







网络Scrapy 爬虫对爬取的数据进行存储,我们之前有对极品笑话大全进行成功爬取下面就是我们爬取的数据展示,一个简单的爬取
数据有了,我们就要进行存储,我们一般小白都会在spider.py文件中进行存储,用with open打开文件这个方法,学习scrapy爬虫这样是不推荐的,大家还记得我们爬虫框架每一个.py文件它都有其功能,我们存储就要用到pipelines.py文件。

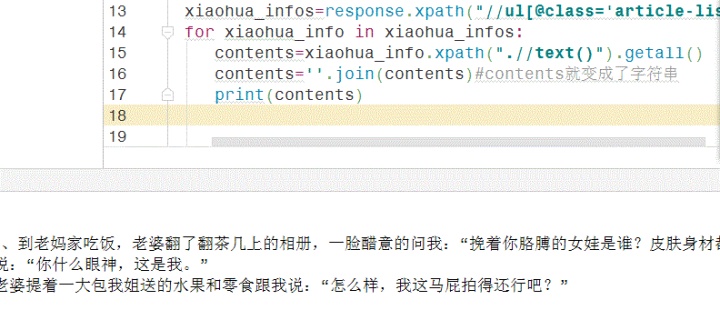
1.我们打开jp_spider爬虫文件,我建立一个字典,contents=xiaohua_info.xpath(".//text()").getall()
‎contents=''.join(contents)#contents就变成了字符串
‎content={"contents":contents}
‎yield content
这里用yield返回,就是说明parse 函数变成了一个生成器,以后我们想要数据遍历它就可以了,yield把数据返回给scrapy爬虫引擎,然后引擎把它给pipelines。
2.打开pipelines.py文件,pipelines里我们要调用三个函数,
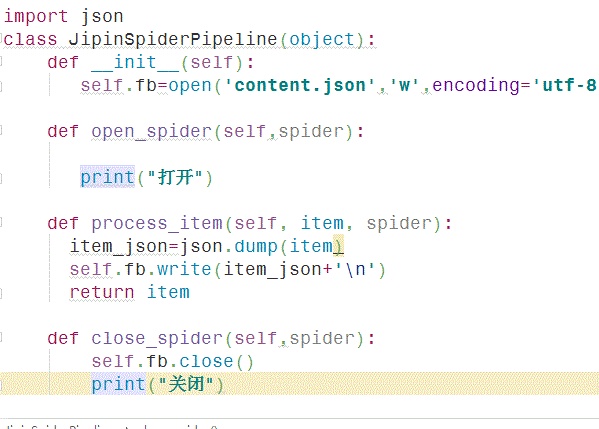
用json 来存储文件,导入json,用一个构造函数来打开文件,process函数写入,然后关闭,存储过程就写完了,
3,要运行pipelines,我们要打开settings文件,找到ITEM_PIPELINES

取消注释,里面已经生成了一个爬虫项目pipelines,后面有一个valur值,这个值是一个优先级的意思,我们有时候有很多个pipelines,所就后面的数越小,越先执行这个pipelines,我们这里只有一个写多少都无所谓。
4,运行爬虫,大家看图,有没有发现什么?

它生成了一个content.json文件,就是我们在pipelines里面建立的,这样就完成了。
学习不是一蹴而就,大家慢慢来。















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









