






【0.前言】
MySQL上直接Drop张大表,会有什么影响,能否直接写个 drop table ; 或者 truncate table ; 甚至是delete * from?
如果这张表足够大,比如1亿行记录,drop 的时间需要多久,期间我的MySQL是否能正常访问?
首先要删掉的大表一定是没人访问的表
如果这张表仍然还有被高频的访问,你敢直接删那基本上就是茅坑里点灯,找死!
如果MySQL版本是5.5.23以下,直接DROP一张大表,也是守着茅坑睡觉,离死不远。
即使明确了这张表没人访问了,你的MySQL版本也足够新,并不表示就远离了茅坑,仍然有被崩到的风险。
大表:我们定义为5000万行以上,或者单表文件大于100G
我们要讨论的是innodb存储引擎,myisam等存储引擎,DROP 表又快又安全
这篇文章的目录
【0.前言】
【1.drop table 的风险和避免方法】
Drop table 要做的主要有3件事
可能会引起的风险有3种
解决和避免的方法3种
【2.一组drop表的测试】
【3.什么是MySQL的lazy drop table】
【4.drop table时innodb buffer pool的处理】
步骤1:drop一张热表时innodb buffer pool的变化
步骤2: 执行RenameTable
步骤3: 执行SQL,drop table dbatest_old;
第二个测试的小结
【5.drop table 和truncate table的风险对比】
【6.pt-online-schema-change 在改表以后的删表是否有风险】
【7.源码解读】
1.入口函数:mysql_rm_table
2.mysql_rm_table_no_locks
3.ha_delete_table –>ha_innobase::delete_table
4.row_drop_table_for_mysql
5.buf_LRU_flush_or_remove_pages
6.buf_LRU_drop_page_hash_for_tablespace
【8.dropTable最佳实践】
【1.drop table 的风险和避免方法】
Drop table 要做的主要有3件事:
把硬盘上的这个文件删了
把内存中的这个库已经加载加来的Page删了,腾出空间
把MySQL元数据字典中这张表关联信息删了
可能会引起的风险有3种:
MySQL长时间阻塞其他事务执行,大量请求堆积,实例假死。(锁)
磁盘IO被短时间大量占用,数据库性能明显下降(IO)
内存里的page大量置换,引起线程阻塞,实例假死(内存)
解决和避免的方法3种:
io占用的问题,对这个表建一个硬链,使Drop table 表的时候并没有真的去磁盘上删那个巨大的ibd文件,事后再用truncate的方式慢慢的删除这个文件,如果是SSD盘和卡,drop table后再直接rm文件也没问题
内存和IO占用的问题,升级MySQL版本
MySQL 5.5.23 引入了 lazy drop table 来优化改进了drop 操作影响(改进,改进,并没有说完全消除!!!拐杖敲黑板3次)
MySQL5.7.8 拆分了AHI共用一个全局的锁结构 btr_search_latch
MySQL8.0 解决了truncate table 的风险
道路千万行,低峰第一条。选择低峰时间段,找个夜深人静,月黑风高的时候是更好的选择。
【2.一组drop表的测试】
drop一张5亿记录的大表究竟需要多久时间,1秒?5秒?10秒?2分钟?3小时?还是一两天?你是否有过靠谱的预计
先看一组新鲜的热气腾腾的,一组测试,看看不同条件下drop一张表所有的时间
测试环境
硬件:128G内存 3T宝存卡 xfs
系统:CentOS Linux release 7.6.1810
MySQL version: 5.7.26
innodb参数:innodb_buffer_pool_instances=1
| 表文件大小 | 创建硬链ln | BufferPool大小 | BufferPool繁忙 | 影响其他表的访问 | 执行drop table用时(秒) |
|---|---|---|---|---|---|
| 240G | 否 | 64G | 是 | 无明显影响 | 27.52 |
| 240G | 是 | 64G | 是 | 无明显影响 | 18.56 |
| 240G | 是 | 64G | 否 | 无明显影响 | 5.03 |
| 100G | 是 | 64G | 是 | 无明显影响 | 12.93 |
| 100G | 是 | 4G | 是 | 无明显影响 | 15.71 |
| 100G | 是 | 4G | 否 | 无明显影响 | 3.08 |
作为对比我们再DROP一张不是那么大的表
| 表文件大小 | 创建硬链ln | BufferPool大小 | BufferPool繁忙 | 影响其他表的访问 | 执行drop table用时(秒) |
|---|---|---|---|---|---|
| 2.5G | 否 | 64G | 是 | 无明显影响 | 2.38 |
| 2.5G | 否 | 64G | 否 | 无明显影响 | 0.92 |
| 2.5G | 否 | 4G | 是 | 无明显影响 | 0.11 |
| 2.5G | 否 | 4G | 否 | 无明显影响 | 0.15 |
| 2.5G | 是 | 64G | 是 | 无明显影响 | 2.11 |
| 2.5G | 是 | 64G | 否 | 无明显影响 | 0.56 |
| 2.5G | 是 | 4G | 是 | 无明显影响 | 0.16 |
| 2.5G | 是 | 4G | 否 | 无明显影响 | 0.11 |
不管是大表的DROP还是小表的DROP,我们不难总结出来以下规律
drop 越大的表,同等条件下,执行用时越长
drop 表如果做了硬链,比不做硬链,执行用时要短
bufferPool的大小不显著影响 drop表的用时,但是bufferPool的繁忙程度很明显的影响了执行用时,越忙的bufferPool执行Drop表用时越长
而所有的上面试验中,我们都发现DROP一张大表,好像对线上其他的访问都没有影响,事实上是有点影响的
我们的DROP 表操作会导致本来就很BUSY的bufferpool置换动作变得更加频繁和拥挤
我们在drop 表期间,持有MDL锁,这时候show tables等命令,其实是会卡顿的
如果我们没做硬链,在drop table时会在磁盘上真实的删除一个大文件,期间IO使用率会明显上升 但是这些影响,在我们的这个压力测试环境下并没有体现(我们用Sysbench压了64个线程,QPS 大约2万左右)
我们对其他表的查询还在正常进行
我们的QPS/TPS指标没有明显波动
我们的MySQL实例还是好好的活着 这是为什么呢?我们执行一个这么莽撞而无理的SQL请求,似乎系统也没怎么波动,跟想象中的不一样啊!!!那是我们已经用了MySQL5.7了呀(拐棍连续杵地声!),已经有了成熟的lazy drop table 方案了。
【3.什么是MySQL的lazy drop table】
在第2节中我们做了各种各样的花样测试,对比了各种条件下删除表的速度,但是都没有引起MySQL访问异常,我们总结原先是因为MySQL较新的版用了lazy drop table 方法,什么是lazy drop ,它被设计用来解决什么样的问题,以及关联到的 bufferPool,lru列表 等概念是什么,想着用一些简单的描述来说清楚。如果:
你不关注MySQL是怎么实现的lazy drop table ,你只想知道有这么个技术。
你不想了解这些枯燥的名词,你只想看看真实的CASE中,MySQL删除一张大表时产生的关联影响和动作
你正在蹲坑,你不想看这堆名词的解释,你怕你的脚麻了,或者产生其他更为严重的后果。
你是个成熟的DBA,你对这些概念已经了解了。或者大约知道是怎么会事。
那么,其实你可以跳过这一节,直接到第4节,看具体的CASE,在那里有一个真实的新鲜的,冒着热气的删除一个大表,在内存中前后的影响以及对应的步骤分析。
名词储备
在我们理解MySQL5.5.23以后采用了lazydrop 优化后为什么对线上影响小之前,我们回顾一些基本而又重要的概念。
Page MySQL innodb是用page来组织数据和索引的,通常一个Page是16k,在内存中,在磁盘中都是一页页的Page。Page是怎么组织MySQL存储不熟的话,可以看我去年录的这个小视频《MySQL存储格式》https://mp.weixin.qq.com/s/XIFUzHj8_6B-mH-M5woA9w
BufferPool 当我们申请一个10G内存的MySQL实例时,通常说的是给这个实例设置了10G的BufferPool ,其他也有一些内存占用,但是量太小,被我们忽略了,MySQL的DATA/INDEX加载到内存都放在这
Lru MySQL Lru链表里存的是pageno和指向bufferpool的指针,不同于平时我们说的缓存过期方法,MySQL的LRU链表是有新旧两个队列,37%的冷区只在1秒内3次被访问后移到热区
AHI InnoDB存储引擎会监控对表上各索引页的查询,如果监控到某个索引页被频繁查询,并诊断后发现如果为这一页的数据创建Hash索引会带来更大的性能提升,则会自动为这一页的数据创建Hash索引,并称之为自适应Hash索引
什么是lazy drop
drop table dbatest 这个SQL在对表进行删除的时候,需要清理掉buffer pool中的page,但如果表比较大,占用过多的buffer pool,清理的动作会影响到在线的业务,所以MySQL 5.5.23以后的lazy drop table,帮我们很大程度上消除了大表删除的影响。
同步方式: 扫描lru链表,如果page属于T表,就从lru链表,hash表, flush list中删除,回收bufferpool中的block 并标记到free list中。
lazy方式: 扫描lru链表 如果page属于T表,就给page设置一个space_was_being_deleted属性,等lru置换或者checkpoint flush dirty block的时候进行清理。即在扫描LRU链表过程中,如果dirty page属于drop table,那么就直接从flush list中remove掉
注意这里的页并没有真正的在buffer Pool中清理掉,也没有从lru中清理了,会在等LRU过期和脏页刷新时再去真实的清理。
下面我们将从实际测试CASE中复现这个lazy drop table过程
【4.drop table时innodb buffer pool的处理】
下面我们开始我们第二个测试,测试过程中,用一个精心设计过的BufferPool占用情况分类报表,来展示这仅有的4G内存的BufferPooL各阶段的情况
实际:drop 一张热表时innodb buffer pool的变化
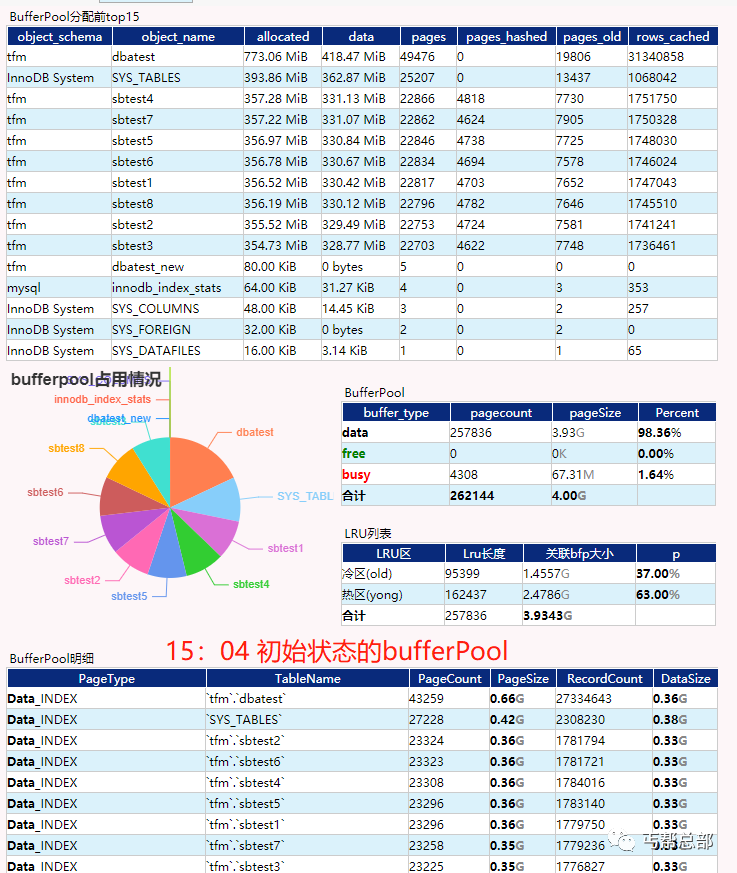
步骤1: 这是一开始的bufferpool状态,我们刚建了一张同结构的dbatest_new的空表,同时执行了,
select count(*) from dbatest
| 信息项 | 内容 |
|---|---|
| dbatest表 | 占用700M内存,且全在LRU列表的冷区(为什么全在冷区,这里你是不是就体会到了MySQL采用变种LRU算法的良苦用心了?) |
| sbtest1-8 | 这8张表的访问占了剩下的内存空间大约3.2G,且在持续变化和抢占内存 |
| busy页 | bufferpool中的页状态,要么就是存了数据,要么就是空闲,还有一种是正在操作的页,我们标记为busy,这些页可能是正在从磁盘中读到BufferPool中,也可能是正在从BufferPool的冷热区做交换。也可能是过期被踢出.因为我们整个测试过程中都在用SYSbench在压这个实例,这个实例是个比较繁忙的实例。一直能看到Busy的PAGE. |
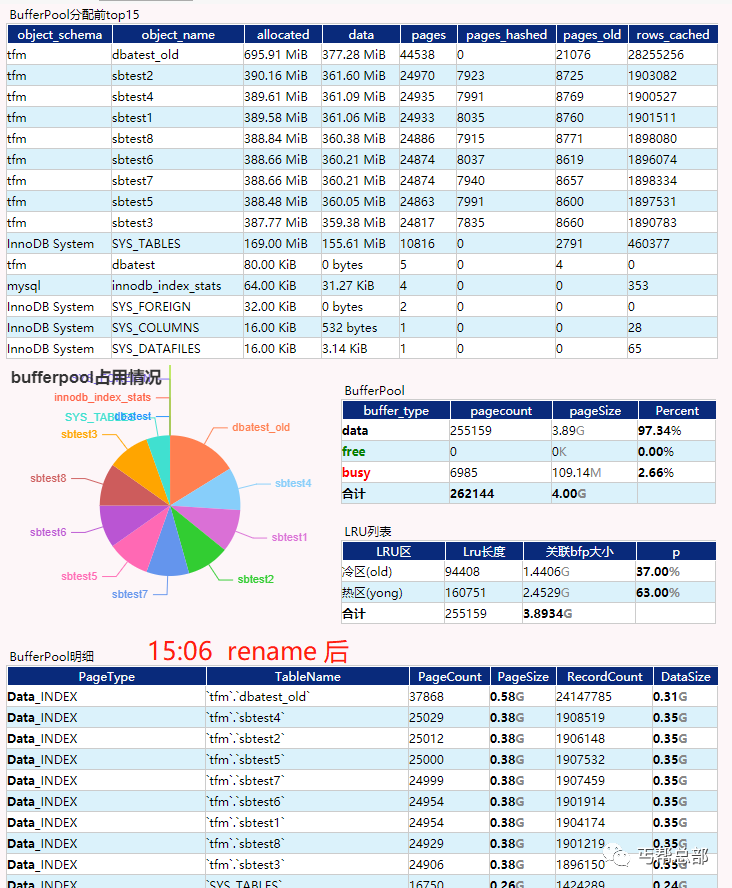
步骤2: 执行SQL,
alter table dbatest rename to dbatest_old;alter table dbatest_new rename to dbatest;,可能你会问了,这个测试不是要DROP 表吗,为啥要多此一步,别慌,只是顺带着说明一件事,你先记住我们DROP表前,做了一个RENAME的操作即可
| 信息项 | 内容 |
|---|---|
| 执行用时 | 0.00s,很快就执行完了 |
| BufferPool变化 | 原先dbatest的空间自动变成了dbatest_old的,事实上BufferPool中存的是一个叫spaceid的INT型字段,并没有存表名,所以这一步并没有改变bufferpool也没有修改LRU |
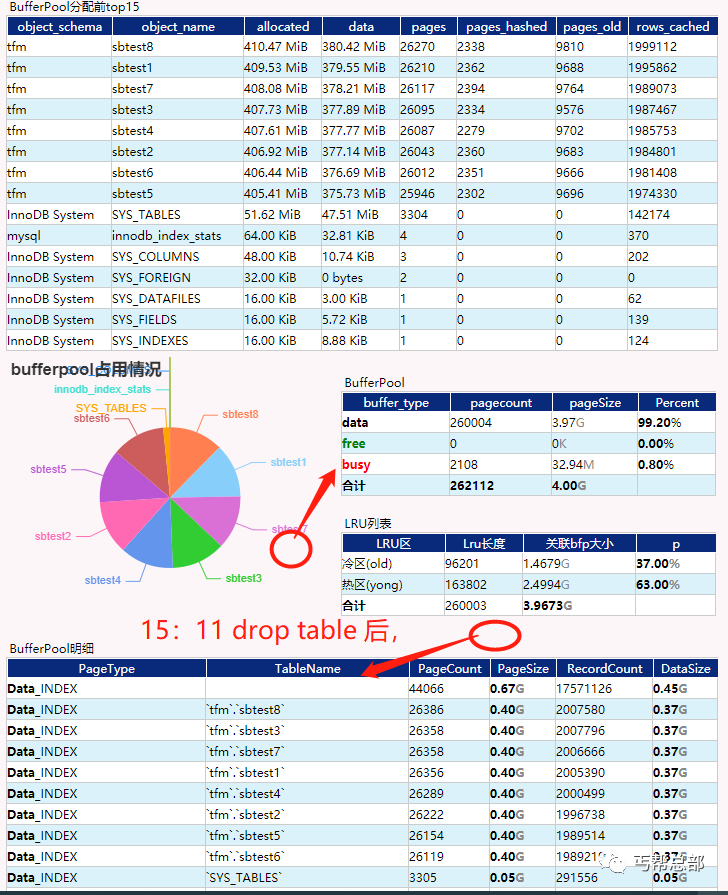
步骤3: 执行SQL,
drop table dbatest_old;
| 信息项 | 内容 |
|---|---|
| 执行用时 | 15.80s,不是很快,但是执行期间整个sysbench没有异常,QPS/TPS保持相对稳定,没有明显的性能变差 |
| BufferPool变化 | bufferpool总量变化不大,但是原dbatest_old表占用的空间会显示为找不到表(事实上是spaceid找不到对应的表名),这部分空间不会立即释放,也不能立即被其他正在运行的其他sbtest表占用,会持续很长一段时间,大约10几分钟后,才慢慢的被挤占完。想起一句话,老兵不死,只会慢慢调零。 |
第二个测试的小结
在MySQL5.7.26的版本中我们做了这个删除大表的测试
drop表时,MySQL采用了lazy drop 的方法,表删除的时候bufferPool 和lru 列表并没有立即消除原来的page和引用
rename表时,并不会消除内存中的关于这个表的page,因为采用了spaceid做对应关系,跟表名没有关系,更换表名不会影响内存中表和索引的缓存
drop表后的一段时间内(5-30min),bufferPool中busy部分会显著增加(呃,事实上这个实验上看起来不明显 ,因为这个实验是在模拟一个高并发访问的SQL实例,所以一直有内存抢占,BufferPool中的busy部分一直都很大,我的另一些测试是在一个空跑的实例上做的,会看到busy部分一直停留在0直到,DROP表后,busy部分明显增加,最后Free出来大量的bufferpool空间)
【5.drop table 和truncate table的风险对比】
MySQL8.0针对该问题说明:
On a system with a large InnoDB buffer pool and innodb_adaptive_hash_index enabled, TRUNCATE TABLE operations could cause a temporary drop in system performance due to an LRU scan that occurred when removing an InnoDB tables adaptive hash index entries.
To address this problem, TRUNCATE TABLE now invokes the same code as DROP TABLE and CREATE TABLE. The problem was addressed for DROP TABLE in MySQL 5.5.23.
意思为:
当InnoDB buffer pool比较大和innodb_adaptive_hash_index启用时,TRUNCATE TABLE操作可能由于发生了LRU扫描,删除InnoDB表的自适应散列索引项时,导致系统性能暂时下降。为了解决这个问题,TRUNCATE TABLE现在调用与DROP TABLE相同的代码删除表。因为在MySQL 5.5.23后,DROP TABLE解决了这个问题。
总结:
5.5.23版本之前,采用truncate+drop方式
5.5.23版本之后,采用drop方式
8.0版本之后,采用truncate方式
【6.pt-online-schema-change 在改表以后的删表是否有风险】
41 Query INSERT LOW_PRIORITY IGNORE INTO `tfm`.`__dbatest_new` (`id`, `k`, `c`, `pad`, `testid`) SELECT `id`, `k`, `c`, `pad`, `testid` FROM `tfm`.`dbatest` FORCE INDEX(`PRIMARY`) WHERE ((`id` >= '9999187')) AND ((`id` <= '10000000')) LOCK IN SHARE MODE /*pt-online-schema-change 26396 copy nibble*/41 Query SHOW WARNINGS41 Query SHOW GLOBAL STATUS LIKE 'Threads_running'41 Query SHOW VARIABLES LIKE 'version%'41 Query SHOW ENGINES41 Query SHOW VARIABLES LIKE 'innodb_version'41 Query ANALYZE TABLE `tfm`.`__dbatest_new` /* pt-online-schema-change */41 Query RENAME TABLE `tfm`.`dbatest` TO `tfm`.`_dbatest_old`, `tfm`.`__dbatest_new` TO `tfm`.`dbatest`41 Query DROP TABLE IF EXISTS `tfm`.`_dbatest_old`41 Query DROP TRIGGER IF EXISTS `tfm`.`pt_osc_tfm_dbatest_del`41 Query DROP TRIGGER IF EXISTS `tfm`.`pt_osc_tfm_dbatest_upd`41 Query DROP TRIGGER IF EXISTS `tfm`.`pt_osc_tfm_dbatest_ins`41 Query SHOW TABLES FROM `tfm` LIKE '\_\_dbatest\_new'42 Quit
【7.源码解读】
这部分我们从DROP TABLE 在MysQL和innodb的源码上跟踪下
嵌套了多层
mysql_rm_table
—->mysql_rm_table_no_locks
——–>ha_delete_table –>ha_innobase::delete_table
—--—–>row_drop_table_for_mysql(这个又包含了很多层函数)
1.入口函数:mysql_rm_table
bool mysql_rm_table(THD *thd,TABLE_LIST *tables, my_bool if_exists, my_bool drop_temporary){ //变量定义 //准备日志 //判断临时表 //从tdc里移除信息 //加锁//以上情节,在我们想drop表的时候,理论上不会有业务访问,移TDC等都不会有阻塞,可以忽略 error= mysql_rm_table_no_locks(thd, tables, if_exists, drop_temporary, false, false); my_ok(thd);}我们继续跟到下一个
2.mysql_rm_table_no_locks
int mysql_rm_table_no_locks(THD *thd, TABLE_LIST *tables, bool if_exists, bool drop_temporary, bool drop_view, bool dont_log_query){ //定义了一堆的变量。。 //定义了变量。。和加了一些assert断言检查 if ((drop_temporary && if_exists) || !error) { //临时表 ,这里我们不看 } else if (!drop_temporary) { non_temp_tables_count++; // 检查表锁,wait_while_table_is_used if (thd->locked_tables_mode) { // 检查表锁,wait_while_table_is_used } } error= 0; if (drop_temporary ((access(path, F_OK) && ha_create_table_from_engine(thd, db, alias)) || (!drop_view && dd_frm_type(thd, path, &frm_db_type) != FRMTYPE_TABLE))) { // 这是删除临时表的一种特殊情况 } else { char *end; if (frm_db_type == DB_TYPE_UNKNOWN) { dd_frm_type(thd, path, &frm_db_type); DBUG_PRINT("info", ("frm_db_type %d from %s", frm_db_type, path)); } table_type= ha_resolve_by_legacy_type(thd, frm_db_type); if (frm_db_type != DB_TYPE_UNKNOWN && !table_type) { my_error(ER_STORAGE_ENGINE_NOT_LOADED, MYF(0), db, table->table_name); wrong_tables.mem_free(); error= 1; goto err; } // Remove extension for delete *(end= path + path_length - reg_ext_length)= '\0'; DBUG_PRINT("info", ("deleting table of type %d", (table_type ? table_type->db_type : 0))); error= ha_delete_table(thd, table_type, path, db, table->table_name, !dont_log_query); //下面的一堆错误处理,我们也不用管了,继续跟到 ha_delete_table}3.ha_delete_table –>ha_innobase::delete_table
int ha_innobase::delete_table(/*======================*/ const char* name) /*!< in: table name */{ dberr_t err; THD* thd = ha_thd(); char norm_name[FN_REFLEN]; trx_t* trx = innobase_trx_allocate(thd); ulint name_len = strlen(name); ut_a(name_len < 1000); /* Either the transaction is already flagged as a locking transaction or it hasn't been started yet. */ ut_a(!trx_is_started(trx) || trx->will_lock > 0); /* We are doing a DDL operation. */ ++trx->will_lock; /* Drop the table in InnoDB */ err = row_drop_table_for_mysql( norm_name, trx, thd_sql_command(thd) == SQLCOM_DROP_DB, true, handler); if (err == DB_TABLE_NOT_FOUND) { //一堆错误处理....4.row_drop_table_for_mysql 一个625行的大函数
一路跟着足迹我们来到了这个巨大的函数,这个函数逻辑很复杂,,把它从上到下拆成这几块来看
row_mysql_lock_data_dictionary 加锁,锁住整个数据字典
trx_start_for_ddl 开启一个事务
row_add_table_to_background_drop_list
拼接了一个巨大的SQL,用来从系统表中清理信息
row_drop_table_from_cache 清缓存
row_drop_single_table_tablespace 删除表空间
这个又会调用 fil_delete_tablespace
buf_LRU_flush_or_remove_pages 这一步就是最容易出问题的地方,清理lru列表和缓存
os_file_delete 最终unlink文件
row_mysql_unlock_data_dictionary 释放锁 简化以后的代码如下:
{ //1. row_mysql_lock_data_dictionary(trx); locked_dictionary = true; nonatomic = true;//2. /* This function is called recursively via fts_drop_tables(). */ if (!trx_is_started(trx)) { if (!dict_table_is_temporary(table)) { trx_start_for_ddl(trx, TRX_DICT_OP_TABLE); } else { trx_set_dict_operation(trx, TRX_DICT_OP_TABLE); }//3. row_add_table_to_background_drop_list(table->name.m_name);//4. sql = "PROCEDURE DROP_TABLE_PROC () IS\n" "sys_foreign_id CHAR;\n" "table_id CHAR;\n" "index_id CHAR;\n" "foreign_id CHAR;\n" "space_id INT;\n" "found INT;\n"; //。。。这里省了很多SQL拼接语句 sql += "DELETE FROM SYS_VIRTUAL\n" "WHERE TABLE_ID = table_id;\n"; sql += "END;\n"; err = que_eval_sql(info, sql.c_str(), FALSE, trx);//5. /* Free the dict_table_t object. */ err = row_drop_table_from_cache(tablename, table, trx); if (err != DB_SUCCESS) { break; }//6. /* We can now drop the single-table tablespace. */ err = row_drop_single_table_tablespace( space_id, tablename, filepath, is_temp, is_encrypted, trx);//7.funct_exit: mem_heap_free(heap); ut_free(filepath); trx_commit_for_mysql(trx); row_mysql_unlock_data_dictionary(trx);}5.buf_LRU_flush_or_remove_pages–>buf_LRU_drop_page_hash_for_tablespace
我们把上一步提到的buf_LRU_flush_or_remove_pages单独拿出来说 它加了几层判断 ,真实调用的是buf_LRU_drop_page_hash_for_tablespace
在这里我们要首重注意的是:这一段,每当处理了num_entries>=BUF_LRU_DROP_SEARCH_SIZE次以后,就会释放锁 buf_pool_mutex_exit() 批量释放一些上页的1000个循环中收集到的ahi空间 再buf_pool_mutex_enter(buf_pool);加锁。然后goto scan_again,再重新扫一次
这个很重要,这里的锁机制保证了在BUF_LRU_DROP_SEARCH_SIZE(这个值默认是1024) 就会放掉持有的buf_pool mutex锁(注意这个操作)为什么说MySQL5.5.23以后改进了,因为它不长时间持有锁,每循环1024次以后就放掉了mutex锁,而在代码里循环1024次,是非常快的,对其他进程影响就非常非常小。但是前面还持有的数据字典锁,MDL锁并没有在这里放,但是这种大锁对普通的事务冲突不大。(所以说5.5.23以后影响小了,但并不能说完全没有影响)
且每个循环里只是做了个标记,并没有去删LRU和bufferpool,用了一个page_arr记录了要删除的pageno. 然后每1024次以后放掉了锁,同时把这1024个PAGE:buf_LRU_drop_page_hash_batch 从AHI上清理了。要批量释放的是AHI自适应哈希这部分缓存,真正的LRU和bufferpool依然不会清理,需要在以后让它自己过期了由master进程清理 这里就是我们说的lazy drop逻辑 以及我们要注意到AHI在早期版本中所有进程共用一把锁,在这里也容易产生冲突,是个风险点,直到5.7.8版本把这个锁拆分了,又前进了一大步。
/* Store the page number so that we can drop the hash index in a batch later. */ page_arr[num_entries] = bpage->id.page_no(); ut_a(num_entries < BUF_LRU_DROP_SEARCH_SIZE); ++num_entries;//如果num_entries小于BUF_LRU_DROP_SEARCH_SIZE if (num_entries < BUF_LRU_DROP_SEARCH_SIZE) { goto next_page; } /* Array full. We release the buf_pool->mutex to obey the latching order. */ buf_pool_mutex_exit(buf_pool); buf_LRU_drop_page_hash_batch( id, page_size, page_arr, num_entries); num_entries = 0; buf_pool_mutex_enter(buf_pool); goto scan_again;drop table源码小结
我们从MySQL入口处跟踪mysql_rm_table,跟踪到Innodb的buf_LRU_drop_page_hash_for_tablespace
在代码中看到了MySQL优化锁占用的处理方式,每隔BUF_LRU_DROP_SEARCH_SIZE次释放一次锁,处理AHI完再加锁,多次循环的处理
看到了LRU和Buffer在最终的函数里并没有处理删除逻辑,而是等待LRU过期后被清理
【8.dropTable最佳实践】
如果线上核心业务线有一个几个T数据的大表,被业务认为是没有用的表需要删除 ,这里有一个最保守的最佳实践
确认无人访问,这个表最近是否真的没有被访问过。
选择业务低峰时间,和这个实例上的库负责人沟通或者看性能监控,选一个低峰时间段。
检查MySQL版本 MySQL5.5.23版本以上/最好是5.7.8以上
检查架构,检查你的高可用架构是否支持这种长SQL的并发执行。
做硬链,把ibd做个硬链,延后慢慢处理。这个很重要
rename表名 如第二个测试内容,改表名不能把内存中的表缓存清理掉,但是它能保证DROP这个表,没有其他SQL也在访问这张表,没有锁冲突。
闲置表或DELETE部分数据 将表重命名后放置一段时间,等缓存失效,或提前分多批次DELETE掉数据,可以降低影响
如果mysql版本低于5.7.8.,考虑在删表前临时禁用innodb_adaptive_hash_index ,但这是个危险操作,注意影响
如果mysql版本低于8.0.高于5.5.23,把truncate分解成
create table /rename table /drop table
– done














 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









