







查询语言分类
在了解 SQL 之前我们需要知道下面这几个概念
- 数据定义语言: 简称DDL (Data Definition Language),用来定义数据库对象:数据库、表、列等;
- 数据操作语言: 简称DML (Data Manipulation Language),用来对数据库中表的记录进行更新。关键字: select 、insert、update、delete等
- 数据控制语言: 简称DCL(Data Control Language),用来定义数据库访问权限和安全级别,创建用户等。关键字: grant等
DDL 语句
创建数据库
首先要做的就是创建数据库,创建数据库可以直接使用指令
CREATE DATABASE dbname;进行创建,比如我们创建数据库 cxuandb
create database cxuandb;注意最后的 ; 结束语法一定不要丢掉,否则 MySQL 会认为你的命令没有输出完,敲 enter 后会直接换行输出

上图我们成功创建了一个 cxuandb 的数据库,此时我们还想创建一个数据库,我们再执行相同的指令,结果提示

提示我们不能再创建数据库了,数据库已经存在。这时候我就有疑问了,我怎么知道都有哪些数据库呢?别我再想创建一个数据库又告诉我已经存在,这时候可以使用 show databases 命令来查看你的 MySQL 已有的数据库
show databases;执行完成后的结果如下
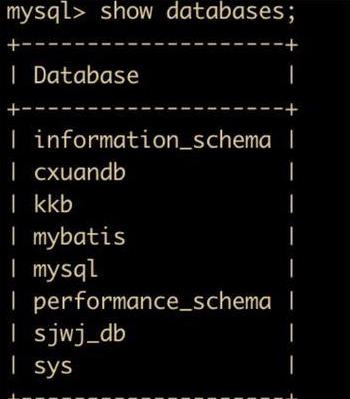
因为数据库我之前已经使用过,这里就需要解释一下,除了刚刚新创建成功的 cxuandb 外,informationn_schema 、performannce_schema 和 sys 都是系统自带的数据库,是安装 MySQL 默认创建的数据库。它们各自表示
- informationn_schema: 主要存储一些数据库对象信息,比如用户表信息、权限信息、分区信息等
- performannce_schema: MySQL 5.5 之后新增加的数据库,主要用于收集数据库服务器性能参数。
- sys: MySQL 5.7 提供的数据库,sys 数据库里面包含了一系列的存储过程、自定义函数以及视图来帮助我们快速的了解系统的元数据信息。
其他所有的数据库都是作者自己创建的,可以忽略他们。
在创建完数据库之后,可以用如下命令选择要操作的数据库
use cxuandb这样就成功切换为了 cxuandb 数据库,我们可以在此数据库下进行建表、查看基本信息等操作。
比如想要看康康我们新建的数据库里面有没有其他表
show tables;果然,我们新建的数据库下面没有任何表,但是现在,我们还不进行建表操作,我们还是先来认识一下数据库层面的命令,也就是其他 DDL 指令
删除数据库
如果一个数据库我们不想要了,那么该怎么办呢?直接删掉数据库不就好了吗?删表语句是
drop database dbname;比如 cxuandb 我们不想要他了,可以通过使用
drop database cxuandb;进行删除,这里我们就不进行演示了,因为 cxuandb 我们后面还会使用。
但是这里注意一点,你删除数据库成功后会出现 0 rows affected,这个可以不用理会,因为在 MySQL 中,drop 语句操作的结果都是 0 rows affected。
创建表
下面我们就可以对表进行操作了,我们刚刚 show tables 发现还没有任何表,所以我们现在进行建表语句
CREATE TABLE 表名称(列名称1 数据类型 约束,列名称2 数据类型 约束,列名称3 数据类型 约束,....)这样就很清楚了吧,列名称就是列的名字,紧跟着列名后面就是数据类型,然后是约束,为什么要这么设计?举个例的你就清楚了,比如 cxuan 刚被生出来就被打印上了标签

比如我们创建一个表,里面有 5 个字段,姓名(name)、性别(sex)、年龄(age)、何时雇佣(hiredate)、薪资待遇(wage),建表语句如下
create table job(name varchar(20), sex varchar(2), age int(2), hiredate date, wage decimal(10,2));事实证明这条建表语句还是没问题的,建表完成后可以使用 DESC tablename 查看表的基本信息
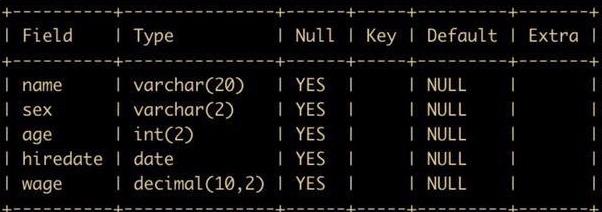
DESC 命令会查看表的定义,但是输出的信息还不够全面,所以,如果想要查看更全的信息,还要通过查看表的创建语句的 SQL 来得到
show create table job G;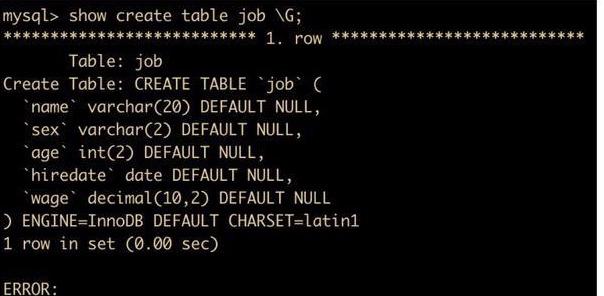
可以看到,除了看到表定义之外,还看到了表的 engine(存储引擎) 为 InnoDB 存储引擎,G 使得记录能够竖着排列,如果不用 G 的话,效果如下
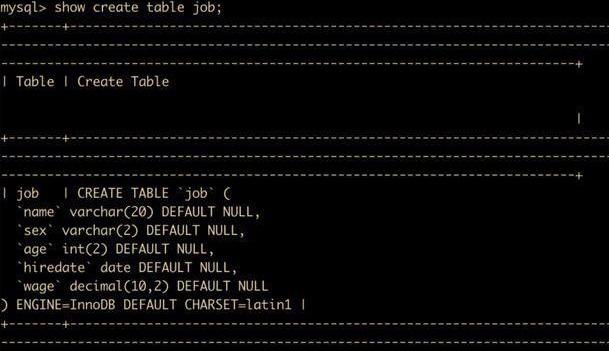
删除表
表的删除语句有两种,一种是 drop 语句,SQL 语句如下
drop table job一种是 tr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









