





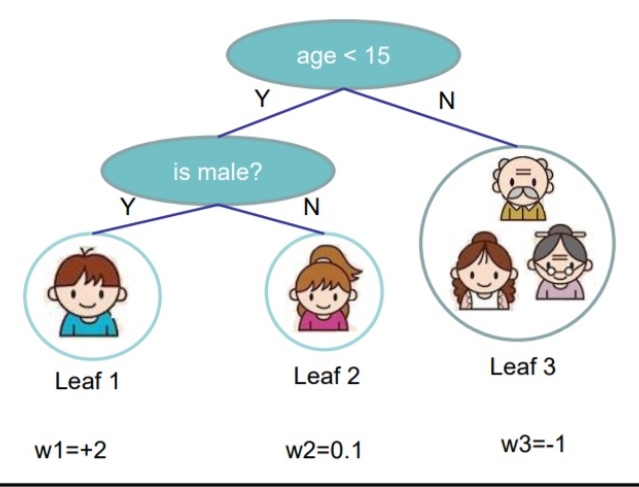
一、决策树
决策树有分类决策树和回归决策树。树的叶子节点对应类别,除叶子节点外的节点对应特征。训练集中每一个实例对应有且仅有一条从根节点到叶子节点的路径。
决策树的学习是利用启发式算法,极小化损失函数得到分类的准则,包括特征选择、决策树构建和剪枝的过程。其中,决策树生成是局部最优,剪枝是全局最优。
a. 特征选择准则
- 熵:变量的熵度量变量的不确定性,只与变量的概率分布有关
- 条件熵:
- 信息增益:经验熵与经验条件熵的差
表示由于特征X使得数据集D的分类不确定性降低的程度, 因此选择信息增益最大的特征,特征取值越多,信息增益越大。
- 信息增益比
b. 生成算法
- ID3: 从根节点开始,计算每个特征的信息增益,选择信息增益最大的作为结点特征,由该特征不同取值生成子结点,递归地对子结点调用以上方法,直到所有特征信息增益很小(达到阈值),或者无特征可选。若特征值对应数据实例中同属一类,则该类就是对应类标记。若无特征可选,实例数最大的类作为类标记。
缺点:容易过拟合。
2. C4.5: 算法与ID3相似,使用信息增益比来选择特征。
c. 剪枝
递归生成结点的方式对训练数据分类准确,但容易出现过拟合现象。尤其当数据中有噪声,或训练样例的数量太少以至于不能产生目标函数的有代表性的采样时。而过拟合的原因是在学习中过多地考虑对训练数据的正确分类,从而构造出过于复杂的树。通过剪枝可以简化树结构。
剪枝是通过极小化损失函数实现。
损失函数:
第一项表示预测误差,即模型拟合程度;第二项表示模型复杂度,alpha越大,模型越简单。
d. CART
CART 是分类回归决策树,在给定X的条件下,求出Y的条件概率分布。分类树生成采用基尼(Gini)系数最小作为标准,回归树采用平方误差最小作为标准,特征选择后生成二叉树。
- 最小二乘回归树生成
- 损失函数:
遍历变量
- 决策函数:
2. 分类树生成(完整)
- 基尼指数:假设K类,样本属于第k类的概率为
,
- 若给定数据集D,
- 在特征A的条件下,遍历A的取值a, 找到最小的Gini,即最优切分点。
对所有特征按以上方法求Gini, 最小的Gini即最优特征。然后对子结点按以上方法递归。
3.CART树剪枝
从生成决策树
- 设
- 对T中各个结点 t 计算以 t 为根节点的子树损失函数(Gini)以及,剪枝后损失函数减少的程度
- 对 结点t 剪枝,并对结点t按照多数表决归类得到数T。
-
- 递归剪枝直到树由一个根节点和两个叶结点构成
- 利用交叉验证检验子树序列得到最优子树。
# 决策树
二、随机森林
随机森林是集成算法中的bagging方法,是多个决策树组合器。每个决策树不同,提高系统的多样性,提升分类性能。
- 对训练数据重复有放回抽样,抽样样本为训练数据样本量;
- 对特征随机抽样;
- 对每个抽样样本,根据选择的特征进行学习决策树。
- 由多个独立的决策树进行多数表决得到分类结果。
# 随机森林
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
'''
n_estimators: the number of trees
boostrap: True is to boostrap samples
warm_start: False is to fit completely new forest
class_weight:'balanced','balanced_subsample'
max_samples: the number of samples to train base estimator
'''
model_RF = RandomForestClassifier(n_estimators=100, criterion='gini',
max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
bootstrap=True, oob_score=False, n_jobs=None,
random_state=None, verbose=0, warm_start=False,
class_weight=None, ccp_alpha=0.0, max_samples=None)
model_RF = RandomForestRegressor(criterion='mse') # criterion:'mse','mae'三、提升算法Adaboost
Adaboost 是将多个弱分类器组合成一个强分类器。通过前向贪心算法最小化损失函数得到,每一次迭代都在改变训练样本的权重分布且减少训练误差。误分类率越小,分类器权重越大,且上一轮分错的样本在下一轮得到的权重越大。
- 初始化训练样本权重
2. 对含初始化权重的训练集学习得到一个基分类器
3. 计算
4. 更新权重
5. 按以上方法迭代生成分类器
6. 最终分类器:
7. 损失函数:
# adaboost
from sklearn.ensemble import AdaBoostClassifier,AdaBoostRegressor
'''
base_estimator: base estimator, default DecisionTreeClassifier(max_depth=1)
learning_rate: shrinkage rate <=1,when and new estimator
algorithm: boosting algorithm,SAMME.R is supposed to calculate probability
'''
model_ada = AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0,
algorithm='SAMME.R', random_state=None)
model_ada.predict(x)
model_ada.staged_decision_function(x) # return a generator of boost decision function
model_ada.staged_predict(x) # return a generator of every boost prediction
# 回归,loss:'linear','square','exponential'
model_adareg = AdaBoostRegressor(base_estimator=None,n_estimators=50, learning_rate=1.0,
loss='loss', random_state=None)四、梯度提升回归树GBDT
bagging 算法每次抽样是独立的而且是又放回的,且样本量等于原始样本。boosting 算法每次的抽样分布依赖于上一次的计算结果,增加错误分类的样本的权重,从而不断改进上一轮的结果,不断提升。
GBDT是以CART回归树为基分类器的boosting 集成算法,第j轮学习中是对前j-1棵回归树和的残差进行拟合。新一轮的强分类器等于前一轮的强分类器加上新的弱分类器。
- 若采用平方误差,目标损失函数则为
, 参数是
相当于对残差拟合,即对
拟合回归树。
- 若采用对数损失函数,可以转化成多分类问题。
- 决策函数为
- 缩减shrinkage:
,
, μ 越小,迭代次数越多。
- 缺点:对异常点敏感,异常点会获得较高权重。
# gbdt
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor
'''
loss: 'deviance' 表示将回归树结果通过逻辑回归进行分类,'exponential'相当与adaboost
subsample: <1 总样本比例,抽样样本训练降低方差提高偏差
criterion:'friedman_mse','mse','mae' split 质量
init: 初始分类器。'zero' 或estimator, None for dummy estimator
n_iter_no_change:early stop,验证集分数没有变化的迭代次数
'''
model_gb = GradientBoostingClassifier( loss='deviance', learning_rate=0.1, n_estimators=100,
subsample=1.0, criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, min_impurity_split=None, init=None,
random_state=None, max_features=None, verbose=0,
max_leaf_nodes=None, warm_start=False, validation_fraction=0.1,
n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
# 回归,ls:'ls','lad','huber','quantile'
model_gb = GradientBoostRegressor(ls='ls', learning_rate=0.1, n_estimators=100,
subsample=1.0, criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, min_impurity_split=None, init=None,
random_state=None, max_features=None, verbose=0,
max_leaf_nodes=None, warm_start=False, validation_fraction=0.1,
n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
model_gb.fit(x, y)五、XGboost
- XGboost的步骤与GBDT相同,决策函数为
- 代价函数
, 第一部分是训练误差,第二部分表示模型的复杂度。
- 模型的复杂度可以采用L1, L2正则。
- XGboost假设在学习第m轮时,前面m-1轮的参数都是已知的,则目标函数进行二阶泰勒展开后,
,
- 复杂度
,分别是树的叶子结点数目
和叶子权重
。
XGboost 的差别和优势:
- XGboost 优化代价函数时,同时利用了一阶导数和二阶导数,提高精度,同时可自定义损失函数;
2. XGboost在代价函数中增加了正则项,控制模型的复杂度。包括叶子结点个数和叶子权重
3. XGboost 支持列抽样,在迭代时抽取部分特征学习
4. 稀疏感知忽略缺失值,或者为缺失值指定分类结点,提高计算速度。
5. 对新加入模型的决策树乘以一个学习率,控制优化速度。学习率越小,要求越多的决策树。
6. XGboost可支持线性分类器,灵活性强。
7. 利用快结构可并行计算。
# xgboost
import xgboost as xgb
from xgboost import XGBClassifier, XGBRegressor
model_xg = XGBClassifier(booster='gbtree', # 基分类器,也可以是线性'gblinear'
learning_rate=0.1,
n_estimators=1000, # 树的个数--1000棵树建立xgboost
max_depth=6, # 树的深度
silent=True, # 是否输出中间过程
min_child_weight = 1, # 叶子节点最小权重,值越大,越容易欠拟合
gamma=0., # 惩罚项中叶子结点个数前的参数
max_delta_step=0, # 限制每棵树权重改变的最大步长
subsample=0.8, # 随机选择80%样本建立决策树
colsample_btree=0.8, # 随机选择80%特征建立决策树
objective='multi:softmax', # 指定损失函数,'binary:logistic'
scale_pos_weight=1, # 正样本的权重,当正负样本比例为1:10时,scale_pos_weight=10
random_state=27, # 随机数
reg_alpha=0, # L1 正则
reg_lambda=1) # L2 正则
model_xg.fit(x, y,
sample_weight=None,
eval_set=[(x_train, y_train),(x_test, y_test)],
eval_metric='logloss',
early_stopping_rounds=3,
xgb_model='filename') # 预训练模型
model_xg.load_model('filename') # load model xgboost format
model_xg.predict(x)
model_xg.save_model('') # save model
# 回归
model_xg = XGBRegressor(objective='reg:squarederror',
booster='gbtree', # 基分类器,也可以是线性'gblinear'
learning_rate=0.1,
n_estimators=1000, # 树的个数--1000棵树建立xgboost
max_depth=6, # 树的深度
silent=True, # 是否输出中间过程
min_child_weight=1, # 叶子节点最小权重,值越大,越容易欠拟合
gamma=0., # 惩罚项中叶子结点个数前的参数
max_delta_step=0, # 限制每棵树权重改变的最大步长
subsample=0.8, # 随机选择80%样本建立决策树
colsample_btree=0.8, # 随机选择80%特征建立决策树
scale_pos_weight=1, # 正样本的权重,当正负样本比例为1:10时,scale_pos_weight=10
random_state=27, # 随机数
reg_alpha=0, # L1 正则
reg_lambda=1) # L2 正则六、LightGBM
- 单变梯度算法,保留大量梯度大的样本,对梯度小的样本集进行随机抽样,并在计算增益时增加其权重。
- 利用直方图算法对连续特征离散化K箱,提高计算速度(时间复杂度O(k*dimensions)),降低内存占用。xgboost能找到最优分裂点,但直方图算法找到粗糙分裂点,精度降低,方差降低。
- xgboost是level-wise基于层建树,直到停止条件,LightGBM是leaf-wise,每次对增益最大的叶节点分裂,无法并行计算。
- LightGBM利用互斥捆绑降低特征维度,对互斥率小的特征进行合并。
- LightGBM支持类别特征,无需编码,利用many-vs-many分子集。
- LightGBM无需对特征进行预排序存储索引,降低内存占用。














 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









