






【新智元导读】今天分享一篇被今年CVPR接收的论文。该文提出的算法可以高效处理百万量级的点组成的大场景3D点云,同时计算效率高、内存占用少,能直接处理大规模点云,不需要复杂的预处理/后处理,比基于图的方法SPG快了接近200倍,这对自动驾驶和AR非常关键。
牛津大学和国防科技大学合作的一篇题为“RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds”的论文已被今年CVPR接收,今天为大家解读这篇论文。

论文地址:https://arxiv.org/pdf/1911.11236.pdf
TensorFlow代码:https://github.com/QingyongHu/RandLA-Net
本文提出了一种针对大规模三维点云场景的轻量级、高效点云语义分割新算法RandLA-Net。通过对现有的采样策略进行全面综合的分析,本文采用简单高效的随机采样来显著地减少计算量以及内存消耗,并且引入了全新的局部特征聚合模块持续地增大每个点有效的感受野,保留大多数有效的信息。


RandLA-Net能直接处理大规模点云,不需要复杂的预处理/后处理,比基于图的方法SPG快了接近200倍,有助于解决自动驾驶和AR等领域的核心问题。
高效处理百万量级的点组成的大场景3D点云,比基于图的方法SPG快近200倍
Introduction
实现高效、准确的大场景三维点云语义分割是当前三维场景理解、环境智能感知的关键问题之一。然而,由于深度传感器直接获取的原始点云通常是非规则化 (irregular)、非结构化 (unstructure)并且无序 (orderless)的,目前广泛使用的卷积神经网络并不能直接应用于这类数据。
Motivation
自从2017年能够直接在非规则点云上进行处理的PointNet [1] 被提出以来,越来越多的研究者开始尝试提出能够直接处理非规则点云的网络结构,出现了许多诸如PointNet++ [2], PointCNN [3], PointConv [4] 等一系列具有代表性的工作。尽管这些方法在三维目标识别和语义分割等任务上都取得了很好的效果,但大多数方法依然还局限于在非常小(small-scale)的点云上(e.g., PointNet, PointNet++, Pointconv等一系列方法在处理S3DIS数据集时都需要先将点云切成一个个1m×1m的小点云块, 然后在每个点云块中采样得到4096个点输入网络)。这种预处理方式虽然说方便了后续的网络训练和测试,但同时也存在着一定的问题。举例来说,将整个场景切成非常小的点云块是否会损失整体的几何结构?用一个个小点云块训练出来的网络是否能够有效地学习到空间中的几何结构呢?
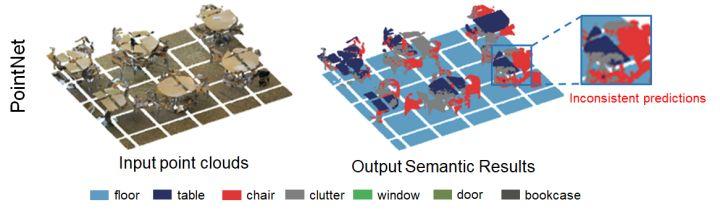
图 1. PointNet在Area 5中的分割结果
带着这样的疑问,我们对PointNet在S3DIS数据集Area 5上的分割结果进行了可视化。如上图highlight的区域所示,PointNet错误地将一张桌子的左半部分识别为桌子,而将右半部分识别为椅子。造成这样明显不一致结果的原因是什么呢?可以看到,这张桌子在预处理切块(左图)的时候就已经被切分成几个小的点云块,而后再分别不相关地地输入到网络中。也就是说,在点云目标几何结构已经被切块所破坏的前提下,网络是难以有效地学习到桌子的整体几何结构的。
既然切块太小会导致整几何结构被破坏,那我能不能把块切大一点?这样不就可以在一定程度上更好地保留原始点云的信息了吗?
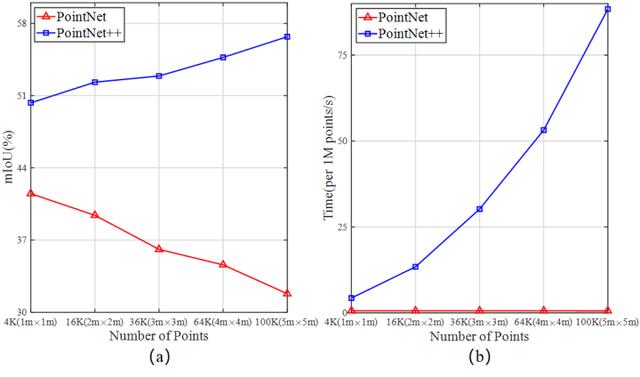
图 2. PointNet和PointNet++在S3DIS Area5的对比实验结果。S3DIS中的数据分别被切割为1m×1m到5m×5m的点云块,然后再输入到网络中进行训练和测试。
对此,我们也进一步设计了对比实验,把切块的尺寸从最初的1m×1m增加到5m×5m(每个block中的点数也相应地从4096增加至102400),得到的实验结果如上图所示,可以看到:
- PointNet的mIoU结果出现了比较明显的下降。我们分析这主要是由于在PointNet框架中,每个点的特征是由shared MLP提取的per-point feature以及global max-pooling提取的global feature组成。当输入点云的规模越来越大时,通过简单的global max-pooling得到的全局特征能发挥的作用就越来越小,进而导致分割性能随着block size增大而持续地下降
- PointNet++的分割性能随着block_size的增大有了一定提升,这是符合我们预期的。然而,从右边的时间变化曲线我们也可以进一步看到,网络inference的时间也随着block_size增大而出现了显著的增长,从最开始的每3s/百万点增加到需要接近100s/百万点。
上述实验结果表明:简单地增大block_size也并不能有效地解决这个问题。通过进一步分析我们发现,阻碍当前大多数方法直接处理大场景点云的原因主要有以下三点:
- 网络的降采样策略。现有的大多数算法采用的降采样策略要么计算代价比较昂贵,要么内存占用大。比如说,目前广泛采用的最远点采样(farthest-point sampling)需要花费超过200秒的时间来将100万个点组成的点云降采样到原始规模的10%。
- 许多方法的特征学习模块依赖于计算代价高的kernelisation或graph construction。
- 现有大多数方法在提取特征时感受野(receptive fields)比较有限,难以高效准确地学习到大场景点云中复杂的几何结构信息
当然,最近也有一些工作已经开始尝试去直接处理大规模点云。比如说SPG用超图(super graph)和超点(superpoints)来表征大场景点云,FCPN和PCT等方法结合了voxel和point的优势来处理大规模点云。尽管这些方法也达到了不错的分割效果,但大多数方法的预处理计算量太大或内存占用高,难以在实际应用中部署。
本文的目标是设计一种轻量级,计算效率高(computationally-efficient)、内存占用少(memory-efficient)的网络结构,并且能够直接处理大规模3D点云,而不需要诸如voxelization/block partition/graph construction等预处理/后处理操作。然而,这个任务非常具有挑战性,因为这种网络结构需要:
- 一种内存和计算效率高的采样方法,以实现对大规模点云持续地降采样,确保网络能够适应当前GPU内存及计算能力的限制;
- 一种有效的局部特征学习模块,通过逐步增加每个点的感受野的方式来学习和感知复杂的几何空间结构。
基于这样的目标,我们提出了一种基于简单高效的随机降采样和局部特征聚合的网络结构(RandLA-Net)。该方法不仅在诸如Semantic3D和SemanticKITTI等大场景点云分割数据集上取得了非常好的效果,并且具有非常高的效率(e.g. 比基于图的方法SPG快了接近200倍)。本文的主要贡献包括以下三点:
- 我们对现有的降采样方法进行了分析和比较,认为随机降采样是一种适合大规模点云高效学习的方法
- 我们提出一种有效的局部特征聚合模块,通过逐步增加每个点的感受野来更好地学习和保留大场景点云中复杂的几何结构
- RandLA-Net在多个大场景点云的数据集上都展现出了非常好的效果以及非常优异的内存效率以及计算效率
随机采样&局部特征聚合模块组合,组建RandLA-Net
Overview
如下图所示,对于一个覆盖数百米范围、由百万量级的点组成的大场景点云而言,如果希望将其直接输入到深度神经网络中进行处理,那么持续有效地对点云进行逐步地降采样,同时尽可能地保留有用的几何结构信息是非常有必要的。
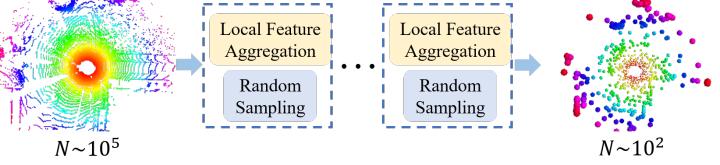
图 3. 网络结构的大致流程图
The quest for efficient sampling
为了寻找到一种高效的降采样方法。我们首先对现有的的降采样方法进行研究:主要可以分为Heuristic Sampling以及Learning-based Sampling两大类:
(1) Heuristic Sampling
- Farthest Point Sampling (FPS):顾名思义,也就是每次采样的时候都选择离之前采样得到的 k-1个点距离最远的点。FPS能够比较好地保证采样后的点具有较好的覆盖率,因而在点云分割领域被广泛地使用(e.g., PointNet++, PointCNN, PointConv, PointWeb)。然而,FPS的计算复杂度是 ,计算量与输入点云的点数呈平方相关。这表明从FPS可能不适合用来处理大规模点云。举例来说,当输入一个具有百万量级点的大场景点云时,使用FPS将其降采样到原始规模的10%需要多达200秒。
- Inverse Density Importance Sampling (IDIS): 这个也比较好理解,简而言之就是根据每个点的密度来对其重新进行排序,尽可能地保留密度比较低的地方的点。IDIS [5] 的计算复杂度近似为 (取决于如何计算每个点的密度)。相比于FPS, IDIS显然更加高效,但IDIS对噪点(outliers)也更加敏感。
- Random Sampling (RS): 随机降采样均匀地从输入的 N 个点中选择 K 个点,每个点具有相同的被选中的概率。RS的计算复杂度为 , 其计算量与输入点云的总点数无关,只与降采样后的点数 K 有关,也即常数时间复杂度。因而具有非常高的效率以及良好的可扩展性。与FPS和IDIS相比,RS仅需0.004s即可完成与FPS相同的降采样任务。
(2) Learning-based Sampling
- Generator-based Sampling (GS):与传统降采样方法不一样,这类方法通过学习生成一个子集来近似表征原始的点云。GS [6,7] 是一种task-oriented, data-driven的learnable的降采样方法,但问题在于inference阶段需要将生成的子集与原始点云进行匹配,这一步依赖于FPS matching,进而引入了更多额外的计算。使用GS将百万量级点的大场景点云降采样到原始规模的10%需要多达1200秒。
- Continuous Relaxation based Sampling (CRS): CRS [8,9] 使用reparameterization trick来将non-differentiable的降采样操作松弛(relax)到连续域使得端到端训练变成可能。CRS采样后得到的每个采样点其实都是整个点云的一个加权和(weighted sum)。具体来说,对于一个大场景的输入点云(size: N×3),CRS通过学习得到一个采样矩阵 (size: K × N) (最终会非常稀疏), 最后采样矩阵左乘输入点云即可实现降采样。然而,当 N 是一个非常大的值时(e.g. 10^6), 这种方式学习到的采样矩阵会带来非常大的内存消耗。举例来说,使用CRS将百万量级点的大场景点云降采样到原始规模的10%需要多达300GB的GPU内存。
- Policy Gradient based Sampling (PGS): PGS [10] 将降采样操作表示为一个马尔科夫决策过程,旨在学习到一种有效的降采样策略。该方法序贯地对每一个点学习到一个概率来决定是否保留。然而,当输入是大场景点云时,整个网络有着极大的搜索空间(exploration space)。举例来说,完成与上述采样方法相同的任务的搜索空间是 。通过进一步地实验我们发现,将PGS应用到大型点云时,网络非常难以收敛。
总结一下:
对于大场景点云,FPS, IDIS和GS的计算代价都比较高, CRS对GPU内存的要求太高,而PGS难以学到一个有效的采样策略(sampling policy)。相比之下,随机采样具有以下两个优点:1)计算效率高, 因为是常数计算复杂度, 与输入点数无关 2)内存开销少,采样过程并不需要额外的内存消耗。因此,对于大场景点云作为输入的情况,我们何不尝试下随机降采样呢?
但新的问题又来了:随机地对点云进行降采样势必会导致有用的信息被丢失,如何克服这个问题?
Local Feature Aggregation
为了缓解这个问题,我们进一步提出了与随机采样互补的局部特征聚合模块(Local feature aggregation)。如图所示,该模块主要包括三个子模块:1)局部空间编码(LocSE), 2) attentive pooling, 3)扩张残差块(dilated residual block)。
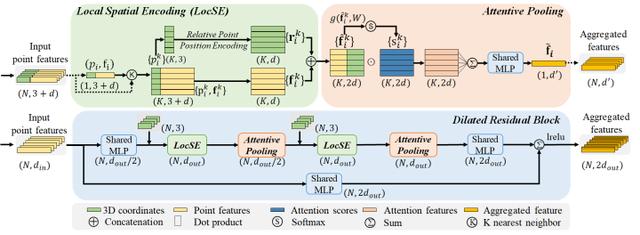
图 4. 局部特征聚合模块。包括局部空间编码(Local Spatial Encoding),Attentive Pooling以及Dilated Residual Block三个子模块。
(1) 局部空间编码(Local Spatial Encoding)
此模块用于显式地对输入的点云的三维坐标信息进行编码。不同于直接将各个点的三维坐标作为一个普通的通道特征输入到网络中,LocSE模块旨在显式地去编码三维点云的空间几何形状信息,从而使得网络能够从各个点的相对位置以及距离信息中更好地学习到空间的几何结构。具体来说分为以下步骤:
- 首先,我们用 最近邻搜索算法为每一个点 找到欧氏空间中最近的个邻域点
- 对于 的个最近邻点 , 我们显式地对点的相对位置进行编码,将中心点的三维坐标 , 邻域点的三维坐标 , 相对坐标 以及欧式距离 连接(concatenation)到一起。如下所示:
- 最后我们将邻域点 对应的点特征 与编码后的相对点位置 连接到一起,得到新的点特征 。
在Semantic3D,S3DIS以及SemanticKITTI等多个数据集上实验:优势明显
Experiments
(1) Efficiency of Random Sampling
首先我们对上述提到的采样策略进行评估,主要从计算时间和GPU内存消耗两个方面来考量。具体来说,我们进行如下的实验:仿照PointNet++的主体框架,我们持续地对点云进行降采样,总共五次降采样,每次采样仅保留原始点云中25%的点。实验结果如下图所示,可以看出:
- 对于小规模的点云~10^3, 上述采样方法在计算时间和内存消耗的差距并不明显, 总体来说都是可接受的
- 对于大规模点云~10^6, FPS/IDIS/GS所需要的计算时间显著增加, 而CRS需要占用大量的GPU内存(图b虚线)。
- 相比之下,RS在计算时间和内存消耗方面都有着显著的优势,因此非常适合处理大规模点云。这个结果也进一步说明了为什么大多数算法选择在小规模点云上进行处理和优化,主要是因为它们依赖于昂贵的采样方法。
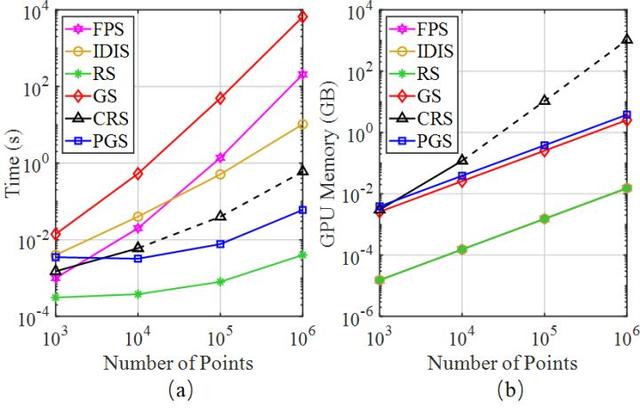
图 7. 不同采样方法的时间和内存消耗。虚线表示由于GPU内存有限而产生的估计值
(2) Efficiency of RandLA-Net
我们进一步对RandLA-Net在处理真实场景中的大规模三维点云的效率进行评估。具体来说,我们选择在SemanticKITTI数据集的验证集(序列8:一共4071帧)进行对比测试。主要评估以下三个方面的指标:总时间,模型参数以及网络最多可处理点数。公平起见,我们在每一帧中将相同数量的点(81920)输入到baseline以及我们RandLA-Net中。实验结果如下表所示,可以看出:
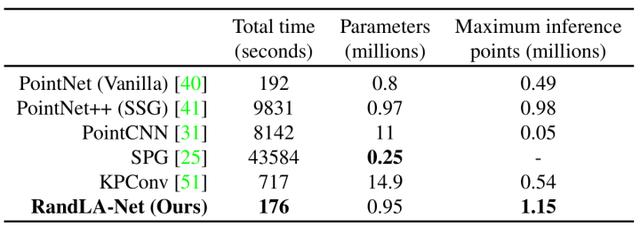
表1. 不同方法在处理SemanticKITTI数据集的序列8的总时间、模型参数和最多可处理点数对比。
- SPG[23]的模型参数最少,但耗时最长。主要原因是几何划分(geometrical partitioning)和超图构建(super-graph construction)等步骤的计算代价较高;
- PointNet++和PointCNN的耗时也很长,主要原因是FPS在处理大场景点云时比较耗时
- PointNet和KPConv无法一次性处理非常大规模的点云 ,主要原因是没有降采样操作(PointNet)或者模型较为复杂。
- 得益于简单的随机采样以及基于MLP的高效的局部特征聚合模块,RandLA-Net的耗时最少(~23帧/每秒),并且能够一次处理总数高达10^6的点云。
(3) 公共数据集评估结果
Semantic3D由30个大规模的户外场景点云组成,包含真实三维空间中160×240×30米的场景,总量高达40亿个点。其中每个点包含3D坐标、RGB信息以及强度信息。RandLA-Net只用了三维坐标以及对应的颜色信息进行处理。从表中可以看出我们的方法达到了非常好的效果,相比于SPG, KPConv等方法都有较明显的提升。
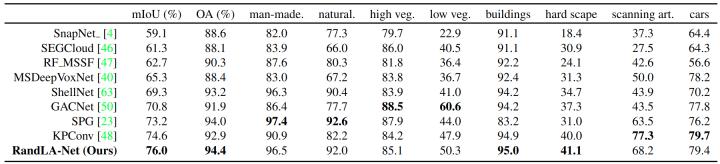
表 2. 不同方法对Semantic3D (reduced-8)的定量结果对比
SemanticKITTI数据集由21个序列, 43552帧点云组成。每一帧的点云由~10^5个点组成,包含真实三维空间中160×160×20 米的场景。我们按照官方的train-validation-test进行分类,其中序列00~07以及09~10(19130帧)作为训练集,序列08(4071帧)作为验证集,序列11~21(20351帧)用于在线测试。需要注意的是,这个数据集中的点云仅包含各个点的三维坐标,而没有相应的颜色信息。实验结果如下表所示,可以看出:RandLA-Net相比于基于点的方法(表格上半部分)有着显著的提升,同时也优于大部分基于投影的方法,并且在模型参数方面相比于DarKNet53Seg等有着比较明显的优势。
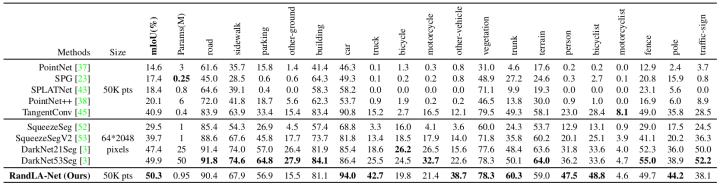
表 3. 不同方法对SemanticKITTI数据集的定量结果对比
S3DIS数据集由6个区域的271个房间组成。每个点云包含真实三维空间中20×15×5米的室内场景。6-fold的交叉验证实验结果也进一步证实了我们方法的有效性。
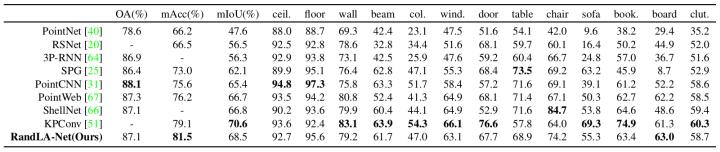
表4. 不同方法对S3DIS数据集的定量结果对比
在Ablation study中,我们也进一步证实了各个子模块对整体性能的贡献。详细的分析见paper以及supplementary。

表 5. Ablation study结果对比
最后总结一下,我们提出了一种针对大规模三维点云场景的轻量级、高效点云语义分割算法,与当前的大多数基于FPS等计算代价高的采样策略的算法不同,本文尝试使用简单高效的随机采样来显著地减少计算量以及内存消耗,并且引入了局部特征聚合模块持续地增大每个点有效的感受野,以确保大多数有效的信息不会因为随机采样而丢失。在Semantic3D,S3DIS以及SemanticKITTI等多个数据集上的大量实验证明了我们的方法的有效性。下一步可以尝试将我们的工作延申到大场景三维点云实例分割以及实时动态点云处理。
最后的话
- 对于三维点云语义分割任务而言,与其在被切割的点云上提出非常复杂的算法来提升性能,不如直接尝试在大场景点云上进行处理,这样更加有实际意义。
- 三维点云分割网络的scalability也是实际应用中一个比较重要的点。i.e., 理想情况下train好的网络应该可以用于inference任意点数的输入点云,因为每个时刻采集到的点云的点数不一定是相同的。这也是RandLA-Net没有使用全局特征的原因,i.e. 确保学到的参数是agnostic to number of points.
- 顺便打一波广告,对于刚刚进入三维点云处理领域的同学,有一份最新的综述论文(Deep Learning for 3D Point Clouds: A Survey)可供参考,内含大量主流的点云目标分类,三维目标检测,三位场景分割算法的最新研究进展及总结。
牛津大学出品,作者团队介绍
论文合著者包括牛津大学博士生胡庆拥,杨波,谢林海,王智华;博士后Stefano Rosa;国防科技大学副教授郭玉兰;以及牛津大学教授Niki Trigoni和Andrew Markham。

胡庆拥

杨波
其中论文一作胡庆拥研究方向是3D视觉和机器学习,专注于大规模3D点云分割和理解,动态点云处理和跟踪。论文二作(通讯作者)杨波专注于让智能机器从2D图片或3D点云中理解和重构完整3D场景。更多信息见个人主页:
https://qingyonghu.github.io
https://yang7879.github.io
Reference
[1] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. CVPR, 2017.
[2] Charles R Qi, Li Yi, Hao Su, and Leonidas J Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space. NeurIPS, 2017
[3] Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. PointCNN: Convolution on X-transformed points. NeurIPS, 2018.
[4] Wenxuan Wu, Zhongang Qi, and Li Fuxin. PointConv: Deep convolutional networks on 3D point clouds. CVPR, 2018.
[5] Fabian Groh, Patrick Wieschollek, and Hendrik P. A. Lensch.Flex-convolution (million-scale point-cloud learning beyond grid-worlds). ACCV, 2018
[6] Oren Dovrat, Itai Lang, and Shai Avidan. Learning to sample. CVPR, 2019.
[7] Itai Lang, Asaf Manor, and Shai Avidan. SampleNet: Differentiable Point Cloud Sampling. arXiv preprint arXiv:1912.03663 (2019).
[8] Abubakar Abid, Muhammad Fatih Balin, and James Zou. Concrete autoencoders for differentiable feature selection and reconstruction. ICML, 2019
[9] Jiancheng Yang, Qiang Zhang, Bingbing Ni, Linguo Li, Jinxian Liu, Mengdie Zhou, and Qi Tian. Modeling point clouds with self-attention and Gumbel subset sampling. CVPR, 2019.
[10] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. ICML, 2015
[11] Hugues Thomas, Charles R Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ̧ois Goulette, and Leonidas J Guibas. Kpconv: Flexible and deformable convolution for point clouds. ICCV, 2019.















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









