





在下载电视剧的时候发现,一个一个下载太麻烦了。这不符合程序员的习惯。我的口号是“能拿程序完成的,绝不用人工完成”。今天和大家谈python爬网的小程序,希望给大家带来一些便利。一方面python非常容易上手,爬网又是一个景点的使用场景, 这个代码不但可以用来爬视频,略加修改我们以爬各种数据,例如图片,商品信息等,看看小伙伴你是不是可以举一反三,学到悟到。
分析需求:
一键下载,全部自动完成,无需人工干预
大体规划:
准备采用python语言完成
代码不超过30行,准备搞定此事
项目实施:
1. 装好迅雷软件
2. 准备开发环境
python 2.7
3.开发工具:pyCharm 2019.3
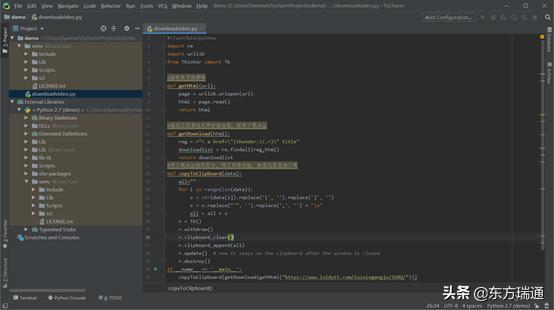
4. 开始编码
a) 第一段依赖库导入
re是正则表达式的库,urllib是url操作模块,Tk是剪贴板

b) 第二段获取网页的源码

c) 第三段通过正则表达式的分组功能,开始获取电视剧下载的URL地址,绿色部分可根据网站URL的结构进行正则表达式的调整

d) 将下载地址组织好后,拷贝到剪切板,并触发迅雷的下载
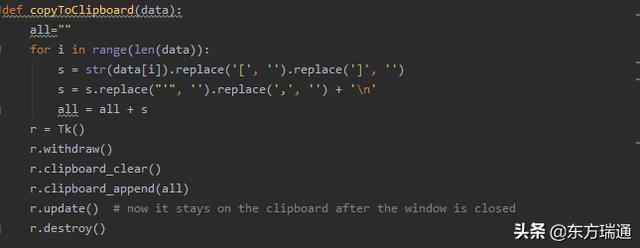
e) 一个main方法,作为调用程序的入口点,绿色部分可改为你想下载视频的网站页面地址

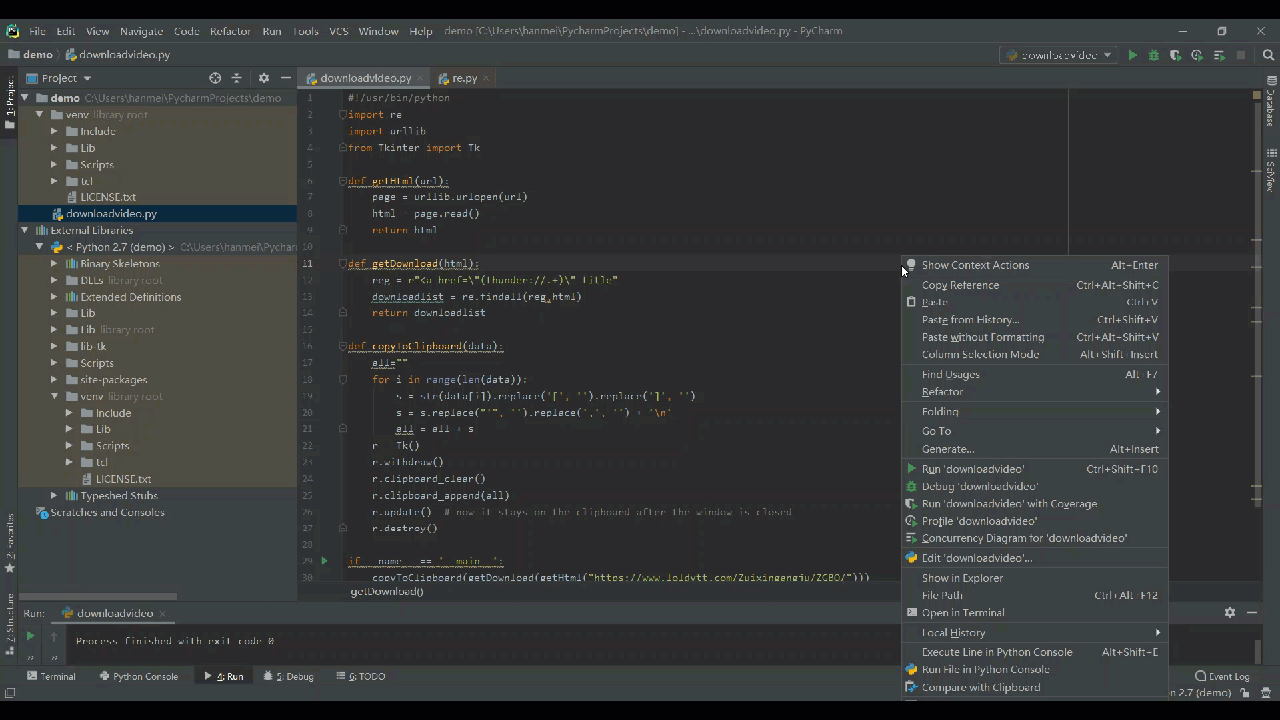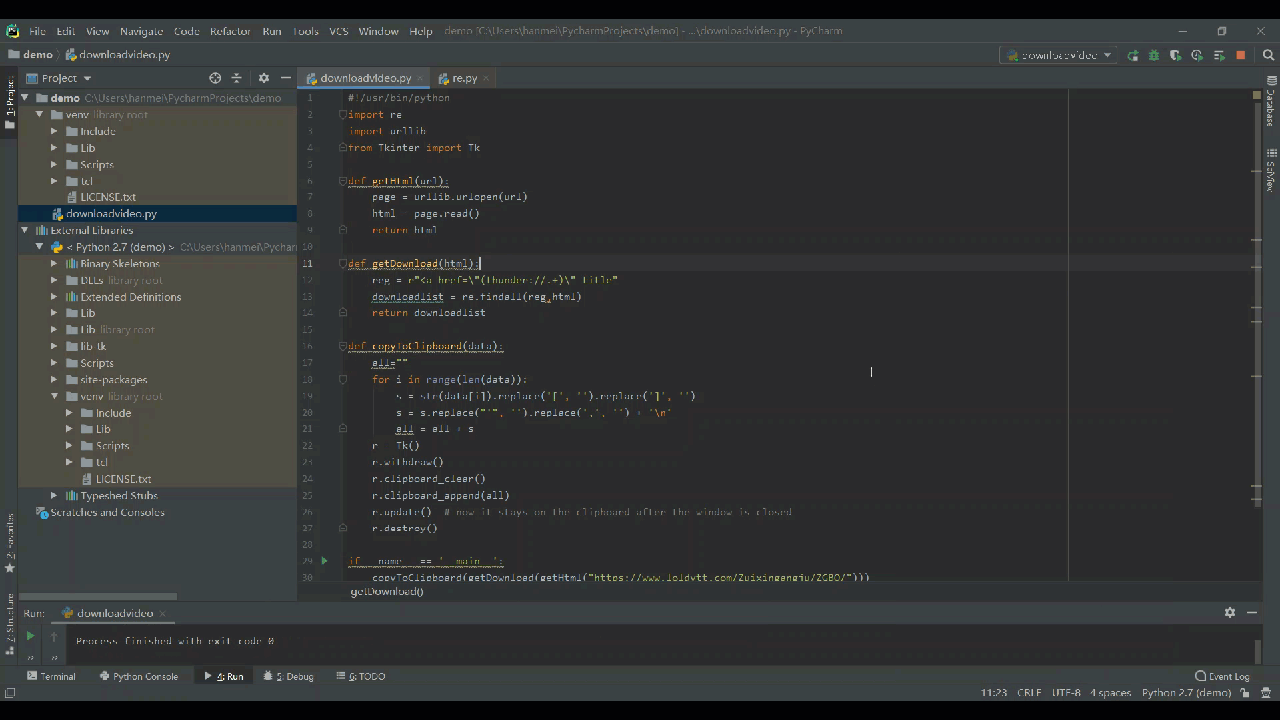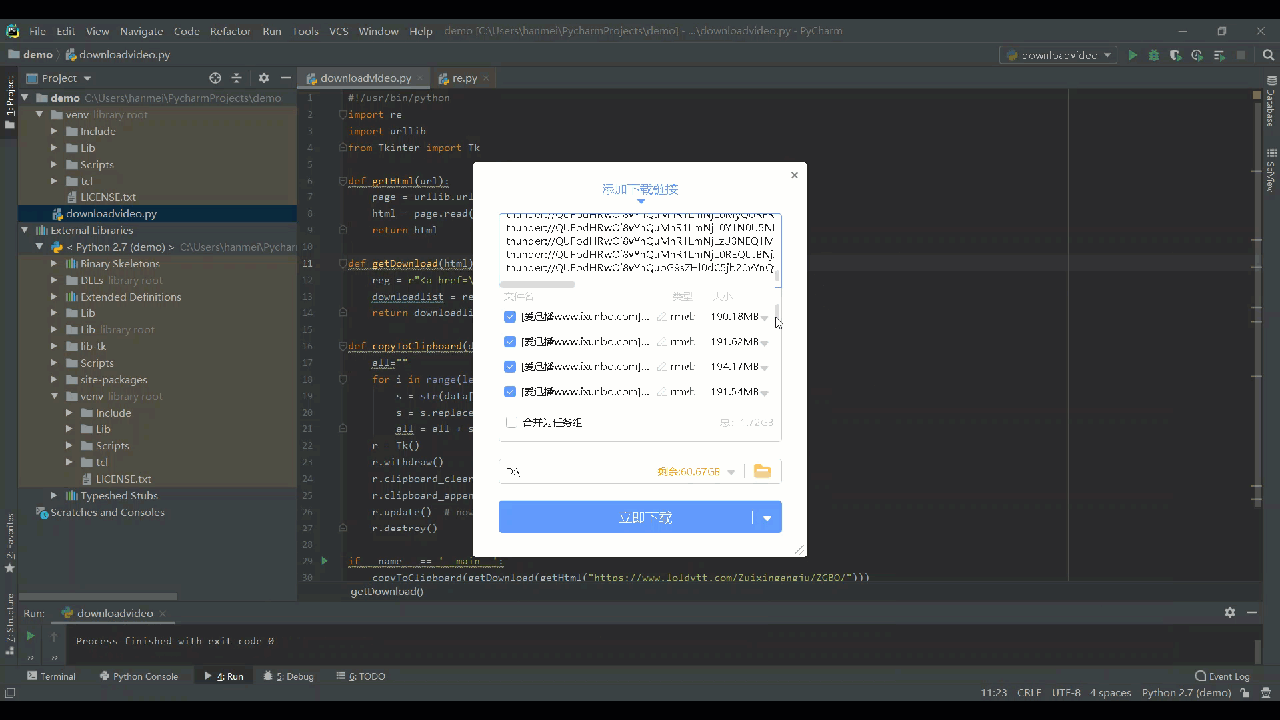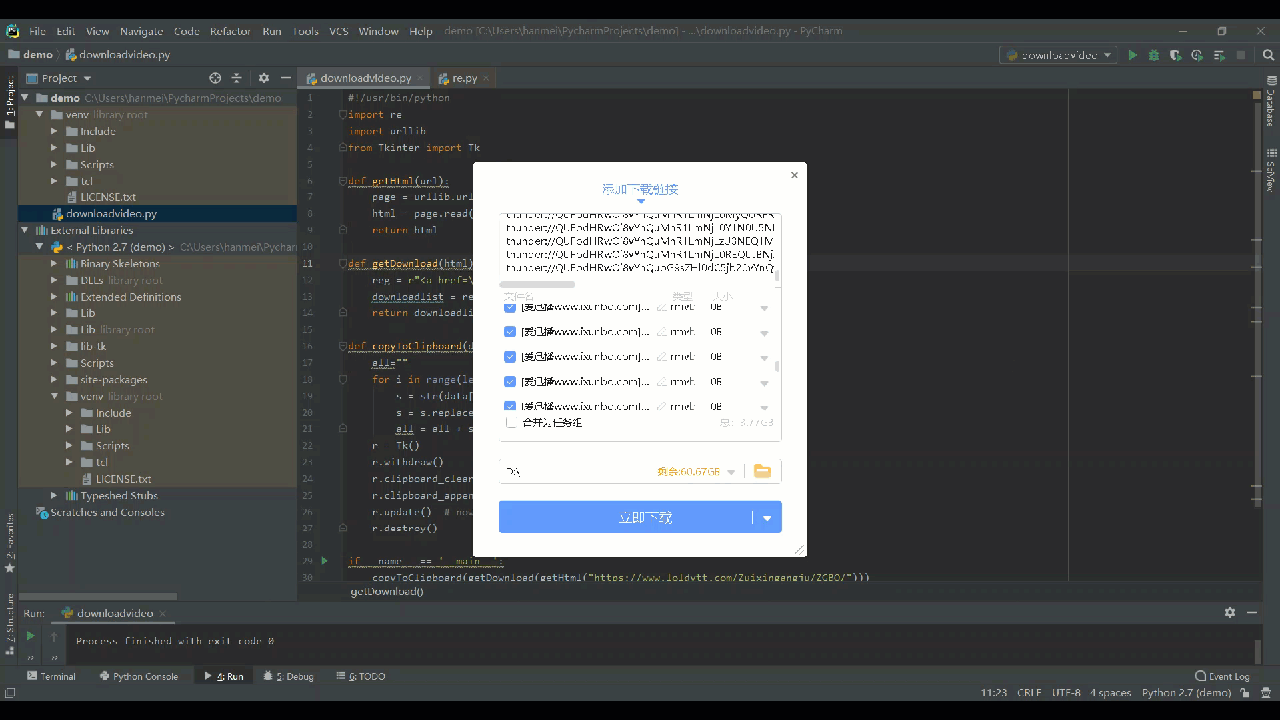
现在只需要run起来,就直接跳出迅雷下载了,所有的下载地址我们已经都爬到了。点击“立即下载”就OK了。
现在只需要run起来,就直接跳出迅雷下载了,所有的下载地址我们已经都爬到了。点击“立即下载”就OK了。
总结:
1. python非常容易上手
2. 爬网是一个经典的使用场景
3. 这个代码不但可以用来爬视频,略加修改我们以爬各种数据,例如图片,商品信息等,总之大有用处
最后附上完整代码,练习的时候如果有问题,欢迎在评论区告诉我,我随时在线答疑。
想更详细了解python爬虫技术的同学,可以移步Python爬虫技术实战案例观看视频教程,了解如何在各类网站提取数据。
#!/usr/bin/python import re import urllib from Tkinter import Tk def getHtml(url): page = urllib.urlopen(url) html = page.read() return html def getDownload(html): reg = r"本文为东方瑞通韩梅老师原创,请勿转载。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









