





1.前言
本文就使用tensorboard进行高维向量可视化过程中出现的一些bug和问题,进行一次总结,帮助那些和我一样的小白快速上手Tensorboard高维向量可视化。
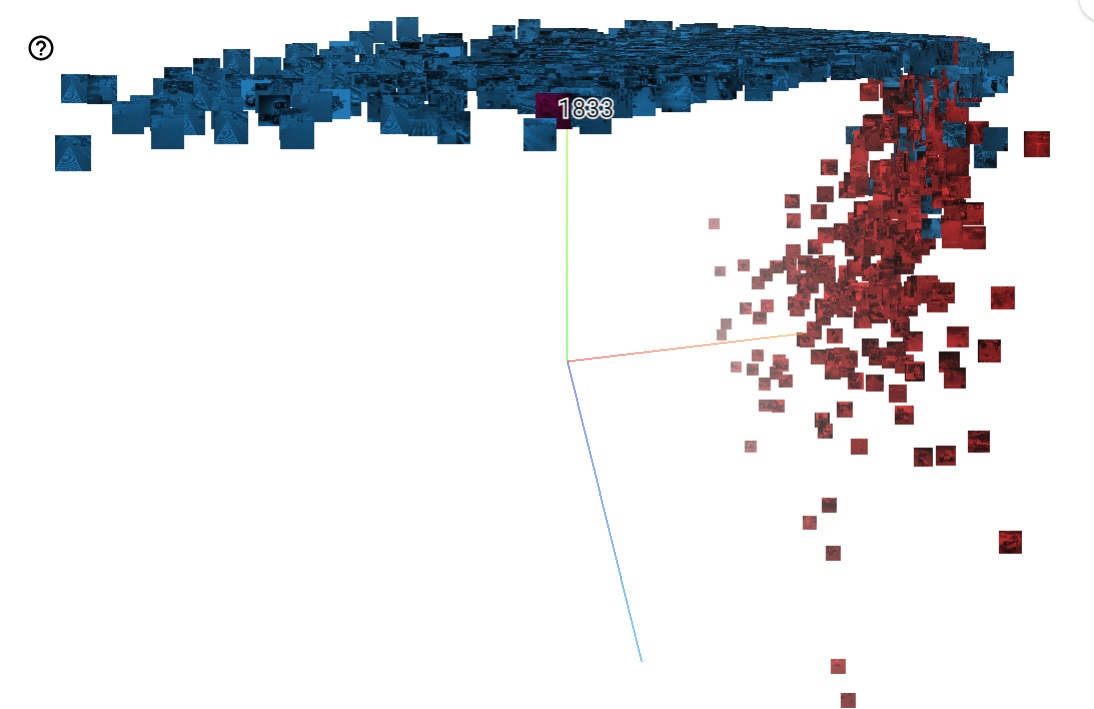
这里我先展示下最近我做的高维向量可视化的成果,蓝色是非事故图片,红色是事故图片。从结果上看出来,模型对事故和非事故的区分能力还算可以。

那么如何快速上手一个空间向量可视化过程,查看模型分类结果的空间分布呢?
这里我们使用到了tensorflow的tensorboard工具包,以事故分类为例,一步步克服tensorboard中的一些BUG。
2.特征向量提取与记录
一般而言,类似图像分类这种任务,在CNN最后几层中,一般会添加1x1卷积或者是全连接层,将backbone(特征提取网络)输出的特征图进行降维,便于接下来的分类。
在搭建模型的时候,也要刻意引出最后几层全连接层(或1x1卷积层)的输出,因为我们要可视化的高维向量就是这些层的输出(具体层数的输出维度,根据自己任务而定,这里我们在某一神经网络的最后,加入了个维度为8的全连接层(用作可视化的高维向量),然后再接上一个维度为2的全连接层(为了分类))。
这里我们基于pytorch搭建了个模型,模型forward函数代码如下:
def 可见,除了最后的输入output3,我们还额外输出了维度为64的output1和维度为8的output2。
等网络训练完毕后,我们就用训练完的权重跑一遍测试集,将
- 每张测试集图片的地址,
- 每张图片经过网络输出的output1,
- 每张图片经过网络输出的output2,
- 每张图片经过网络输出的output3
保存到csv文件中,代码如下
record保存的CSV的格式如下:
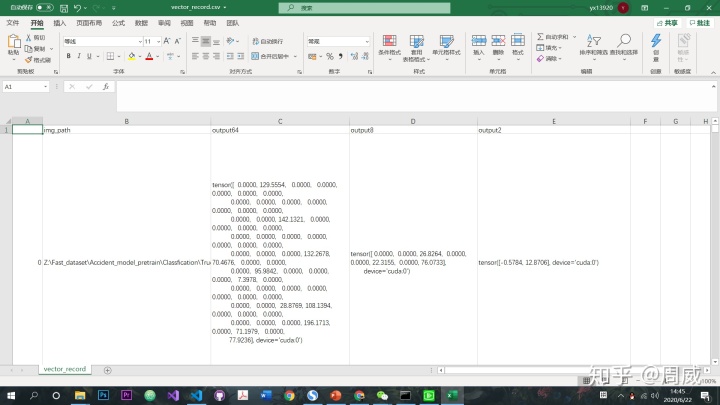
可见,output可都是tensor类型的呀!
3. 标签数据(meta.tsv)和图片数据(sprite.jpg)生成
从上面可视化的结果来看,每个空间展示图片的图片内容和标签(蓝或红)信息都被包含了,所以这里我们需要生成需要的标签数据和图片数据。我们从上面的csv文件中导入图片的地址数据,因为知道了地址数据,我们就知道了图片的内容以及标签(因为非事故和事故数据集的地址不同,所以可以用地址的关键字判断类别)
我们先定义一些变量,用作保存时的名称:
# PROJECTOR需要的日志文件名和地址相关参数
接着加载数据:
# 数据加载
3.1 载入图片并生成一张大图(sprite image)
这里我们先导入地址,然后将地址中的所有图片导入进来并保存到一张list中(名为img_list)
img_path接着我们定义一个大图像生成函数create_sprite_image,如下:
def 然后使用img_list生成这个大图像并保存:
img这里,sprite_image就生成好了,保存在log/sprite.jpg中。
3.2 生成标签数据meta.tsv
我们的事故和非事故图片集放在文件夹:
非事故:Z:Fast_datasetAccident_model_pretrainClassficationFalse_for_classificaition
事故:
Z:Fast_datasetAccident_model_pretrainClassficationTrue_for_classification
这里我们可以看出,可以用图片地址区分事故标签(False为非事故,True为事故)
那么我们代码这么写:
# # 生成每张图片对应的标签文件并写道相应的日志目录下
即完成了对meta.csv的记录,meta.csv里面是长这样的。
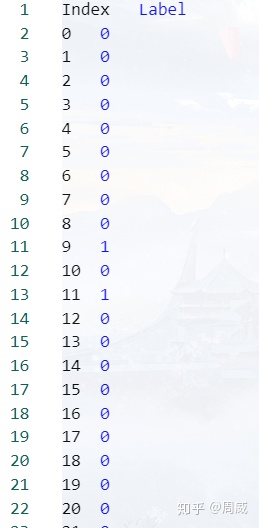
到这里,标签数据(meta.tsv)和图片数据(sprite.jpg)就生成了,接下来到最后的数据的匹配和关联+总日志文件生成。
4. 数据的匹配和关联+总日志文件生成
上述,我们在CSV文件中保存了每个图片在训练好的模型的输出向量,这个输出向量可以看作图片在浅层空间的表示。那我们就从该CSV文件导出需要的向量,这里我们以8维的向量为例子,导入的程序代码如下:
sample_data 这段代码需要注意的是,我们保存时候,向量以torch.tensor形式保存,从CSV导入的时候,输出的类型又是字符串str类型,所以我们需要做两件事
- 字符串转torch.tensor,这里使用eval()函数,且需要from torch import tensor
- torch.tensor转数组,因为后面要用tensorflow的tensorboard,所以需要转成numpy。
然后我们定义我们本文最重要的函数 visualisation(),代码如下:
LOG_DIR 需要注意的是图片的大小和上述第三部分定义的图片大小应当一致!
然后接着上面,将final_result输入到函数visualisation中,即可完成log日志的生成!
visualisationlog文件下的内容如下:

其中projector_config.pbtxt文件中的内容为

包含了各成员对应的关系
到最后,我们打开命令行CMD:
输入
tensorboard --logdir==E:Deep_learning_PytorchVideo_recognitionAccident_RecognitionCNN_LSTMlog --host=127.0.0.1
这里,一定注意--host!一定注意--host!一定注意--host!(重要的说三遍)
因为如果不输入--host,选择默认,那去网页上就是打不开的!就算打开了,也没有标签文件和图片数据的,这是花了我一个晚上血淋淋的教训呀!
5.总结
关于如何快速上手Tensorboard的高维向量可视化,本篇文章算是比较详细了!算是我一晚上的工作经验吧!终于可以安心做其他事了!















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









