





场景:
在Linux上运行了很多scrapy爬虫,采用了scrapy-redis方式爬取,爬虫个数多了以后内存占用太高,所以很有必要写个py脚本自动检测哪些爬虫已经爬取结束了,如果爬取结束了则停止掉该进程。
scrapy-redis方式的爬虫,怎么判断爬虫已经结束了呢,我的经验是判断redis里面是否还存在 爬虫名称 + ':requests' 这样的键,没有了则就是跑完了
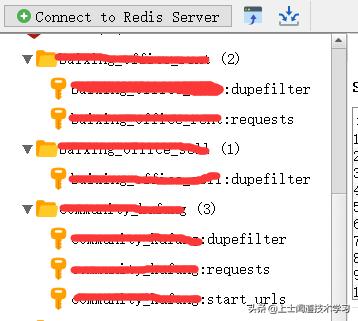
下面开始上代码:
# coding: utf-8# !/usr/bin/python3import datetimeimport loggingimport osimport signalimport sysimport redistoday = datetime.date.today().strftime("%Y-%m-%d")logging.basicConfig(level=logging.DEBUG, filename=os.path.join(os.getcwd(), 'monitor_scrapys_' + today + '.txt'), # 模式,有w和a,w就是写模式,每次都会重新写日志,覆盖之前的日志 filemode='a', # 日志格式 format= '%(process)d %(asctime)s %(filename)s %(funcName)s [line:%(lineno)d] %(levelname)s %(message)s' )class MonitorScrapys(): def __init__(self): self.redis_client_requests = redis.StrictRedis(host='192.168.0.2', port=6379, db=0, password='redispassword', decode_responses=True) # 获取爬虫有哪些,返回一个字典key是爬虫名称,value是进程号 def get_spider_names(self) -> dict: spider_names = {} out = os.popen("ps aux | grep scrapy").read() for line in out.splitlines(): spider_name = line.split('crawl')[1].replace(' ', '') # print("spider_name:{spider_name}".format(spider_name=spider_name)) pid = int(line.split()[1]) spider_names.update({spider_name: pid}) return spider_names # 检测爬虫是否已经跑完了 def check_spider_has_requests(self, spider_name: str) -> bool: requests_key = spider_name + ':requests' # 如果redis里面没有 爬虫名称 + ':requests' 这样的键,没有了则就是跑完了 return self.redis_client_requests.exists(requests_key) # 获取进程号的另一种方式 def get_spider_process(self, spider_name: str) -> int: get_pid_command = "ps -ef | grep 'crawl " + spider_name + "' | grep -v grep | awk '{ print $2 }'" pid = os.popen(get_pid_command).read() return pid # 杀掉进程 def kill_exception_spider_by_pid(self, pid: int) -> None: # 一种方式是shell的方式 # kill_command = "kill -9 {0}".format(pid) # os.system(kill_command) # 另一种方式 os.kill(pid, signal.SIGKILL)if __name__ == '__main__': monitor_scrapys = MonitorScrapys() # 获取存在哪些爬虫 spider_names = monitor_scrapys.get_spider_names() logging.info(spider_names) for key, value in spider_names.items(): spider_name = key pid = value if monitor_scrapys.check_spider_has_requests(spider_name): logging.info("{0} 的进程{1}还存在 requests还存在,说明还在跑".format(spider_name, pid)) else: monitor_scrapys.kill_exception_spider_by_pid(pid) logging.info("{0} requests不存在 进程被杀掉了".format(spider_name)) logging.info("结束啦!!!") sys.exit(0)在Linux服务器上设置个定时器运行这个py文件即可,很简单。
以上代码在Python3.5以上版本测试通过。
↓ 头条的代码排版格式有点问题,没缩进,请点击下面的“了解更多”链接可查看完整的详细。














 1696
1696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









