络通信】两次面试(蚂蚁金服和头条)都被问到——TCP是如何实现拥塞控制的?),今天我们再来聊聊目前TCP拥有的几种拥塞控制算法,它们实现的思路是什么,以及各自的特点。
如何查看和设置系统使用的拥塞算法目前tcp拥塞控制算法已有很多种,例如reno\cubic\vegas\bbr等,不同的拥塞算法适用于不同的场景,我们可以针对自己的网络需求选择相应的拥塞控制算法。目前Linux内核中,默认使用的是cubic拥塞算法,我们通可以通过命令行查询:
cat /proc/sys/net/ipv4/tcp_allowed_congestion_control我们可以看到当前可以使用的拥塞算法有两种:
cubic reno而当前正在使用的拥塞算法是:
cat /proc/sys/net/ipv4/tcp_congestion_controlcubic如果我们要设置系统的拥塞算法,可以通过以下命令行执行:
sysctl net.ipv4.tcp_congestion_control = reno如果我们发现没有自己想要的拥塞算法,可以安装对应的内核算法。
具体有哪些拥塞算法TCP 拥塞控制的原则是,只要网络中没有出现拥塞,拥塞窗口的值就可以再增大一些,以便把更多的数据包发送出去,但只要网络出现拥塞,拥塞窗口的值就应该减小一些,以减少注入到网络中的数据包数。
但在实现以上拥塞控制原则之上,又延伸出了不同的设计思路。首先是基于时延控制拥塞的Vegas算法,验证增加时,增大拥塞窗口,减小时,减小拥塞窗口;其次是采用丢包控制拥塞的拥塞算法Reno、Cubic,它们将丢包视为出现拥塞,采取缓慢探测的方式,逐渐增大拥塞窗口,当出现丢包时,将拥塞窗口减小;然后是最新应用的BBR拥塞控制算法,实时测量网络带宽和时延,认为网络上报文总量大于带宽时延乘积时出现了拥塞。
今天我们重点讲解下Reno、Cubic以及BBR三种拥塞控制算法,也是最近、当前以及未来使用到的三种拥塞控制算法。
RenoReno算法也是Linux内核2.6.0之前TCP默认使用的一种拥塞控制算法,拥塞控制的过程分为四个阶段:慢启动、拥塞避免、快重传和快恢复。
由于上一篇中(【网络通信】两次面试(蚂蚁金服和头条)都被问到——TCP是如何实现拥塞控制的?),我们已经详细分析过了Reno算法的过程,我们这里就不再重复讲解了。
缺点:
Reno算法是根据ACK信号作为拥塞窗口增长的依据,在早期低带宽、低时延的网络中能够很好的发挥作用,但是随着网络带宽和延时(长距离)的增加,Reno 的缺点就渐渐体现出来了。如果一个RTT时间过长,也就是收到ACK的时间很长,导致拥塞窗口增长很慢,当碰上高带宽环境时,可能需要经历很多个RTT增长时间才能达到最大传输窗口,导致前期网络使用率偏低。
适用场景:
低延时、低带宽的网络
Cubic为了解决上面提到的TCP低利用率问题,有很新的TCP拥塞控制算法被提出来,其中Cubic 是 Linux 内核 2.6.8版本之后的默认 TCP 拥塞控制算法。Cubic的核心是Cubic的三次函数:
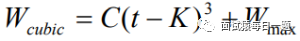
其中,C 是调节因子,t 是从上一次缩小拥塞窗口经过的时间,Wmax 是上一次发生拥塞时的窗口大小,而K则是由另外一个公式获得:
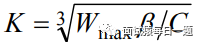
其中β是乘法减小因子,当出现数据包丢失时,Cubic 会通过乘法减小因子β来降低拥塞窗口,β一般设置值小于0.5,设置越小收敛越慢。设置越大,则会导致更快的收敛,但是会使协议的分析变得更加困难,并影响协议的稳定性。
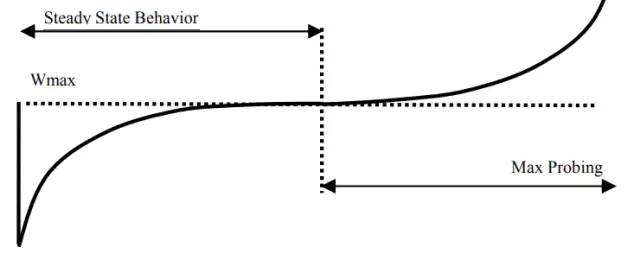
在刚开始阶段,该函数转入“凸”式增长阶段,拥塞窗口增长很快,在接近 Wmax 口时,增长速度变的平缓,避免流量突增而导致丢包;当某次拥塞事件发生时,Wmax设置为此时发生拥塞时的窗口值,然后把窗口进行乘法减小,乘法减小因子设为β,当从快速恢复阶段退出然后进入到拥塞避免阶段,此时CUBIC的窗口增长开始按照“凹”式增长曲线进行增长,从而可以达到网络带宽的高利用率和算法的稳定性。
Cubic 拥塞窗口增长曲线如下,凸曲线部分为稳定增长阶段,凹曲线部分为最大带宽探测阶段。
缺点:
Cubic 算法的另一个不足之处是过于激进,在没有出现丢包时会不停地增加拥塞窗口的大小,向网络注入流量,将网络设备的缓冲区填满,出现 Bufferbloat(缓冲区膨胀)。由于缓冲区长期趋于饱和状态,新进入网络的的数据包会在缓冲区里排队,增加无谓的排队时延,缓冲区越大,时延就越高。另外 Cubic 算法在高带宽利用率的同时依然在增加拥塞窗口,间接增加了丢包率,造成网络抖动加剧。
适用场景:
适用于高带宽、低丢包率网络,能够有效利用带宽。
BBRBBR是谷歌在 2016 年提出的一种新的拥塞控制算法,已经在 Youtube 服务器和谷歌跨数据中心广域网上部署。据 Youtube 官方数据称,部署 BBR 后,在全球范围内访问 Youtube 的延迟降低了 53%,在时延较高的发展中国家,延迟降低了 80%。目前 BBR 已经集成到 Linux 4.19 以上版本的内核中,而HTTP3.0也使用了该算法实现拥塞控制(HTTP3.0使用的是UDP协议,所以拥塞控制是基于应用层实现)。如果在4.19内核版本之前需要使用BBR算法,我们需要动手安装下BBR内核算法才能选择使用到。
Cubic是以丢包作为拥塞控制的关键因素,而BBR 算法不将出现丢包或时延增加作为拥塞的信号,而是认为当网络上的数据包总量大于瓶颈链路带宽和时延的乘积时才出现了拥塞。
BBR 算法周期性地探测网络的容量,交替测量一段时间内的带宽极大值和时延极小值,将其乘积作为作为拥塞窗口大小,使得拥塞窗口始的值始终与网络的容量保持一致。
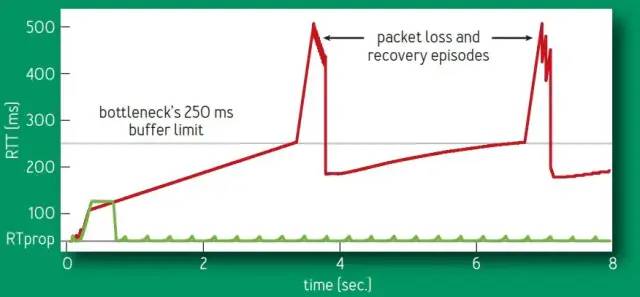
由于 BBR 算法不将丢包作为拥塞信号,所以在丢包率较高的网络中,BBR 依然有极高的吞吐量。
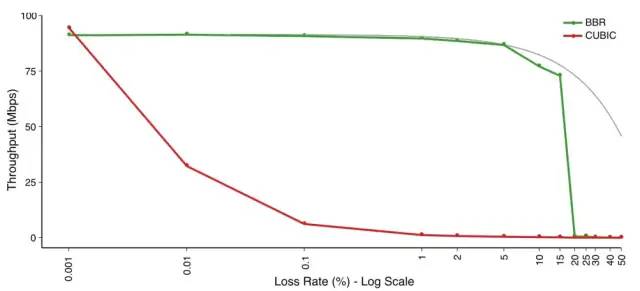
适用场景
适用于高带宽、高时延、有一定丢包率的长肥网络,可以有效降低传输时延,并保证较高的吞吐量。
小结以上就是我们了解到的几种拥塞控制算法,没有最好的,只有最合适的。我们可以根据自己的网络需求来选择合适的拥塞控制算法。
 精彩推荐【GS算法】一个获得诺贝尔奖的算法——如何实现稳定匹配【网络通信】基于QUIC通信协议优化HTTPS【MySQL】在MySQL中,涉及到金钱的字段一般用什么数据类型?
精彩推荐【GS算法】一个获得诺贝尔奖的算法——如何实现稳定匹配【网络通信】基于QUIC通信协议优化HTTPS【MySQL】在MySQL中,涉及到金钱的字段一般用什么数据类型?














 1147
1147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









