








简介中最为重要就是说了有监督算法和无监督算法的区别,为什么有监督算法不适合于关键词提取进行了特别说明。
TF-IDF学习笔记:
知乎视频www.zhihu.com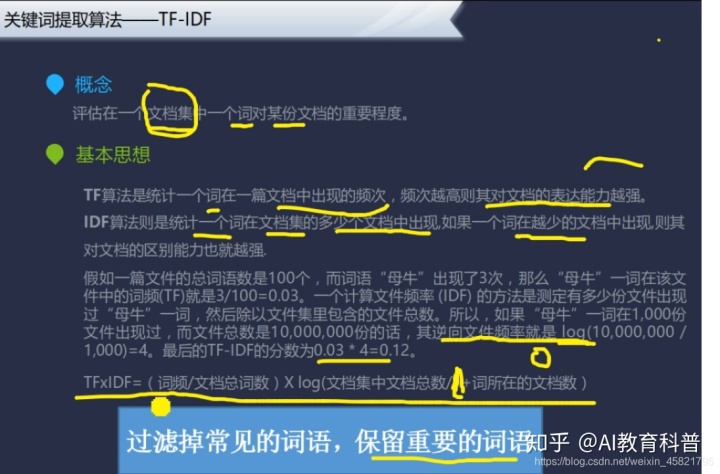
其实这张PPT核心就是底部这句话,过滤掉常见的词语,保留得要的词语。
TextRank学习笔记:
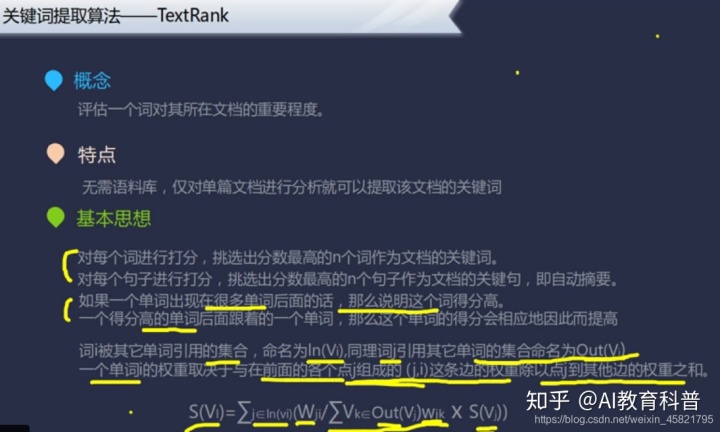
这张PPT主要讲得就是底部这个公式,理解了这个公式就理解整个PPT了,说白了就是一个词I被其它词J引用合计得到一个分数除以其它词J引用除词I之外即词K的分数之和,再乘以词J本身的得分,这样就得到了词I的得分。
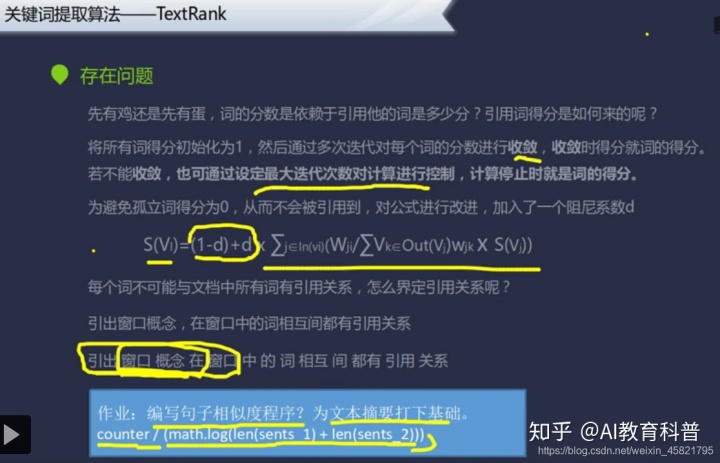
这张PPT最核心就是要理解收敛,个人认为之所以能够收敛是因为现实世界中这些词的得分就是有的,多次迭代其实是个学习的过程而已,就如同HMM也是通过统计频率来得到三个概率矩阵一样。
而窗口概念的引出使得计算成为可能。
主题模型学习笔记:
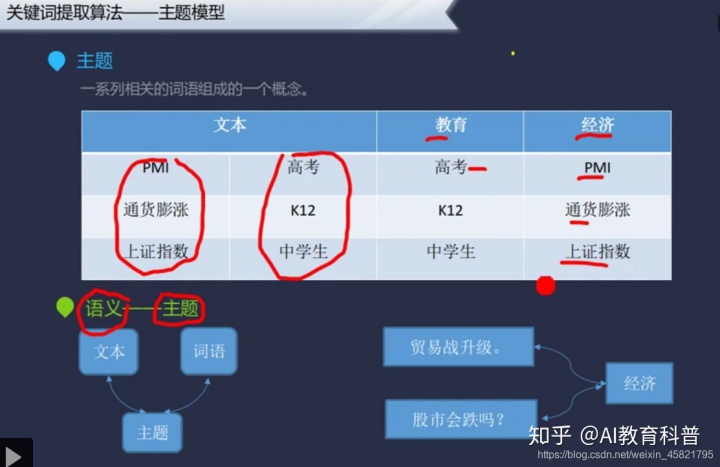
主题模型与TF-IDF,TextRank不同之处就是在于不是根据词语在文档中出现的次数来确定关键词。

基本思路核心在于理解P(词语|文档)是怎么来的,个人理解其实是两个矩阵相乘,把主题这一维约去了。
主题模型核心代码讲解:
个人认为这块的代码逻辑并不复杂,但是首先要对gensim中corpora, models这两个包的作用要明白,而这个在视频中没有多讲,需要自学相关知识,我在学习这块知识所花费了有一天时间。
在此基础上跑通并看懂代码没有什么难度,最难的一句代码我认为就是这句了
for k, v in sorted(sim_dic.items(), key=functools.cmp_to_key(cmp), reverse=True)[:self.keyword_num]:
而最核心的就是 key=functools.cmp_to_key(cmp)的理解,cmp_to_key 将比较函数转换为关键字函数可以用于sorted
TF-IDF代码学习笔记:
学习了主题模型核心代码,再学习这块代码根本无压力,其编程思路就是TF-IDF的公式,先求TDF的值,再注TF值,然后在get_tfidf(self)中计算TF-IDF,求取关键词。
TextRank算法代码学习笔记:
这节课其实主要是讲解了jibea的analyse.textrank的源码,这个源码是相当复杂的,视频只讲解了7分钟,但是我根据视频进行调试跟踪却足足花了有一天的时间才学完,个人认为要搞懂TextRank算法对于看懂代码非常重要,结合前面讲的算法PPT,再来学习此代码会使学习效率大增,我开始就是走了弯路,否则也不会花一天时间来搞定这些代码。















 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









