





节选自《移动app爬虫攻防实战》第12章
微信的用户发展到现在早已超过10亿了,身边热衷于发朋友圈的数不胜数,甚至已经到了现在很多人被朋友圈的海量的内容骚扰的不行,不停屏蔽这个屏弊那个,但还是离不开它,因为我们的记忆被套在朋友圈里。
笔者曾经在2016年开发了一个导出朋友圈的小功能,可以把好友发表的朋友圈内容导出并全成一个html页面,并且为不少想保存自己朋友圈内容的人提供了导出服务,也认识了不少朋友。
虽然只是一个小小功能,但通过交流才发现:导出来的朋友圈内容转化成朋友圈相册,其实是一个不错的细分市场,甚至发展出好几家创业公司,并持续有一些团队进入及退出,而大家用的技术也基本都是围绕app逆向这个思路来进行的。
12.1 朋友圈的导出
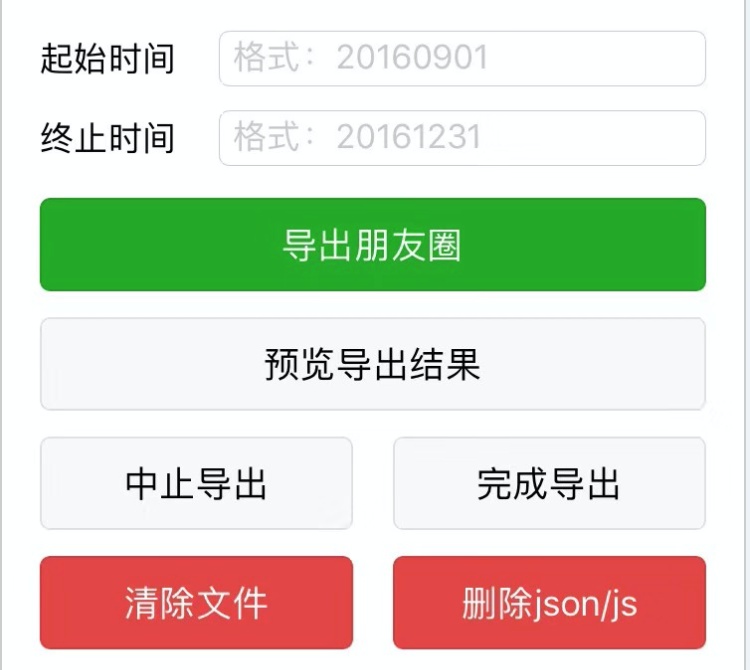
笔者使用了app逆向技术对微信做了对应的分析,从朋友圈内容加载和渲染的入口跟进去,然后就可以寄生在微信客户端上来获取朋友圈的索引数据并且下载图片,其核心要点的流程如图12-1所示:
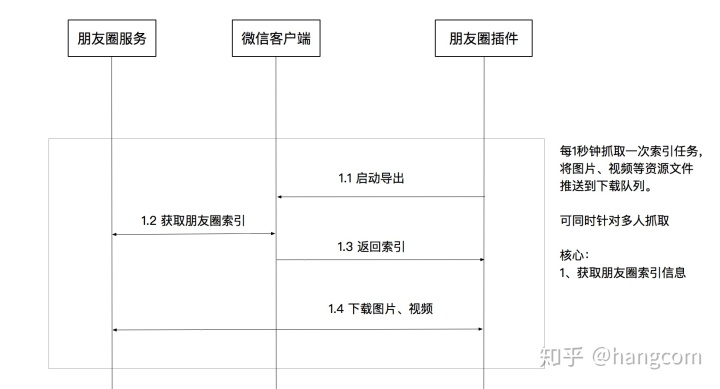
图12-1
有了这个核心流程,再在此基础上扩展工程代码,就可以得到一个完整可用的朋友圈导出的插件,图12-2是对整个流程的一个通俗简介:

图12-2
当代码已经有效地运行之后,就会在微信的个人信息页上多出一个“朋友圈”的按钮,如图12-3,这是早期版本的界面。
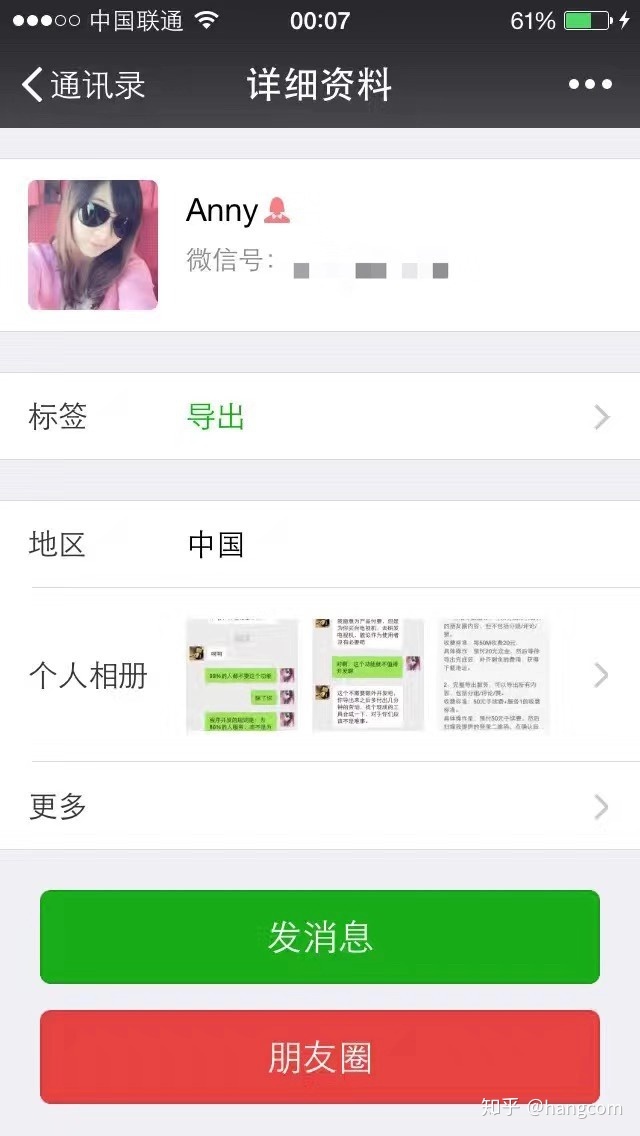
图12-3
点“朋友圈”之后会启动导出过程,会以10条/秒的速度循环加载朋友圈的索引信息,并根据索引信息里的图片、视频的http地址去下载资源文件,索引信息的格式如图12-4:
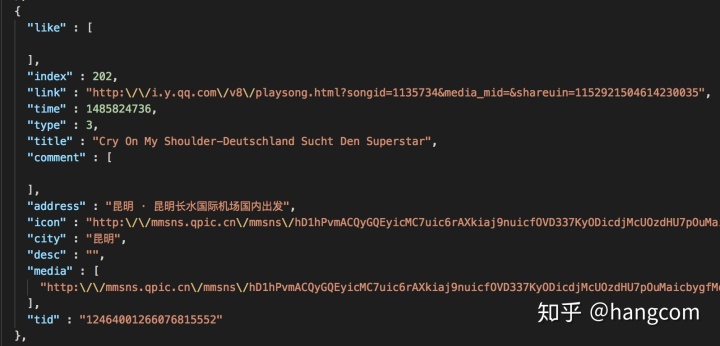
图12-4
根据索引信息合成的html页面效果如图12-5:
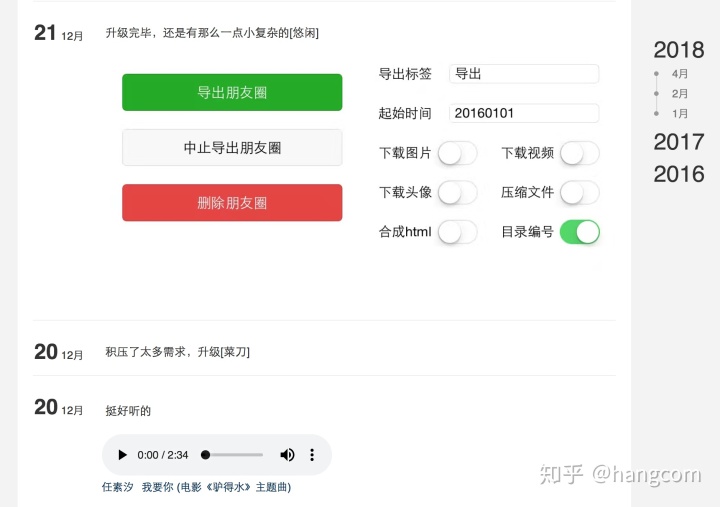
图12-5
看起来挺简单的,整个过程只要突破图12-1所对应的核心技术点,剩下的就是工程量了。第一版的代码量,不包括html页面部分,大概只用了3000行就完成以上的所有功能。
在和一些相关团队交流后发现,有的团队用的方法很粗暴:通过模拟器不停地刷一个人的朋友圈,然后把所有的图片、视频一个个点开下载,再提取缓存中的文件。这样的最大缺点就是速度慢,与笔者这种直接刷原生接口的速度相比几乎慢一个量级,不过只要能解决问题也OK。
12.2 wxpc图片格式
在公开运行了几个月,为不少朋友导出朋友圈记录之后,突然遇到一个意外情况:通过索引信息里的http链接获取图片失败了!
笔者有几个专门服务的微信号,有的微信号仍然可以通过http直接获取图片,有的微信号则不行。通过分析有问题的协议发现索引信息中图片http链接已经无法有效下载图片,再进一步调试发现:微信用了自己的wxpc图片格式,其真实对应的url格式如下:
http://[::ffff:111.12.34.142]/mmsns/KuPATVb3SJXyhekdicVpLrO3RhEtY0ibjEA76v1lHpMRpiaVRYnm83R7OCuvhM3Jp9Nmvyg6jp6IPs/0?tp=wxpc&length=1136&width=640&idx=1&token=WSEN6qDsKwV8A02w3onOGQYfxnkibdqSOkmHhZGNB4DFFicvVGZvFHg08YsLPdlqiagg6oiaGepT0RlJNMh5SQxDbg
即使我们能截取这种url并通过它去获得图片资源文件,拿到的也是wxpc格式而不是常见的jpg格式。我搜索了一圈,这种wxpc文件对微信的最大的价值就是文件尺寸更小、加载速度更快;并且,站在安全的角度理解:还可以防止别人低成本盗用~
顺便说一句,微信早在6.2或者之前就已经加入了对wxpc的支持,但笔者一直到6.3才碰到这个问题,也许是因为当时所用的微信账号导出的内容太多,然后被灰度到了。
不过,哪怕wxpc格式我们无法直接使用,可是它终究也是要变成UIImage对象加载到UI上来显示的,那么,我们就可以盯住wxpc->UIImage这个环节来达到我们的目标。依据这个思路,笔者做了一次大的升级,其核心流程改变可见图12-6。
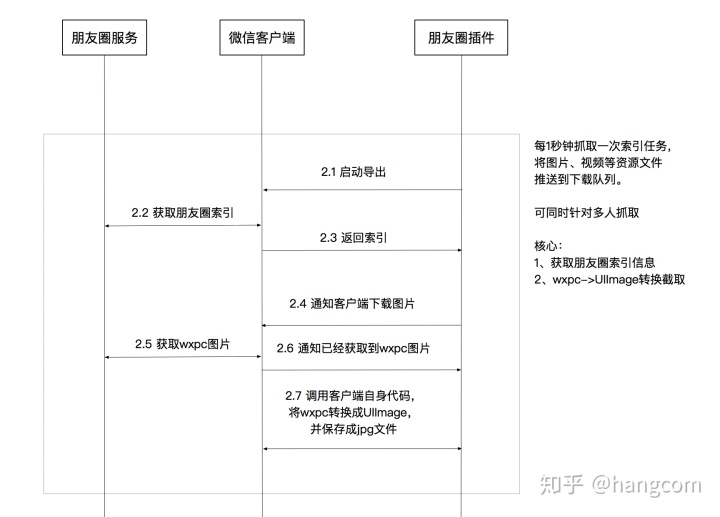
图12-6
当然,实际的开发过程远比这个复杂,这种异步请求的处理、容错等等,整个代码量由3000行增加到5000行。
直到现在,我们所有的操作都是基于微信客户端来完成的,而不像本书前面的章节所说,将协议复制到PC上来提高执行效率,原因很简单:微信的通信协议是自己的私有socket协议,而且层级非常多,远不是普通小app那种拦截了https就万事大吉,我们也投不起那么大的时间成本来做这样的协议迁移。
自从改成完全依赖微信客户端来下载图片,整个过程一下子就拉长了:抓取索引的速度并没有变慢,但是早期的下载可以直接下载http图片,甚至可以在一个app进程中并发多个下载线程;新版本为了容错,只敢一个个地获取wxpc格式,并且还要先转UIImage再转jpg,与多线程下载相比慢了5-10倍,这已经和那些低技术团队的模拟器抓取+下载方式没有质的差距,哪怕技术细节上是更炫一点,但整体相比完全看不出高大上来。
为了改变这个结果,自然就要付出相应的精力。当单机的速度上不去的时候,我们就可以用多机,于是分布式的导出朋友圈设计也就浮出水面了。
12.3 分布式导出
根据提高速度的需求,我们可以做一个简单的分析:
1、抓取索引信息的速度很快,10条/秒,假设有1000条朋友圈记录,100秒就可以完成。
2、下载图片的速度很慢,假设1000条朋友圈记录,平均有1000张图片,每张图片从下载到转换完成的时间是0.5秒,需要500秒才能全部完成。
3、如果仅仅是一个人的朋友圈数据,整个导出过程不到10分钟,倒也无所谓。可是如果有100个人的数据需要导出,对应的时间就是1000分钟,也就是近2小时。如果有1000人,整个过程就拉到了20小时,这还不包括出错导致中断等问题。
4、我们可以把100人的任务分布到10个微信账号,等待时间也会线性下降,但是管理多个客服微信号是一件复杂的事,是否可以有更佳的方式?
5、可以注意到,抓索引信息的速度和下载图片的速度是1:5,也就是说,想要达到最佳平衡的速度,有5倍的下载能力即可让整个计算能力平衡起来。
有了前面章节的分布式设计经验,新的解决方案就可以定型了:
1、根据角色定义,将原本集成在一起的功能角色显式拆解成2部分,并且命名:索引机、下载机。
2、引入任务调度服务,并且下载机将所有获取的图片上传到云端。
3、索引机和下载机的默认配属比例是1:5,但是这个数字不是绝对的,可以在实际运行中根据需要来调高或调低下载能力,每个机器上可以通过开关来切换角色。
对应的框架图可见图12-7:
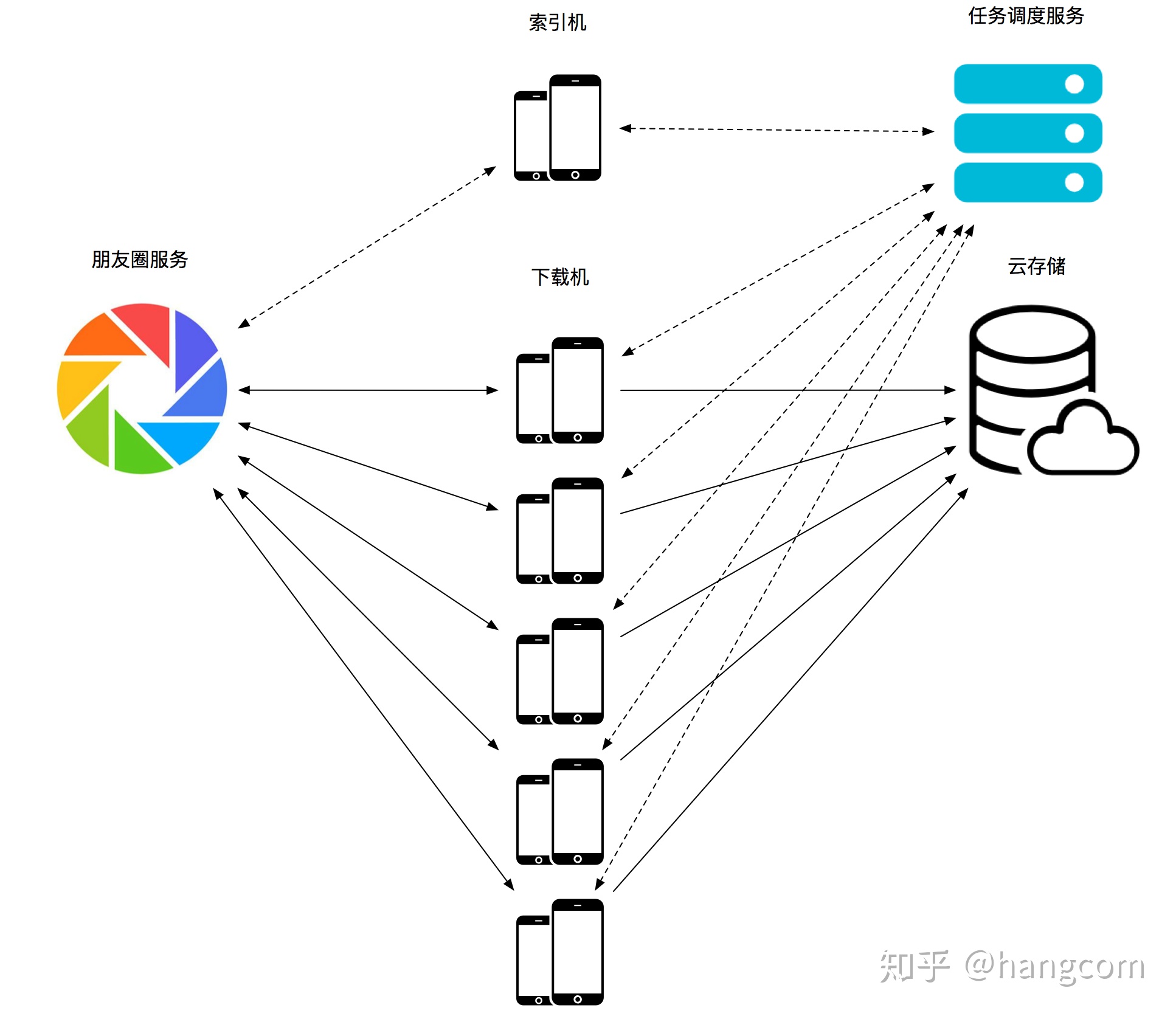
图12-7
和前面章节中描述的几乎一样,不同的只是用了一组移动设备当爬虫机,并且在实际运行过程中可以根据任务量去调整集群的数量和规模,原则上扩大10倍、100倍也没什么问题,前提是有这么大的业务量。
12.4 本章小结
朋友圈导出这个功能首先来源于笔者自己的需求,然后在提供服务的过程中吸收了很多人的需求,从功能到性能,从单机到分布式,整个代码和架构都在不停地变迁,几乎可以与本书前半部分的章节内容都对应上。
可能不少读者会不满:为什么不上代码?
从笔者的角度,授人以鱼,不如授人以渔。怎么分析,怎么实现,在前面的章节、甚至相关联的《iOS应用逆向工程》中都能得到,不自己动手去实践岂不是丧失了乐趣?
最后贴2个代码的图,回顾一下笔者在这个功能上投入的精力。
图12-8,iOS端的导出代码,5000行虽然不是一个大工程,但从插件的角度也不是一个小玩意了,而且集成了众多功能。
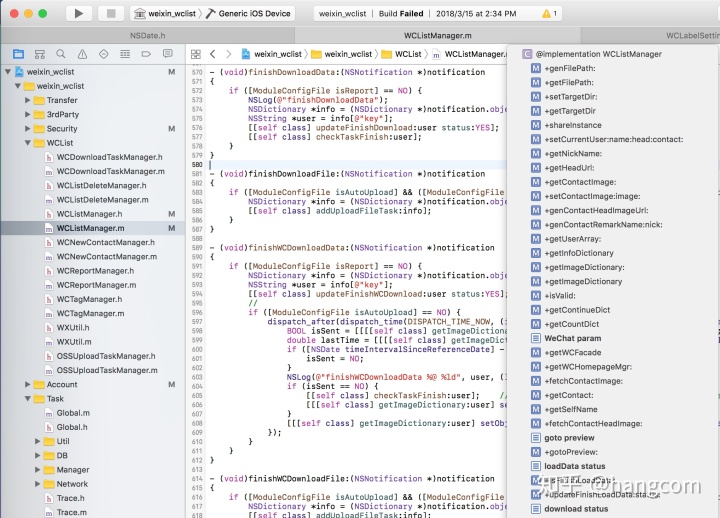
图12-8
图12-9,任务调度服务的关键代码,和前面对应章节里描述的一样,每个下载机都来Fetch各自的任务,完成之后再Fetch下一个,简单高效地工作着。
图12-9
从目前的需求看,朋友圈导出服务的技术架构已经稳定,至于新的升级,可能会在累积了足够多新的需求后才开始。友商们也可以对比自己的架构,有兴趣可以一起交流讨论。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









