







一、hash函数
Hash一般被翻译成散列、杂凑或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列出相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。(介绍来源于百度百科)
Hash函数性质:
- 输入为任意长度字符串,输出为固定长度字符串。
- 输入确定,输出也确定。特定输入对应唯一输出(有可能两个输入对应一个输出——hash碰撞,解决碰撞有链地址法和开发地址法,这里就不展开了,就浅谈一下就好了)
- 随着输入域的增大,输出域均匀增大(这种均匀性越好,hash函数越好)
二、LeetCode中等题
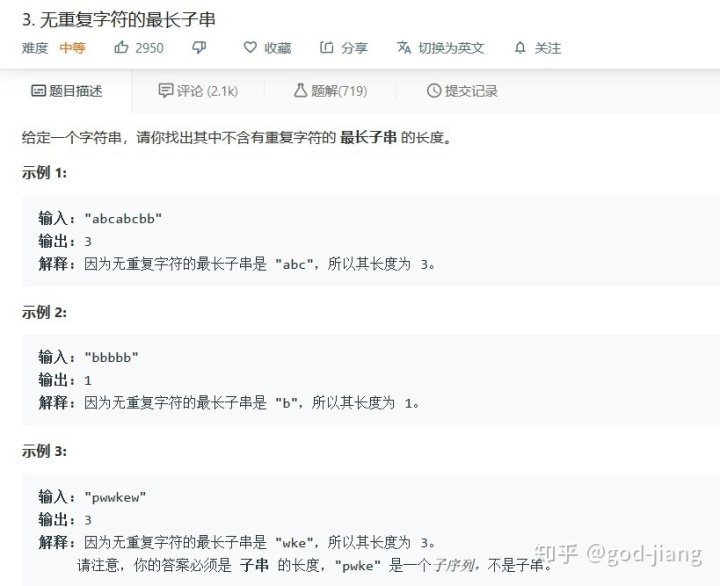
利用HashSet解决:
要检查一个字符是否已经在子字符串中,我们可以检查整个子字符串,这将会产生一个时间复杂度为O(n^2)的算法。使用HashSet可以用O(1)的时间完成对字符串是否在当前子字符串中的检查
public int lengthOfLongestSubstring(String s) {
int n=s.length();
int i=0;
int j=0;
int res=0;
HashSet<Character> set=new HashSet<>();
while(i<n&&j<n){
if(!set.contains(s.charAt(i))){
set.add(s.charAt(i++));
res=Math.max(res,i-j);
}else{
set.remove(s.charAt(j++));
}
}
return res;
}复杂度分析:
- 时间复杂度:O(n),在最坏的情况下,每个字符都会被i和j访问两次
- 空间复杂度:O(min(m,n))
三、设计RandomPool结构
Problem
【题目】
设计一种结构,在该结构中有如下三个功能:
insert(key):将某个key加入到该结构,做到不重复加入。
delete(key):将原本在结构中的某个key移除。
getRandom():等概率随机返回结构中的任何一个key。
【要求】
insert、delete和getRandom方法的时间复杂度都是O(1)
solution
insert:
构造map<key,Integer> keyIndexMap,map<Integer,key> indexKeyMap。当第一个插入o1,就在keyIndexMap.add(o1,1),indexKeyMap.add(1,o1)。
getRandom:
通过数字进行random,得到的就是等概率的。(保证0~Integer是连续的就可以保证等概率)。
delete:
删除后存在空位,这些空位会影响到0~Integer是连续的。解决办法:拿最后一条记录填补空位。
code
/**
* @author god-jiang
* @date 2020/1/4
*/
public class RandomPool {
public static class Pool<K>{
private HashMap<K,Integer> keyIndexMap;
private HashMap<Integer,K> indexKeyMap;
//size记录第几个进来的
private int size;
public Pool(){
keyIndexMap = new HashMap<>();
indexKeyMap = new HashMap<>();
size = 0;
}
//插入操作分别插入到keyIndexMap和indexKeyMap中
public void insert(K key){
if(!keyIndexMap.containsKey(key)){
keyIndexMap.put(key,size);
indexKeyMap.put(size++,key);
}
}
// A 0 0 A
// B 1 1 B
// C 2 2 C
// D 3 3 D
//先确定删除的索引,以及最后面的值,把最后面的值补充到删除的地方
//之后删除开始应该删除的
public void delete(K key){
if(keyIndexMap.containsKey(key)){
int deleteIndex = keyIndexMap.get(key);
int lastIndex = --size;
K lastKey = indexKeyMap.get(lastIndex);
keyIndexMap.put(lastKey,deleteIndex);
indexKeyMap.put(deleteIndex,lastKey);
keyIndexMap.remove(key);
indexKeyMap.remove(lastIndex);
}
}
//等概率从indexKeyMap返回key
public K random(){
if(size==0){
return null;
}
int num = (int) (Math.random()*size);
return indexKeyMap.get(num);
}
}
}
四、布隆过滤器
基础介绍
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询效率到远远超于一般的算法,缺点是有一定的误识别率和删除困难。
操作过程
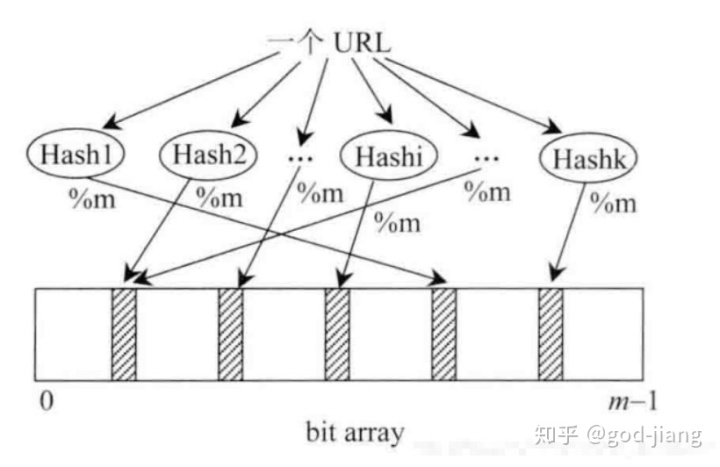
布隆过滤器最重要的实现就是位图的实现,也就是位数组,并且在这个数组中每一个位置只占有一个bit,而每个bit只有0和1两种状态。
假设有k个哈希函数,且每个哈希函数的输出范围都大于m,我们就把输出值对k取余(%m),就会得到k个[0,m-1]的值,由于每个哈希函数之间相互独立,因此这k个数也相互独立,最后将这k个数对应到的bit标记为1(涂黑)
等判断时,将输入对象经过这k个哈希函数计算得到k个值,然后判断对应的bit位是否都为1(涂黑),如果有一个不为黑,那么这个输入对象则不在这个集合中,也就不是黑名单!如果都是黑,说明在集合中,但是有可能有误。
图示
重要参数计算
通过上面的描述,如果输入量过大,而bit空间很小,那么误判率会上升。那么要怎么平衡bit空间呢,已经有大神通过数据推导出公式了~~~
假设输入对象个数为n,bit大小为m,所能容忍的误判率为p和哈希函数的个数为k。计算公式如下(小数向上取整)
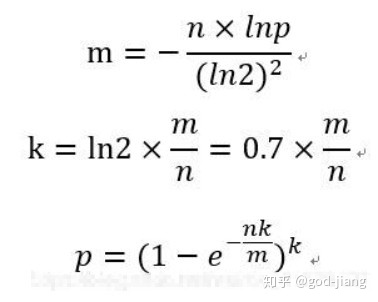
注意:由于我们计算的m和k可能为小数,通过向上取整,此时的误判率会下降
五、总结
其实也只是浅谈一下hash函数以及用LeetCode一道题来讲了它的一点点应用,hash就是用空间来换取时间的一种算法。以上只是讲了一下介绍而已,拓展(RandomPool结构、布隆过滤器等)已经在个人博客里面更新了,有兴趣的可以去看看。god-jiang的git个人博客god-jiang.github.io

这个博客也是可以评论的,欢迎大家来讨论和学习,觉得我写得还可以的可以给给你的star给我的github。当然大多数都是浅谈,毕竟我也还是一名大学生,对学校学习的知识还是停留在知道的层面,还没有实际应用过。
觉得楼主写得还可以点点赞,关注一下,最近在忙毕业设计,有时间尽量更新。















 857
857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









