






目录
天小天:(一)Spark Streaming 算子梳理 — 简单介绍streaming运行逻辑
天小天:(二)Spark Streaming 算子梳理 — flatMap和mapPartitions
天小天:(三)Spark Streaming 算子梳理 — transform算子
天小天:(四)Spark Streaming 算子梳理 — Kafka createDirectStream
天小天:(五)Spark Streaming 算子梳理 — foreachRDD
天小天:(六)Spark Streaming 算子梳理 — glom算子
天小天:(七)Spark Streaming 算子梳理 — repartition算子
天小天:(八)Spark Streaming 算子梳理 — window算子
前言
本节讲解window的作用,及底层如何实现
作用
window的作用正如其名字一样,就是计算一个窗口时间内的所有RDD。那么这个窗口如何生成的那?可以先看下图。
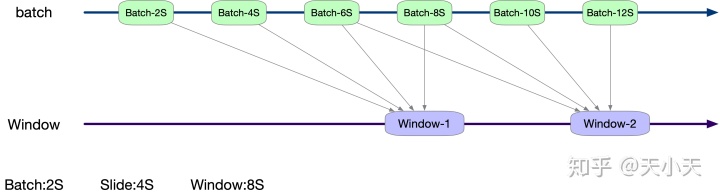
window算子有两个参数:windowDuration和slideDuration分别代表窗口时间和滑动时间。
以上图的为例,streaming的批次时间是2S,window的窗口时间为8S,滑动时间为4S。那么就是每四秒生成一个窗口,每个窗口取当前时间前8S所有批次的RDD。如果当前批次时间不是4S的倍数则此批次不执行任何操作。最终展现出来的窗口数据,就如图所示。
代码示例
一个window的算子使用方法如下代码示例:
package streaming
import org.apache.spark.{SparkConf, rdd}
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
/**
* @date 2019/01/21
*/
object Api {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("api").setMaster("local[2]")
val rddQueue = new mutable.Queue[RDD[Int]]()
//批次时间为2S
val ssc = new StreamingContext(sparkConf, Seconds(2))
// consume from rddQueue
val lines = ssc.queueStream(rddQueue)
// window
// 第一个参数为window:8S
// 第二个参数为slide:4S(选填,默认为批次时间2S)
lines.window(Seconds(8),Seconds(4)).print()
ssc.start()
// produce to rddQueue
for (i <- 1 to 30) {
rddQueue.synchronized {
rddQueue += ssc.sparkContext.makeRDD(1 to 1000, 10)
}
Thread.sleep(1000)
}
ssc.stop()
}
def iteratorAdd(input: Iterator[Int]) : Iterator[String] = {
val output = ListBuffer[String]()
for (t <- input){
output += t.toString + " map"
}
output.iterator
}
}源码解析
接下来从源码层面讲解,window是如何实现的。
DStream
首先看在DStream类中做了什么事情.
/**
* Return a new DStream in which each RDD contains all the elements in seen in a
* sliding window of time over this DStream. The new DStream generates RDDs with
* the same interval as this DStream.
* @param windowDuration width of the window; must be a multiple of this DStream's interval.
*/
def window(windowDuration: Duration): DStream[T] = window(windowDuration, this.slideDuration)
/**
* Return a new DStream in which each RDD contains all the elements in seen in a
* sliding window of time over this DStream.
* @param windowDuration width of the window; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., the interval after which
* the new DStream will generate RDDs); must be a multiple of this
* DStream's batching interval
*/
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope {
new WindowedDStream(this, windowDuration, slideDuration)
}如上所示,window有两个方法。
第一个只有一个入参windowDuration及窗口时间,并且调用下面的window方法,sllideDuretion填的为当前DStream的滑动时间,当前DStream的滑动时间如果无特殊操作的话即为批次时间。
第二个window方法接收两个入参,第一个参数为窗口时间,第二个参数为滑动时间。window方法会实例化WindowedDStream并且把两个入参原样传下去。
WindowedDStream
先来看下在实例化是做的一些检验
class WindowedDStream[T: ClassTag](
parent: DStream[T],
_windowDuration: Duration,
_slideDuration: Duration)
extends DStream[T](parent.ssc) {
if (!_windowDuration.isMultipleOf(parent.slideDuration)) {
throw new Exception("The window duration of windowed DStream (" + _windowDuration + ") " +
"must be a multiple of the slide duration of parent DStream (" + parent.slideDuration + ")")
}
if (!_slideDuration.isMultipleOf(parent.slideDuration)) {
throw new Exception("The slide duration of windowed DStream (" + _slideDuration + ") " +
"must be a multiple of the slide duration of parent DStream (" + parent.slideDuration + ")")
}
}从以上代码可以看出,在实例化时会分别检验窗口时间和滑动时间是否为批次时间的整数倍。如果不是则报错。整个实时任务停止。
compute
接下来看下compute方法的实现
override def compute(validTime: Time): Option[RDD[T]] = {
// 计算窗口的时间范围,两个入参为开始时间和结束时间
// 以上面的图为例,
// 如果当前时间为8S,批次时间为2s,窗口时间为8S,滑动时间为4s。
// 则开始时间为:当前时间 - 窗口时间 + 批次时间(8-8+2)=2s,结束时间为8S。
val currentWindow = new Interval(validTime - windowDuration + parent.slideDuration, validTime)
// 通过当前时间窗口获取要处理的RDD
val rddsInWindow = parent.slice(currentWindow)
// 把获取到的RDD集合union,供下一个算子处理
Some(ssc.sc.union(rddsInWindow))
}parent.slice
/**
* Return all the RDDs defined by the Interval object (both end times included)
*/
def slice(interval: Interval): Seq[RDD[T]] = ssc.withScope {
// 把时间范围拆成开始时间和结束时间两个参数
slice(interval.beginTime, interval.endTime)
}
/**
* Return all the RDDs between 'fromTime' to 'toTime' (both included)
*/
def slice(fromTime: Time, toTime: Time): Seq[RDD[T]] = ssc.withScope {
// 判断DStream是否已经实例化。
// 由于这是一个public方法,可以被用户程序调用。
// 并且次方法并不会实例化DStream,所以需要此检验,防止用户在没有实例化DStream是调用此方法。
if (!isInitialized) {
throw new SparkException(this + " has not been initialized")
}
// 校验结束时间-实时流开始时间是否为批次时间的倍数。
// 注意这里的slideDuration不是window入参的slideDuration,而是实施任务的批次时间。
// 此处的作用是防止用户传入的时间范围不是批次时间的整数倍,
// 虽然目前此方法只有window一个函数在用,并且window已经通过检验窗口时间和滑动时间必须为批次时间的整数倍,来保证此处判断必然为true.
// 但是并不排除用户会用到这个方法,所以才有了这个校验
val alignedToTime = if ((toTime - zeroTime).isMultipleOf(slideDuration)) {
toTime
} else {
logWarning(s"toTime ($toTime) is not a multiple of slideDuration ($slideDuration)")
toTime.floor(slideDuration, zeroTime)
}
// 此处检验窗口的开始时间,逻辑即原理同toTime。
val alignedFromTime = if ((fromTime - zeroTime).isMultipleOf(slideDuration)) {
fromTime
} else {
logWarning(s"fromTime ($fromTime) is not a multiple of slideDuration ($slideDuration)")
fromTime.floor(slideDuration, zeroTime)
}
logInfo(s"Slicing from $fromTime to $toTime" +
s" (aligned to $alignedFromTime and $alignedToTime)")
// 从开始时间到结束时间以批次时间切分,输出时间集合。并且用这个时间去获取RDD,并返回RDD集合。
alignedFromTime.to(alignedToTime, slideDuration).flatMap { time =>
if (time >= zeroTime) getOrCompute(time) else None
}
}通过代码及注释可以详细了解slice做的事情。
无效批次过滤
以上介绍了每个窗口是如何获取RDD的,但是当遇到不需要执行window操作的批次(如图中10S的批次)是如何过滤这个批次的那。
先看下如下代码:
lines.window(Seconds(8),Seconds(4)).map(_).print()这段代码就是代码示例中的核心代码,只不过为例说明方便在window算子后面多加了一个map算子。
如果看过map算子的源码,会知道其实例化的是MappedDStream类,其compute方法会执行如下代码:
override def compute(validTime: Time): Option[RDD[U]] = {
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
}其中在此示例中parent为WindowedDStream,getOrCompute为获取RDD的方法,validTime为当前批次时间。如果用validTime获取不到RDD的话则此批次就会被过滤。
那么我们就看getOrCompute是如何实现的
/**
* Get the RDD corresponding to the given time; either retrieve it from cache
* or compute-and-cache it.
*/
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
// isTimeValid 为我们目前唯一需要关注的代码
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
SparkHadoopWriterUtils.disableOutputSpecValidation.withValue(true) {
compute(time)
}
}
rddOption.foreach { case newRDD =>
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}从以上代码可以看出如果isTimeValid方法返回false的话,则不会返回任何RDD。
接下来看下isTimeValid的实现
/** Checks whether the 'time' is valid wrt slideDuration for generating RDD */
private[streaming] def isTimeValid(time: Time): Boolean = {
// 判断是否被实例化,这段在此文章不需要关注。
if (!isInitialized) {
throw new SparkException (this + " has not been initialized")
} else if (time <= zeroTime || ! (time - zeroTime).isMultipleOf(slideDuration)) {
// 此处判断当前批次减去实时任务开始时间是否为slideDuration的倍数。
// 其中slideDuration在这里为window的滑动时间。
// 如果time为10S,zeroTime为0S,slideDuration为4S
// 则此处if判断为true,则isTimeValid方法返回false
logInfo(s"Time $time is invalid as zeroTime is $zeroTime" +
s" , slideDuration is $slideDuration and difference is ${time - zeroTime}")
false
} else {
logDebug(s"Time $time is valid")
true
}
}从以上代码中可以看出,在10S的批次代码会执行到第二个if判断,并发会false。则此批次被过滤。
总结
至此,window的实现基本讲完了。其中union可以看做一个单独的算子,所以并没有在这里具体讲解。
源码地址
源码地址















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









