





伪代码举例解析互联网项目中Redis使用场景及Demo案例
一、背景
互联网项目中使用Redis是比较常见的,既可以作为分布式缓存、又可以作为数据库,还可以用作MQ消息队列。因此,有必要对Redis使用场景作为一番说明,用伪代码的形式举例剖析。
二、分布式缓存
应用场景:用户登录或注册时的验证码存储,用户名
伪代码:set Code:1:code 2432 EX 1000 NX
设置完成后
get Code:1:code
返回Result:2432
另一个示例:set User:1:name dashan EX 100 NX
获取值:get User:1:name
返回结果:dashan
缓存是 redis 出镜率最高的一种使用场景,仅仅使用 set/get 就可以实现,不过也有一些需要考虑的点
(1)如何更好的设置缓存
(2)如何保持缓存与上游数据的一致性
(3)如何解决缓存雪崩,缓存击穿问题
三、MQ消息队列
伪代码:lpush UserNameQueue 1 2 3 4
lpop UserNameQueue
rpop UserNameQueue
结果:1
rpop UserNameQueue
结果:2
可以把redis的队列看为分布式队列,作为消息队列时,生产者在一头塞入数据。消费者另一条取出数据:(lpush/rpop,rpush/lpop),不过也有一些不足,而这些不足有可能是致命的,不过对于一些丢几条消息也没关系的场景还是可以考虑的
1、没有ack(消息确认机制),有可能丢消息
2、需要做redis的持久化配置
四、过滤器filter
伪代码:
sadd UrlSet http://1
(integer) 1
sadd UrlSet http://2
(integer) 1
sadd UrlSet http://2
(integer) 0
使用:smembers UrlSet
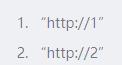
使用了 redis 的 Set 这个数据结构来对将要结果进行去重处理
实例伪代码:
不过当 url 过多时,会有内存占用过大的问题
五、分布式锁应用
分布式锁相信很多人在面试中被面试官问到的概率比较大:
伪代码:
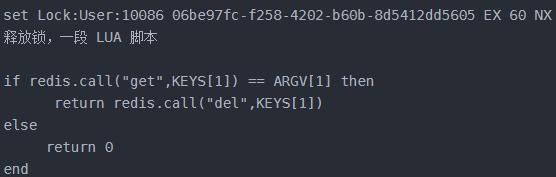
这是一个最简单的单机版的分布式锁,有以下要点
1)EX 表示锁会过期释放
2)NX 保证原子性
解锁时对比资源对应产生的 UUID,避免误解锁
当你使用分布式锁是为了解决一些性能问题,如分布式定时任务防止执行多次 (做好幂等性),而且鉴于单点 redis 挂掉的可能性很小,可以使用这种单机版的分布式锁。
5.1应用实例
比如一个很能干的资深架构师,做事效率很快,代码质量也很高,是团队里的明星。所以呢诸多需求都要来烦他,让他给自己做需求。如果同一时间来了一堆需求都找他,它的思路呢就会陷入混乱,再优秀的程序员,大脑的并发能力也好不到哪里去。所以呢他就在自己的办公室的门把上挂了一个请勿打扰的牌子,当一个需求来的时候先看看门把上有没有这个牌子,如果没有呢就可以进来找架构师谈需求,谈之前要把牌子挂起来,谈完了再把牌子摘了。这样其它需求也要来烦他的时候,如果看见这个牌子挂在那里,就可以选择睡觉等待或者是先去忙别的事。如是这位明星架构师从此获得了安宁。
注意:一定要设置这个过期时间,因为遇到特殊情况 —— 比如地震(进程被 kill -9,或者机器宕机),需求可能会选择从窗户上跳下去,没机会摘牌,导致了死锁饥饿,让这位优秀的架构师成了一位大闲人,造成严重的资源浪费。同时还需要注意这个 owner_id,它代表锁是谁加的 —— 需求的工号。以免你的锁不小心被别人摘掉了。释放锁时要匹配这个 owner_id,匹配成功了才能释放锁。这个 owner_id 通常是一个随机数,存放在 ThreadLocal 变量里(栈变量)。官方其实并不推荐这种方式,因为它在集群模式下会产生锁丢失的问题 —— 在主从发生切换的时候。官方推荐的分布式锁叫 RedLock,作者认为这个算法较为安全,推荐我们使用。不过我们一直还使用上面最简单的分布式锁。为什么我们不去使用 RedLock 呢,因为它的运维成本会高一些,需要 3 台以上独立的 Redis 实例,用起来要繁琐一些。另外,Redis 集群发生主从切换的概率也并不高,即使发生了主从切换出现锁丢失的概率也很低,因为主从切换往往都有一个过程,这个过程的时间通常会超过锁的过期时间,也就不会发生锁的异常丢失。还有呢就是分布式锁遇到锁冲突的机会也不多,这正如一个公司里明星架构师也比较有限一样,总是遇到锁排队那说明结构上需要优化。
六、定时任务解析
分布式定时任务有多种实现方式,最常见的一种是 master-workers 模型。
master 负责管理时间,到点了就将任务消息仍到消息中间件里,然后worker们负责监听这些消息队列来消费消息。
著名的 Python 定时任务框架 Celery 就是这么干的。但是 Celery 有一个问题,那就是 master 是单点的,如果这个 master 挂了,整个定时任务系统就停止工作了。
另一种实现方式是 multi-master 模型。这个模型什么意思呢,就类似于 Java 里面的 Quartz 框架,采用数据库锁来控制任务并发。
会有多个进程,每个进程都会管理时间,时间到了就使用数据库锁来争抢任务执行权,抢到的进程就获得了任务执行的机会,然后就开始执行任务,这样就解决了 master 的单点问题。
这种模型有一个缺点,那就是会造成竞争浪费问题,不过通常大多数业务系统的定时任务并没有那么多,所以这种竞争浪费并不严重。
还有一个问题它依赖于分布式机器时间的一致性,如果多个机器上时间不一致就会造成任务被多次执行,这可以通过增加数据库锁的时间来缓解。
画张图表示:
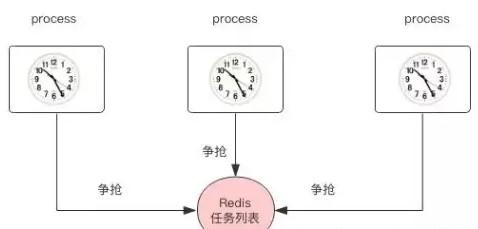
比如说我们有了分布式锁,我们应该能够使用Redis实现定时任务。
七、控制频率
项目中不可避免的总是会遇到垃圾内容,一觉醒来你会发现首页突然会被某些恶意的帖子和广告刷屏了,如果不采取适当的机制来控制就会导致用户体验受到严重的影响
控制广告垃圾贴的策略很多,高级一点的可以通过AI,最简单的方式是通过关键词扫描,还有比较常用的一种方式是频率控制,限制单个用户内容的生产速度,不通等级的用户会有不同的频率控制参数
频率控制就可以使用redis来实现,我们将用户的行为理解为一个时间序列,我们要保证在一定的时间内限制单个用户的时间序列的长度,超过这个长度就禁止用户的行为,它可以是用redis的zset(有序集合,zset详解)来实现
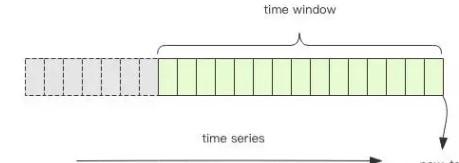
图中绿色的部门就是我们要保留的一个时间段的时间序列信息,灰色的段会被砍掉。统计绿色段中时间序列记录的个数就知道是否超过了频率的阈值。
八、服务发现
如果想要技术成熟度再高一些,有的企业会有服务发现的基础设施。通常我们都会选用zookeeper、etcd,consul等分布式配置数据库来作为服务列表的存储
它们有非常及时的通知机制来通知服务消费者服务列表发生了变更。那我们该如何使用 Redis 来做服务发现呢?
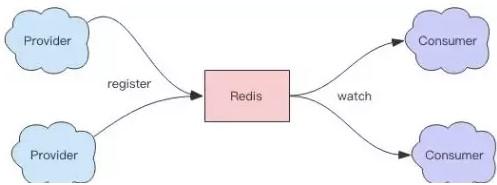
这里我们要再次使用 zset 数据结构,我们使用 zset 来保存单个服务列表。多个服务列表就使用多个 zset 来存储。
zset 的 value 和 score 分别存储服务的地址和心跳的时间。服务提供者需要使用心跳来汇报自己的存活,每隔几秒调用一次 zadd。服务提供者停止服务时,使用 zrem 来移除自己。
伪代码:

这样还不够,因为服务有可能是异常终止,根本没机会执行钩子,所以需要使用一个额外的线程来清理服务列表中的过期项
伪代码:

接下来还有一个重要的问题是如何通知消费者服务列表发生了变更,这里我们同样使用版本号轮询机制,当服务列表变更时,递增版本号。消费者通过轮询版本号的变化来重加载服务列表

如果消费者依赖了很多的服务列表,那么它就需要轮询很多的版本号,这样的IO效率会比较低下。
这个问题待解决后面再讲。
九、位图与签到
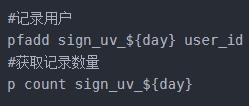
项目里需要做一个工作成员的签到系统,当用户量比较少的时候,设计上比较简单,就是将用户的签到状态用redis的hash结构来存储,签到一次就再hash结构里记录一条,签到有三种状态:未签到,已签到和部签到,分别是0,1,2三个整数值
伪代码:hset sign:$(user_id) 2020-05-21 1
hset sign:$(user_id) 2020-05-21 0
hset sign:$(user_id) 2020-05-21 2
这个其实非常浪费用户空间,后来想做全部用户的签到,高层领导指出,这时候的再用hash就有问题了,他讲到当用户过千万的时候,内存可能会飚到 30G+,我们线上实例通常过了 20G 就开始报警,30G 已经属于严重超标了。
这时候我们就开始着手解决这个问题,去优化存储。我们选择使用位图来记录签到信息,一个签到状态需要两个位来记录,一个月的存储空间只需要 8 个字节。这样就可以使用一个很短的字符串来存储用户一个月的签到记录。
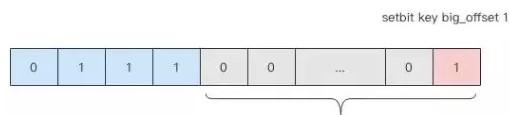
但是位图也有一个缺点,它的底层是字符串,字符串是连续存储空间,位图会自动扩展,比如一个很大的位图 8m 个位,只有最后一个位是 1,其它位都是零,这也会占用1m 的存储空间,这样的浪费非常严重。
所以呢就有了咆哮位图这个数据结构,它对大位图进行了分段存储,全位零的段可以不用存。
另外还对每个段设计了稀疏存储结构,如果这个段上置 1 的位不多,可以只存储它们的偏移量整数。这样位图的存储空间就得到了非常显著的压缩。
十、计数器
上面提到的签到系统,假如需求需要知道这个签到的日活月活怎么办呢?
通常我们会直接甩锅——请找运营部门。
但是运营部门的数据往往不是很实时,经常前一天的数据需要第二天才能跑出来,离线计算是通常是定时的一天一次。那如何实现一个实时的活跃计数?
最简单的方案就是在 Redis 里面维护一个 set 集合,来一个用户,就 sadd 一下,最终集合的大小就是我们需要的 UV 数字。
但是这个空间浪费严重怎么办?这时候就需要使用redis提供的HyperLogLog模糊计数功能,它是一种概率计数,有一定的误差,大约是0.81%。
但是空间占用很小,其底层是一个位图,它最多只会占用12k的存储空间,而且在计数值比较小的时候,位图使用稀疏存储,空间占用就更小了。
伪代码:
十一、回顾
Redis其实还可以进行发布订阅,我后面会举例说明发布订阅模式














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









