






目录
引言
临近期末,制作期末作业的同时发布第一篇博客练练手。知识点比较基础,面向新手,可能有些啰嗦,还望见谅。
我要爬取的数据为全国疫情数据(不含港澳台),记录了各个省份从2020年1月20日疫情爆发到2022年12月20日疫情结束每日新增、感染等数据。
由于疫情结束已过去半年,个别大的疫情信息公布平台已经关闭此功能(例:腾讯新闻),并且在网页上也不会显示每一天的数据,因此我选择抓包的方式从后台获取json数据。
抓包与Scrapy
通过抓包获取json数据
本次我选择的是从新浪新闻获取数据。由于我要获取的是各个省份的数据,所以并不能获取全国的json数据。我这里选择分别获取各省份的数据并进行拼接。打开新浪新闻的疫情专栏:
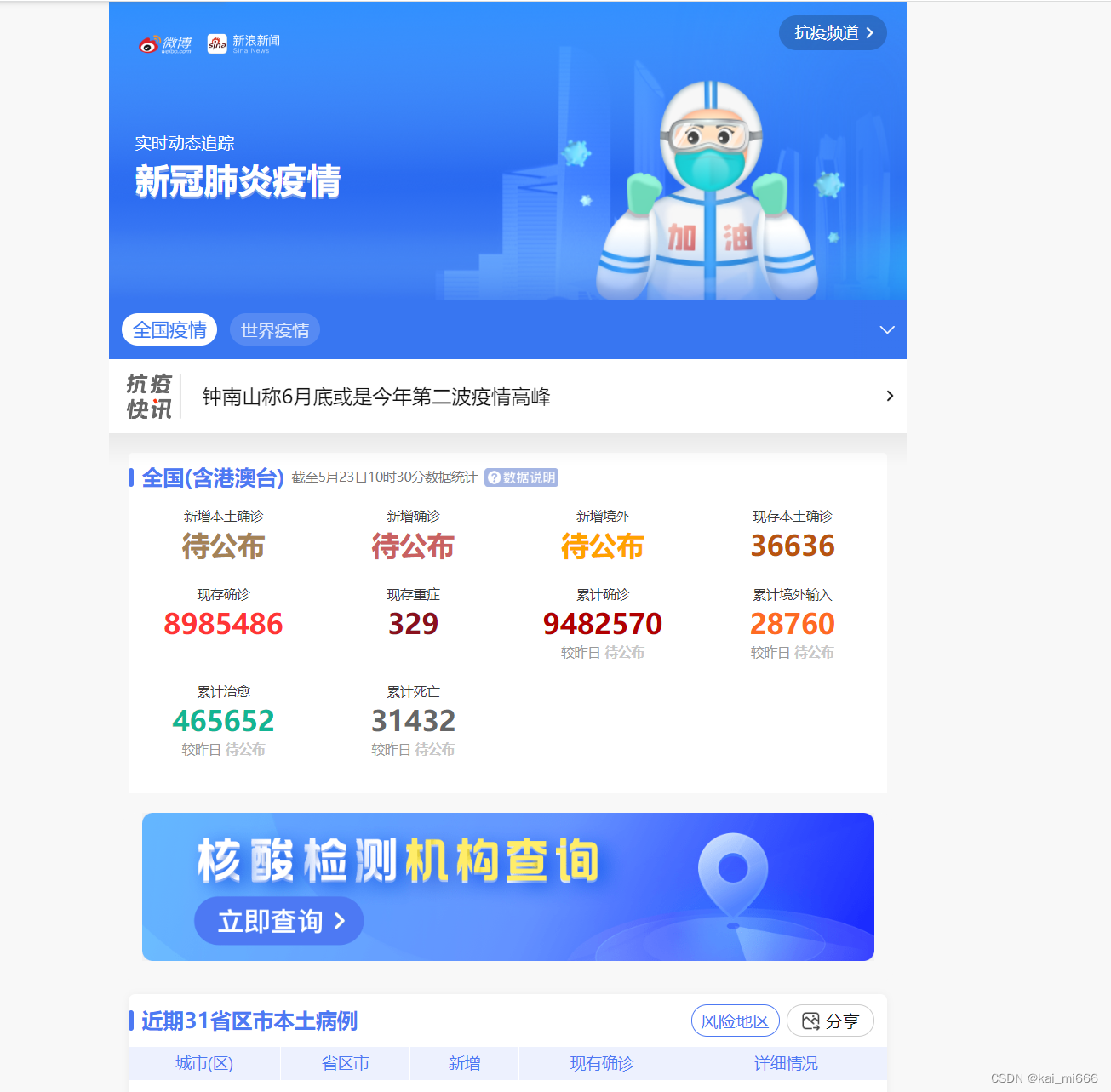
按下F12,打开网络(Network)选项,在下方“中国病例”点击想要获取的省份(例:北京)进入详情界面。注:要在开启网络选项的时候打开详情界面,或者在详情界面刷新也行。
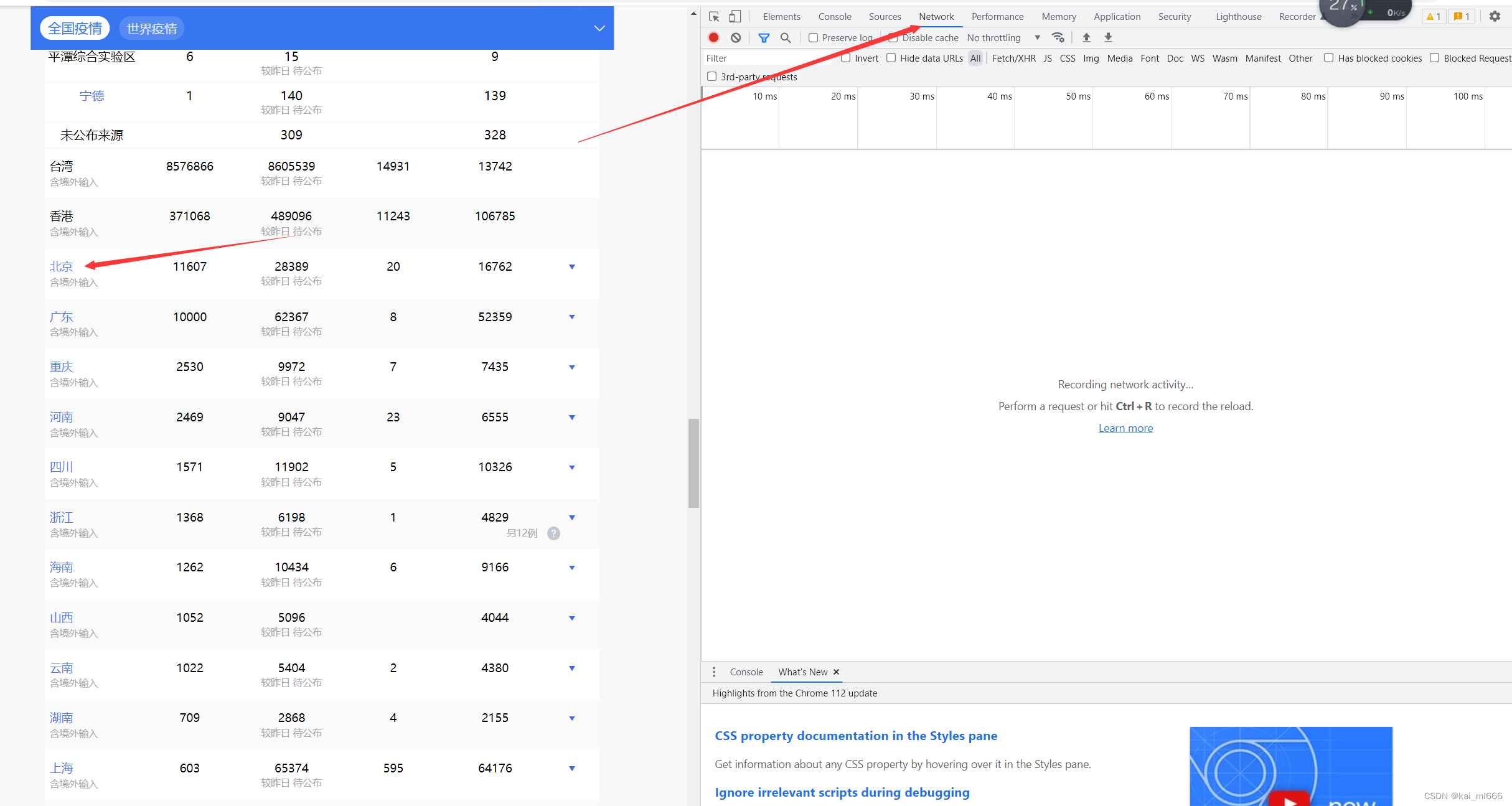
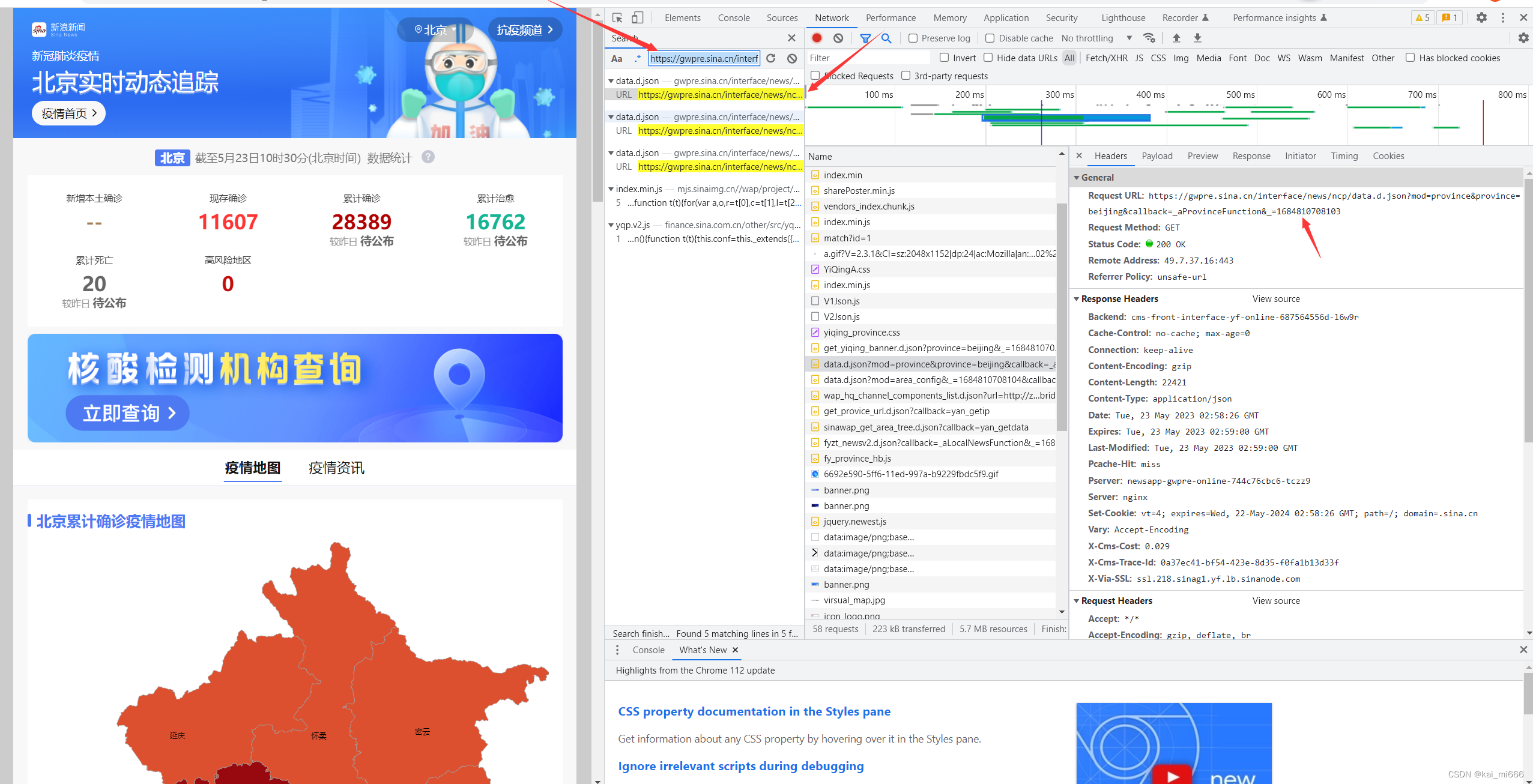
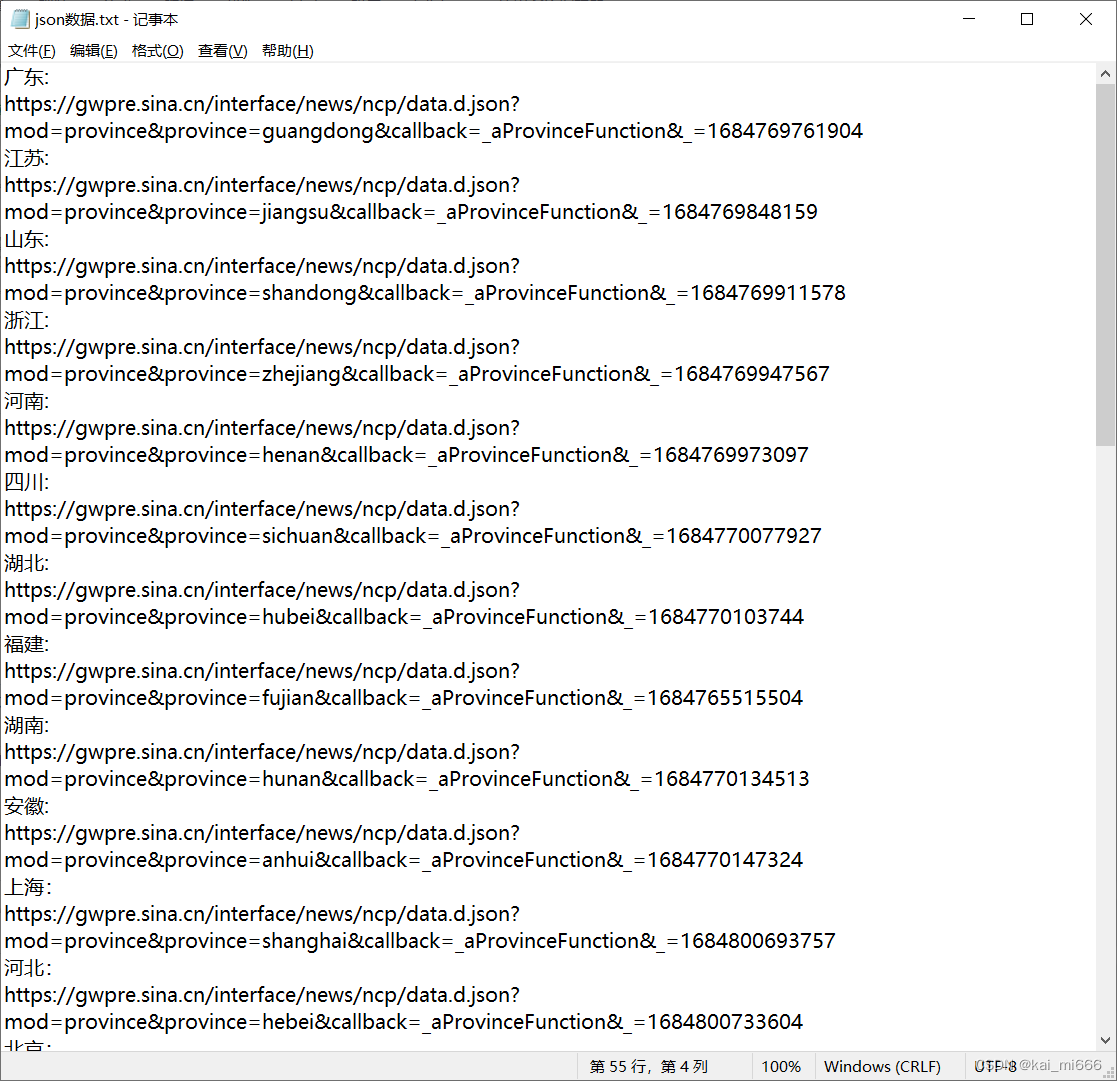
进去以后右边就会显示数据,我们接下来就要寻找到后台获取的json数据,一般类型为xhr、script、json。找到以后打开,右边会跳出弹窗,我们复制Request URL中的链接,这个就是北京的json数据

复制到网页上查看,historylist下的就是北京的历史数据
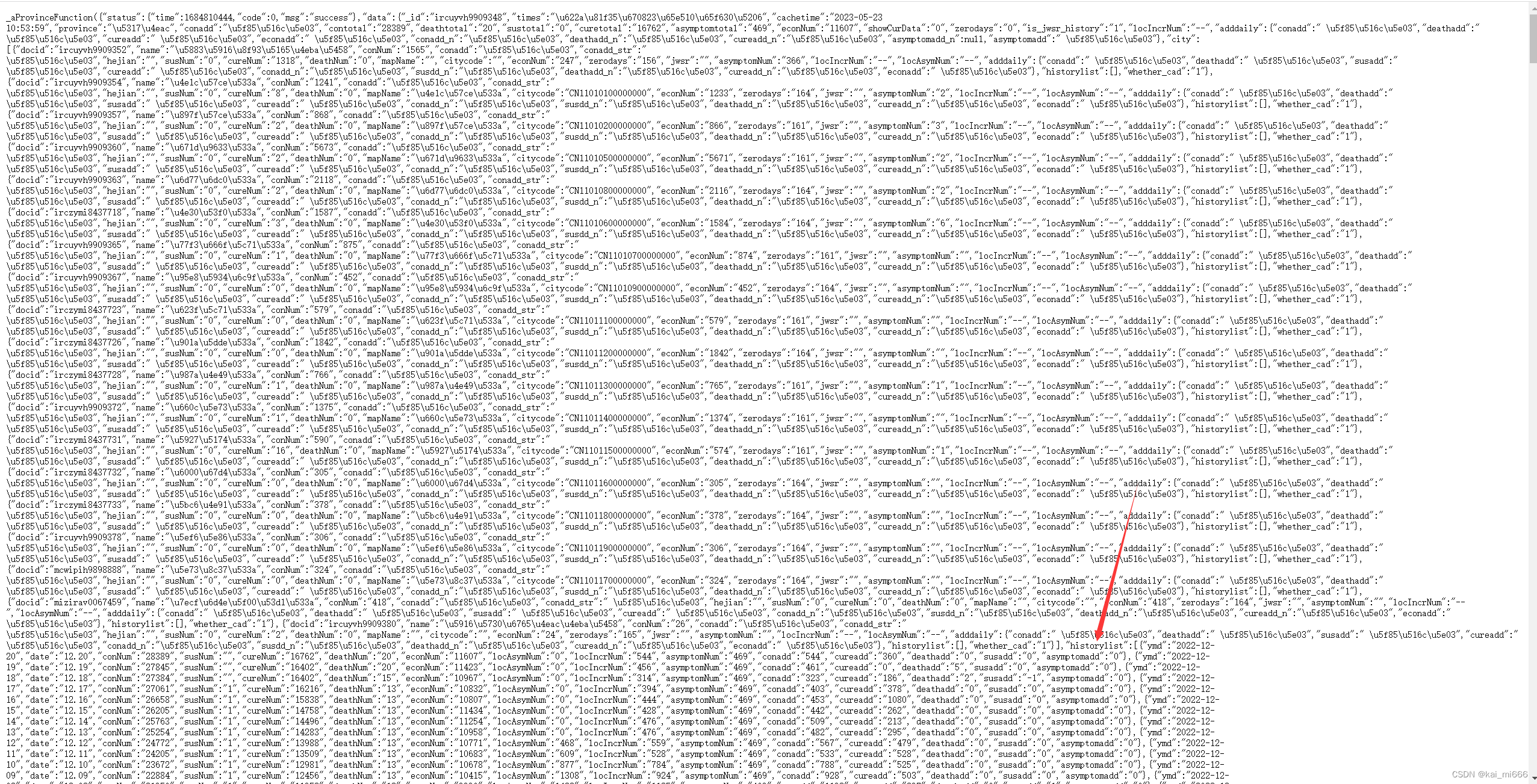
接下来,我们可以按照此方法接着获取其他省份的数据了,这里有个小方法,我们可以发现这段json数据链接中有很多相同的地方,因此我们可以按下ctrl+F打开搜索栏,把相同的前缀输入进去快速过滤
抓完包后就可以用scrapy进行爬取了,链接地址文章末尾我会跟代码一起打包放在百度网盘里。
通过Scrapy爬取json数据,并保存为csv格式
详细的scrapy使用方法就不赘述,网上有很多的教程,我这里就简单说明一下,详情可看中文版的官方文档
Scrapy 教程 — Scrapy 2.5.0 文档 (osgeo.cn)
创建项目
新建一个文件夹,名称随便起,在文件夹中创建一个scrapy项目,win键+R键打开运行,输入cmd打开命令行(也可以像我一样点击pycharm下面的Terminal打开命令行),输入cd 文件夹根目录 来跳转到你的根目录,如果盘符不一样,如:命令行为C盘,但是项目根目录在D盘,可以输入D:切换盘符。之后的指令都会在你的根目录运行。
输入scrapy startproject tutorial 创建项目(tutorial为你自己要创建的项目名称)。我这里由于项目已经做好,就创建一个测试项目演示一下,效果如下。
PS:可以设置一下项目根目录,对着根目录如下点击Sources Root。
书写代码
接下来就可以开始写代码爬取数据了。
由于这个json数据比较规范,没有空格空行,因此我没有使用管道进行数据处理。所有我修改的文件只有items.py和settings.py,加上自己创建的一共有三个文件。
我在spiders文件夹中创建了一个名为covid的python文件,内容如下。
import json
import scrapy
from scrapy_covid.items import CovItem
class CovidSpider(scrapy.Spider):
name = "covid"
start_urls = ["https://gwpre.sina.cn/interface/news/ncp/data.d.json?mod=province&province=xizang&callback=_aProvinceFunction&_=1684801289292"]
def parse(self, response):
data = response.body.decode('utf-8')
start_index = data.find('(') + 1
end_index = data.rfind(')')
json_data = json.loads(data[start_index:end_index]) # 将响应内容解析为JSON
history_list = json_data['data']['historylist'] # 获取"historylist"字段的值
# 循环写入每条数据
for item in history_list:
Item =CovItem()
Item['日期'] = item['ymd']
Item['累计确诊人数'] = item['conNum']
Item['累计治愈人数'] = item['cureNum']
Item['累计死亡人数'] = item['deathNum']
Item['现存确诊人数'] = item['econNum']
Item['无症状感染者人数'] = item['locAsymNum']
Item['新增感染者人数'] = item['locIncrNum']
Item['累计新增确诊人数'] = item['conadd']
Item['累计新增治愈人数'] = item['cureadd']
Item['累计新增死亡人数'] = item['deathadd']
Item['疑似病例新增人数'] = item['susadd']
Item['无症状感染者新增人数'] = item['asymptomadd']
yield Item
name为你的项目标识,后续运行scrapy会用到它。
start_urls为你的json数据链接,我这里只写了一个,不知道写多个会不会一起运行,我没有尝试,因为我要为每个文件单独命名。
在items.py文件中设置item对象,我这里新建了一个名为CovItem的类。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyCovidItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class CovItem(scrapy.Item):
日期 = scrapy.Field()
累计确诊人数 = scrapy.Field()
累计治愈人数 = scrapy.Field()
累计死亡人数 = scrapy.Field()
现存确诊人数 = scrapy.Field()
无症状感染者人数 = scrapy.Field()
新增感染者人数 = scrapy.Field()
累计新增确诊人数 = scrapy.Field()
累计新增治愈人数 = scrapy.Field()
累计新增死亡人数 = scrapy.Field()
疑似病例新增人数 = scrapy.Field()
无症状感染者新增人数 = scrapy.Field()接下来修改settings.py文件,需要修改的地方并不多。把“君子协议”ROBOTSTXT_OBEY改成False
ROBOTSTXT_OBEY = False在前面一点的位置添加一行代码,他会影响生成csv的表头。
FEED_EXPORT_FIELDS = ['日期','累计确诊人数','累计治愈人数','累计死亡人数','现存确诊人数','无症状感染者人数','新增感染者人数','累计新增确诊人数','累计新增治愈人数','累计新增死亡人数','疑似病例新增人数','无症状感染者新增人数']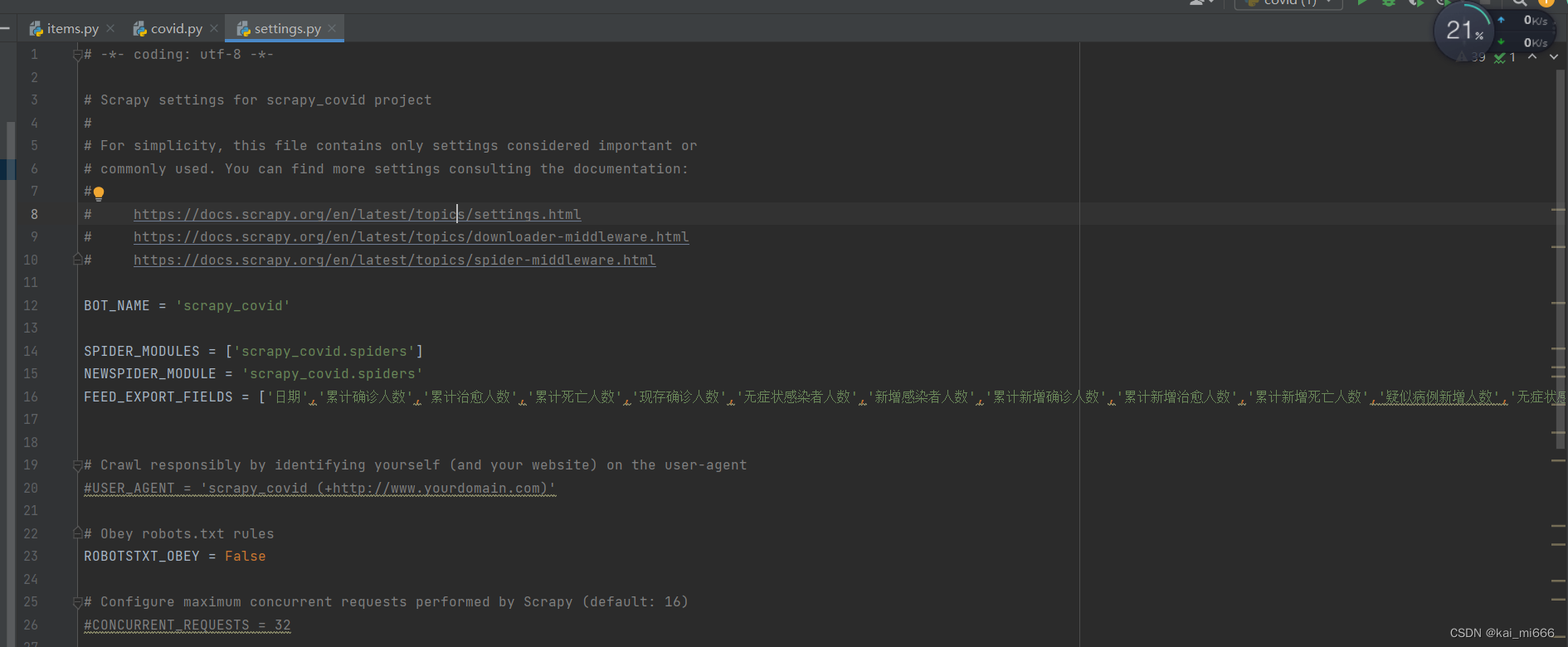
接下来就可以运行scrapy了。
运行Scrapy
依然是命令行跳转到根目录,输入
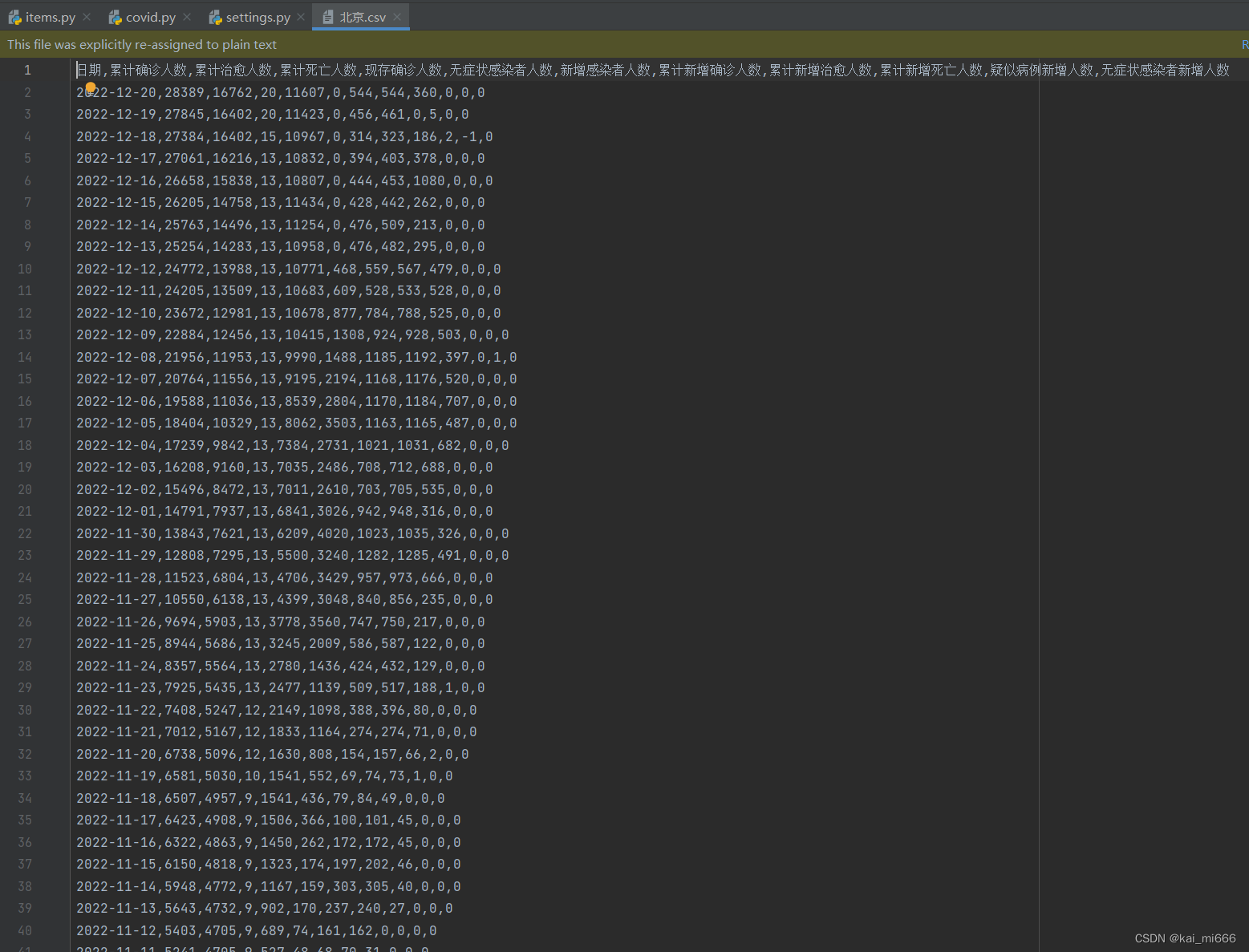
scrapy crawl covid -o 北京.csv
covid为你创建文件中“name”的值
“北京”可根据你现在正在爬取的json数据进行更改,就是个csv文件名称。
回车后数据很快就出来了
然后我们可以依次修改start_urls的json地址
和运行代码的命名得到31个省份的csv数据。
Pandas与Matplotlib
现在我们可以对数据进行处理了,创建一个新的文件夹,名称自定,我创建的项目如下。
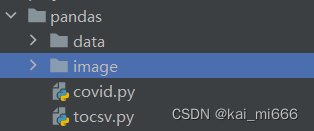
data:数据集存放的位置
image:一会生成图表存放的位置
covid.py:用来生成图表的文件
tocsv.py:用来合并数据的文件
合并数据
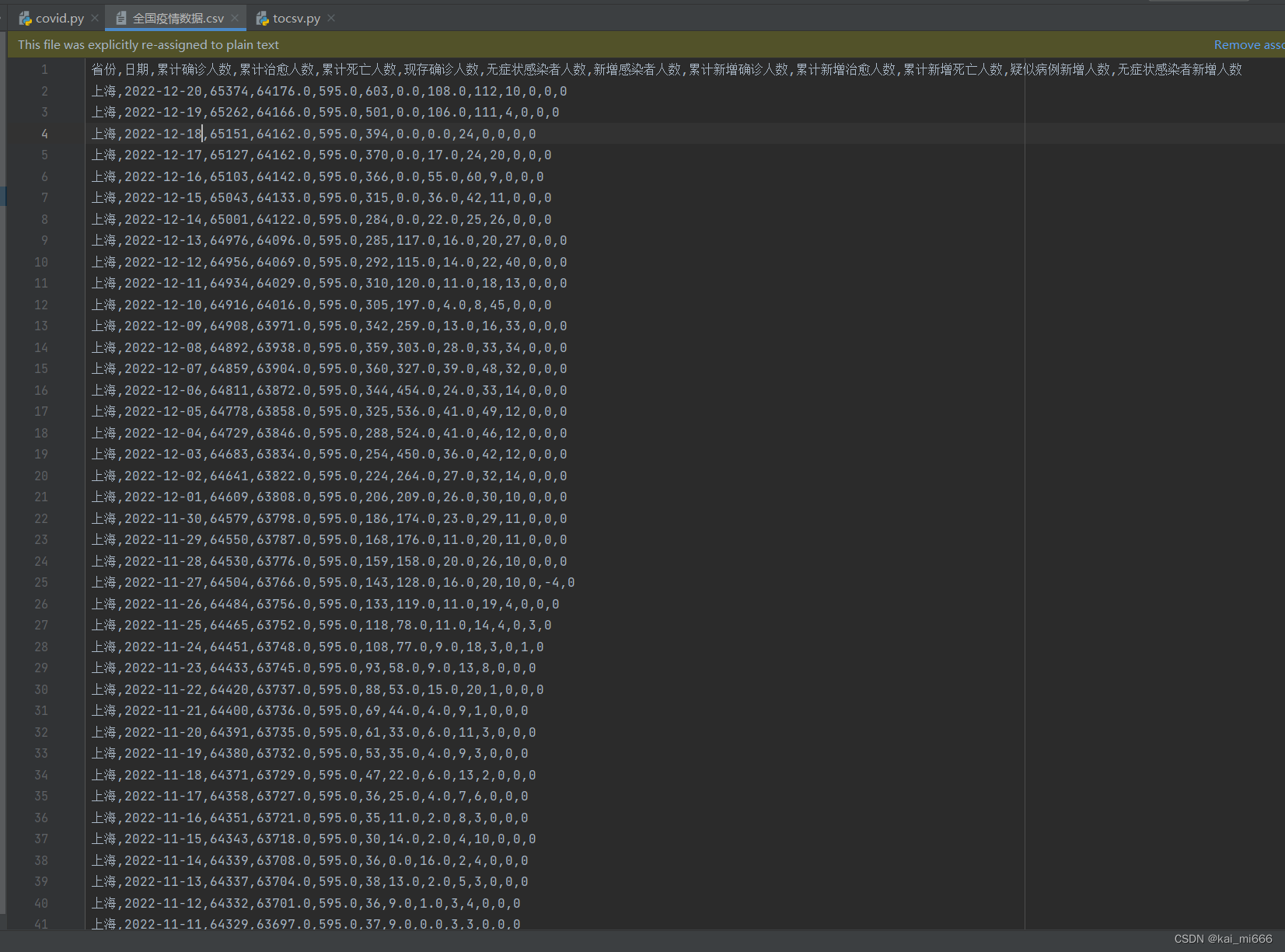
在tocsv.py文件中写入如下代码:
import glob
import os
import pandas as pd
if __name__ == '__main__':
# 获取所有CSV文件的文件路径
files = glob.glob('data/*.csv')
# 创建一个空的DataFrame对象
data = pd.DataFrame(columns=['省份', '日期', '累计确诊人数', '累计治愈人数', '累计死亡人数', '现存确诊人数', '无症状感染者人数', '新增感染者人数', '累计新增确诊人数', '累计新增治愈人数', '累计新增死亡人数', '疑似病例新增人数', '无症状感染者新增人数'])
# 逐个读取CSV文件并合并到DataFrame对象中
for file in files:
province = os.path.splitext(os.path.basename(file))[0] # 获取文件名作为省份变量的值
df = pd.read_csv(file)
df['省份'] = province # 添加省份列
data = pd.concat([data, df], ignore_index=True)
# 保存合并后的数据到CSV文件
data.to_csv('全国疫情数据.csv', index=False)我们在原来数据的基础上新加了一个名为“省份”的表头,并通过os模块获取到文件的名称放入其中,最后我们可以保存为一个csv文件,一共三万多条数据。
数据处理和生成图像
接下来我们就可以进行最后的生成图表了。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
if __name__ == '__main__':
# 加载数据
file = pd.read_csv(
'./data/全国疫情数据.csv'
)
# 将日期列转换为日期时间类型
file['日期'] = pd.to_datetime(file['日期'])
# 全国每日新增感染者人数(1)
x1 = file.groupby('日期')['新增感染者人数'].sum().reset_index()
plt.plot(x1['日期'],x1['新增感染者人数'])
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('全国每日新增感染者人数')
plt.xlabel('日期')
plt.ylabel('新增感染者人数')
# 设置x轴刻度间隔为每隔三个月
ax = plt.gca()
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=3))
plt.xticks(rotation=40)
plt.tight_layout()
plt.savefig(r'image/全国每日新增感染者人数.png', dpi=500)
plt.close()
# 全国每日现存确诊人数(2)
x2 =file.groupby('日期')['现存确诊人数'].sum().reset_index()
plt.plot(x2['日期'], x2['现存确诊人数'])
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('全国每日现存确诊人数')
plt.xlabel('日期')
plt.ylabel('现存确诊人数')
# 设置x轴刻度间隔为每隔三个月
ax = plt.gca()
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=3))
plt.xticks(rotation=40)
plt.tight_layout()
plt.savefig(r'image/全国每日现存确诊人数.png', dpi=500)
plt.close()
# 全国每日现存无症状感染者人数(3)
x3 = file.groupby('日期')['无症状感染者人数'].sum().reset_index()
plt.plot(x3['日期'], x3['无症状感染者人数'])
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('全国每日现存无症状感染者人数')
plt.xlabel('日期')
plt.ylabel('无症状感染者人数')
# 设置x轴刻度间隔为每隔三个月
ax = plt.gca()
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=3))
plt.xticks(rotation=40)
plt.tight_layout()
plt.savefig(r'image/全国每日现存无症状感染者人数.png', dpi=500)
plt.close()
# 全国每日疑似病例新增人数(4)
x4 = file.groupby('日期')['疑似病例新增人数'].sum().reset_index()
plt.plot(x4['日期'], x4['疑似病例新增人数'])
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 用来正常显示中文标签以及负号
plt.title('全国每日现存疑似病例新增人数')
plt.xlabel('日期')
plt.ylabel('疑似病例新增人数')
# 设置x轴刻度间隔为每隔三个月
ax = plt.gca()
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=3))
plt.xticks(rotation=40)
plt.tight_layout()
plt.savefig(r'image/全国每日现存疑似病例新增人数.png', dpi=500)
plt.close()一共生成了四张图片,我放在后面展示。由于我x轴获取的是时间,全部按照默认显示的话会一片黑,什么也看不出来,因此我们改成3个月显示一次。
导入matplotlib.dates包
import matplotlib.dates as mdates将日期列转换为日期时间类型(重要)
# 将日期列转换为日期时间类型
file['日期'] = pd.to_datetime(file['日期'])设置图表的x轴和y轴信息,并设置字体以便于显示中文和字符
ps:由于最后一张图的数据含有复数,使用使用的字体与前面不一样,这点注意一下
# 全国每日新增感染者人数(1)
x1 = file.groupby('日期')['新增感染者人数'].sum().reset_index()
plt.plot(x1['日期'],x1['新增感染者人数'])
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('全国每日新增感染者人数')
plt.xlabel('日期')
plt.ylabel('新增感染者人数')设置x轴刻度间隔,间隔为3个月
# 设置x轴刻度间隔为每隔三个月
ax = plt.gca()
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=3))
plt.xticks(rotation=40)
plt.tight_layout()生成图片(记得不要忘记加个close关闭)
plt.savefig(r'image/全国每日现存无症状感染者人数.png', dpi=500)
plt.close()剩下几张图都可以按着这种方法做,也可以自己改动
生成出来的图片
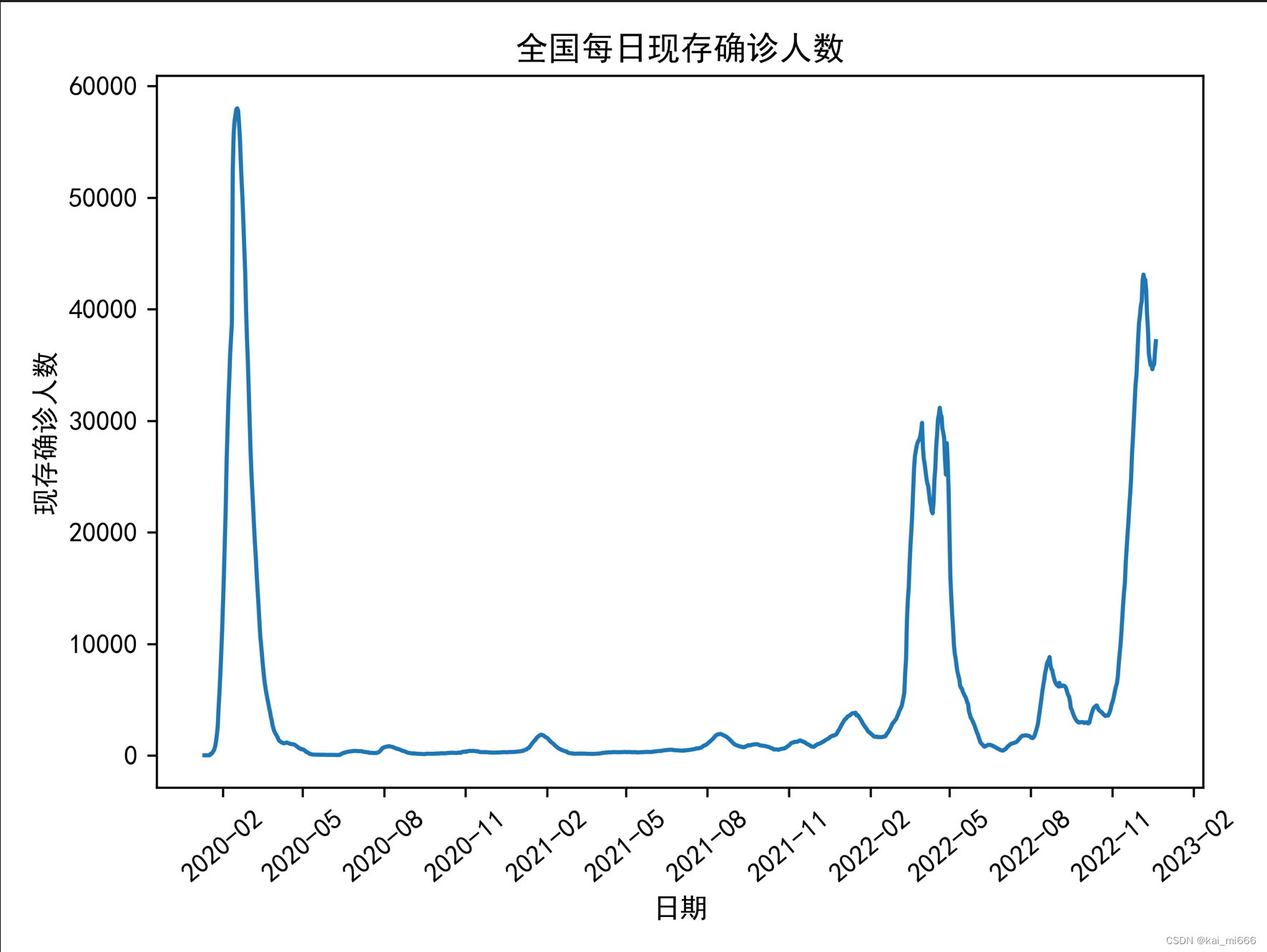
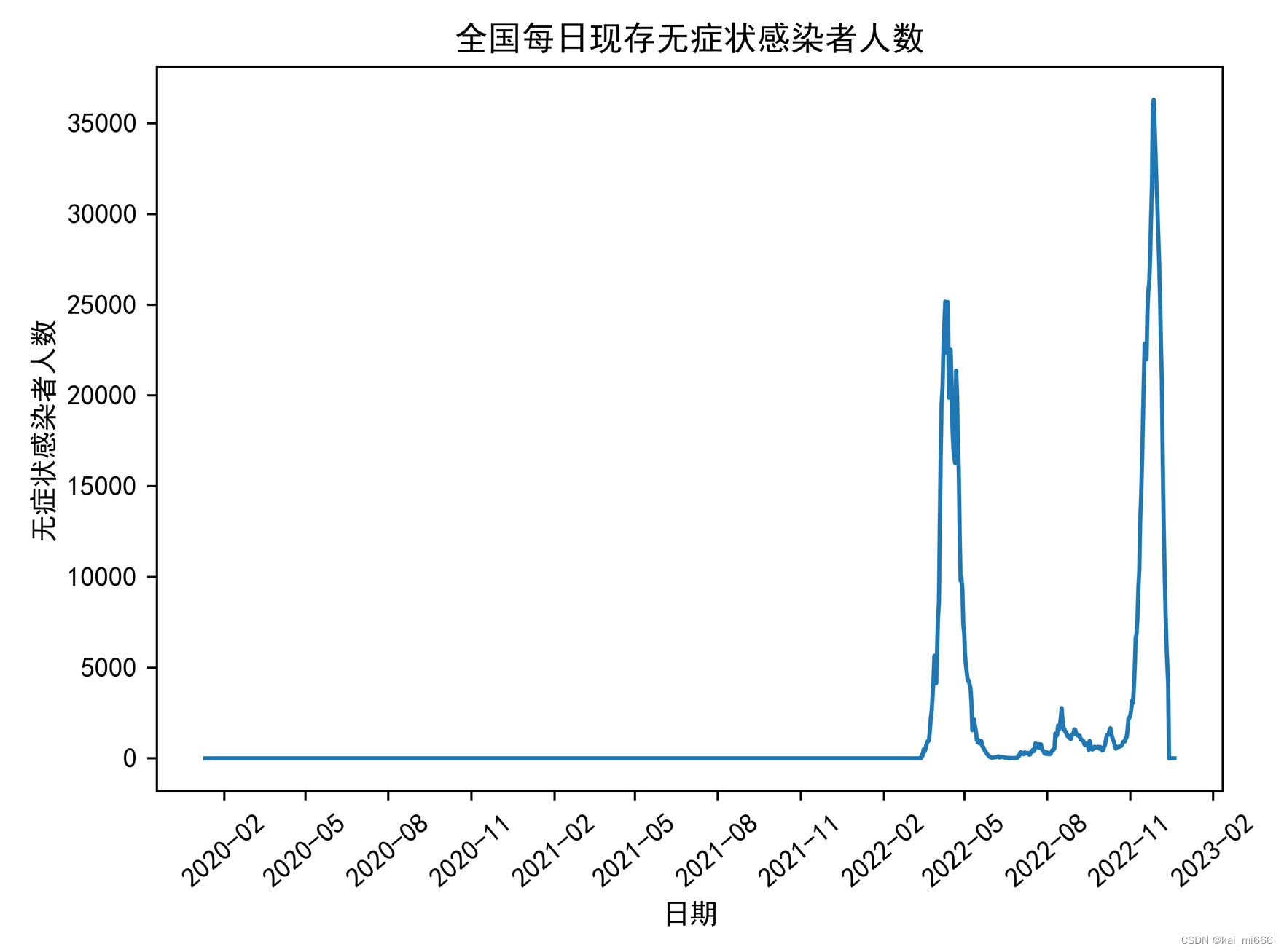
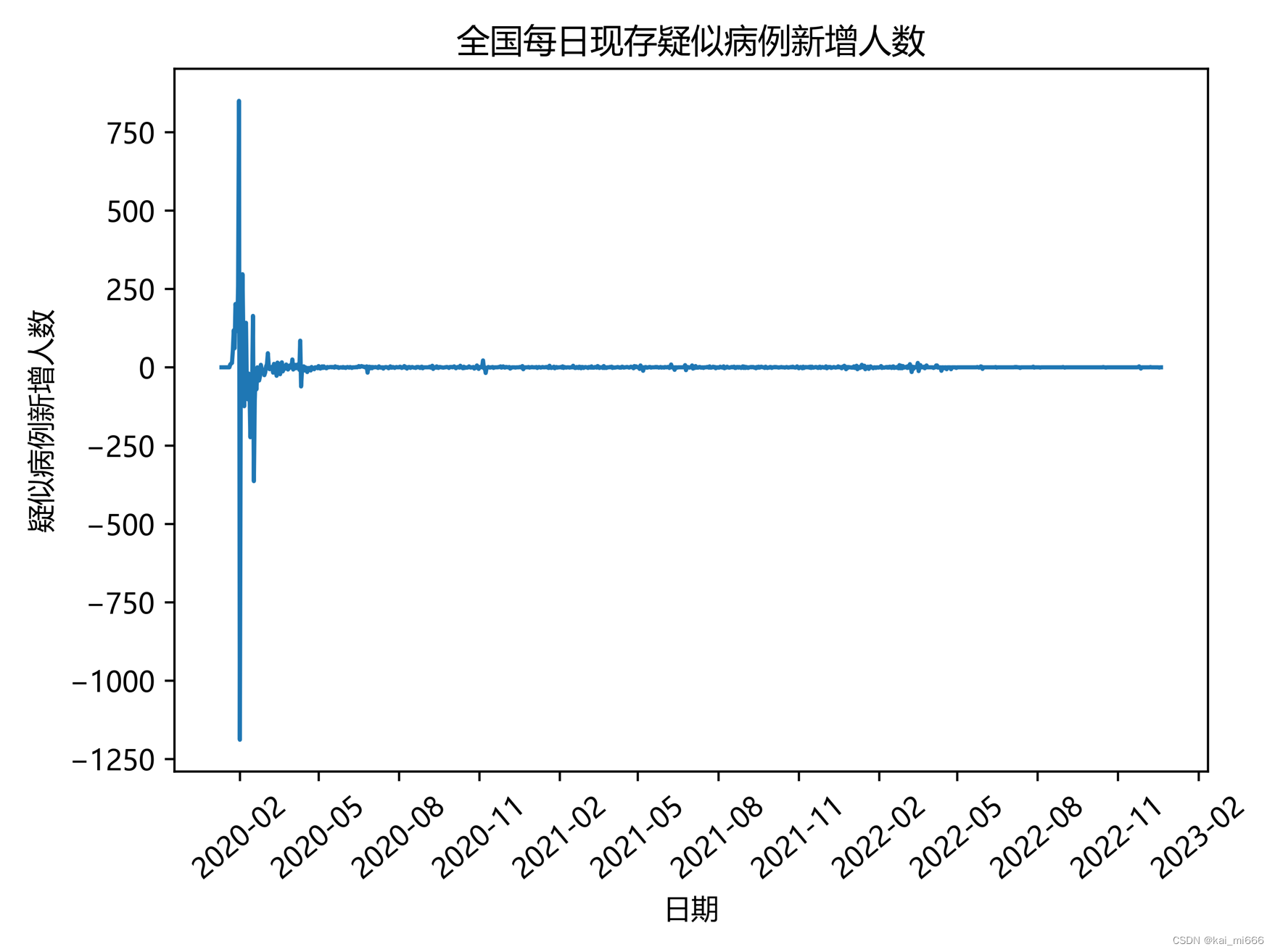
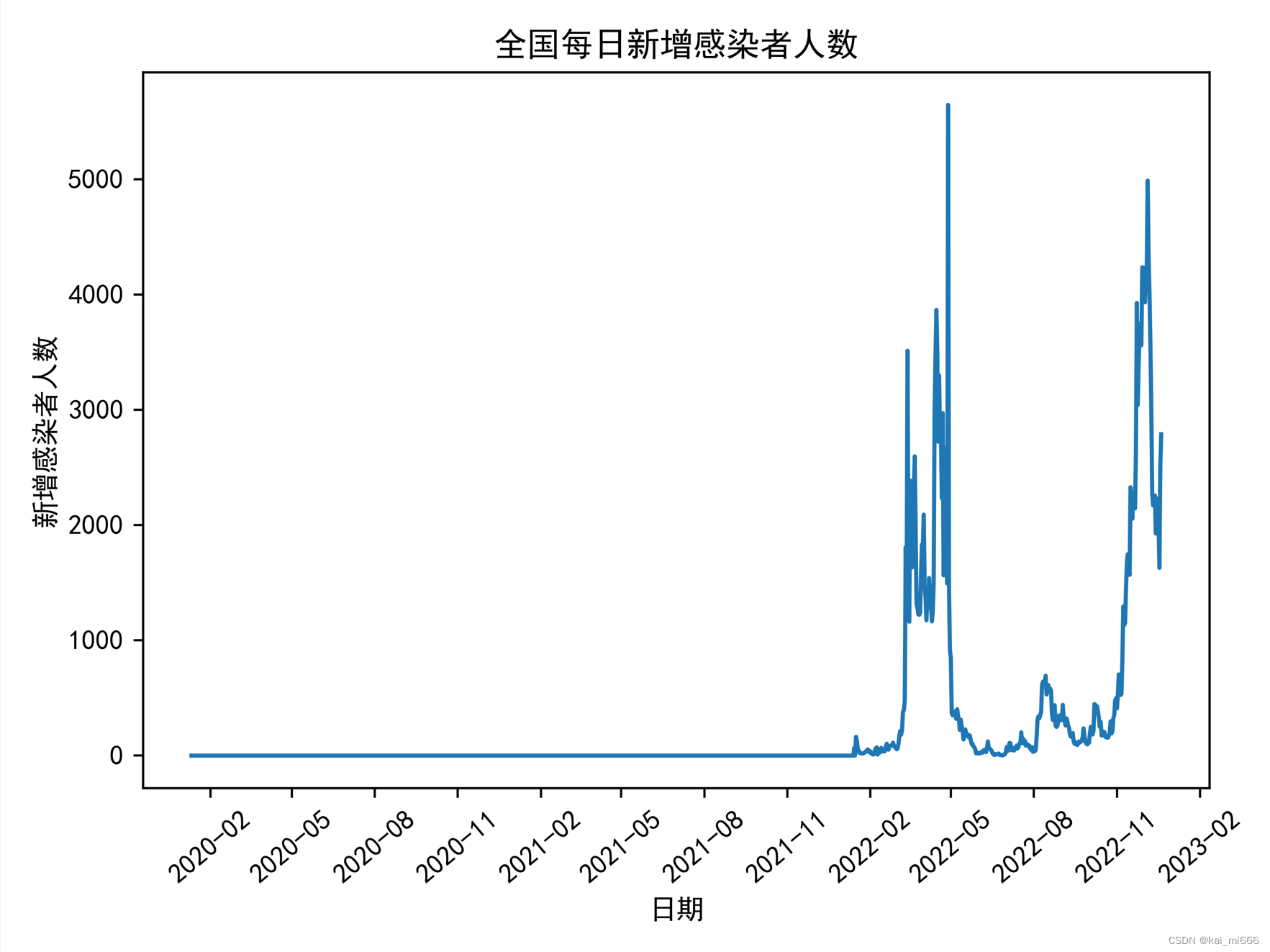
项目文件以及数据集
链接:https://pan.baidu.com/s/1tu88qnU5fk95U5cl4UZdrw?pwd=xjn0
提取码:xjn0














 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









