






本文将介绍我是如何在python爬虫里面一步一步踩坑,然后慢慢走出来的,期间碰到的所有问题我都会详细说明,让大家以后碰到这些问题时能够快速确定问题的来源,后面的代码只是贴出了核心代码,更详细的代码暂时没有贴出来。
流程一览
首先我是想爬某个网站上面的所有文章内容,但是由于之前没有做过爬虫(也不知道到底那个语言最方便),所以这里想到了是用python来做一个爬虫(毕竟人家的名字都带有爬虫的含义),我这边是打算先将所有从网站上爬下来的数据放到ElasticSearch里面, 选择ElasticSearch的原因是速度快,里面分词插件,倒排索引,需要数据的时候查询效率会非常好(毕竟爬的东西比较多),然后我会将所有的数据在ElasticSearch的老婆kibana里面将数据进行可视化出来,并且分析这些文章内容,可以先看一下预期可视化的效果(上图了),这个效果图是kibana6.4系统给予的帮助效果图(就是说你可以弄成这样,我也想弄成这样)。后面我会发一个dockerfile上来(现在还没弄)。

环境需求
- Jdk (Elasticsearch需要)
- ElasticSearch (用来存储数据)
- Kinaba (用来操作ElasticSearch和数据可视化)
- Python (编写爬虫)
- Redis (数据排重)
这些东西可以去找相应的教程安装,我这里只有ElasticSearch的安装点我获取安装教程
第一步,使用python的pip来安装需要的插件(第一个坑在这儿)
tomd:将html转换成markdown
pip3 install tomdredis:需要python的redis插件
pip3 install redisscrapy:框架安装(坑)
首先我是像上面一样执行了
pip3 install scrapy然后发现缺少gcc组件 error: command 'gcc' failed with exit status 1
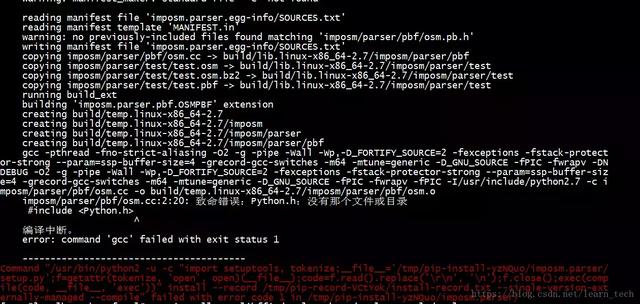
然后我就找啊找,找啊找,最后终于找到了正确的解决方法(期间试了很多错误答案)。最终的解决办法就是使用yum来安装python34-devel, 这个python34-devel根据你自己的python版本来,可能是python-devel,是多少版本就将中间的34改成你的版本, 我的是3.4.6
yum install python34-devel安装完成过后使用命令 scrapy 来试试吧。
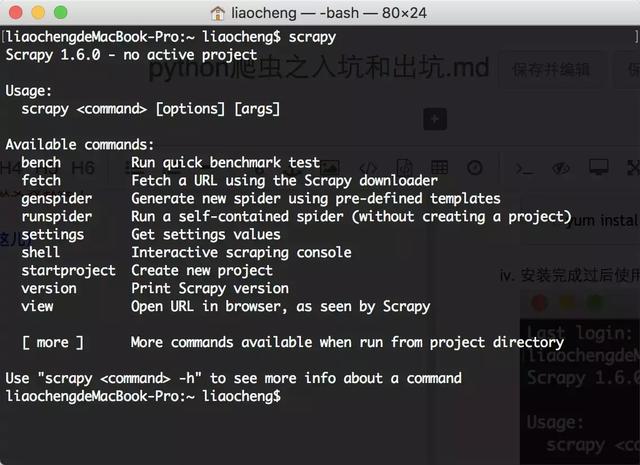
第二步,使用scrapy来创建你的项目
输入命令scrapy startproject scrapyDemo, 来创建一个爬虫项目
liaochengdeMacBook-Pro:scrapy liaocheng$ scrapy startproject scrapyDemoNew Scrapy project 'scrapyDemo', using template directory '/usr/local/lib/python3.7/site-packages/scrapy/templates/project', created in:/Users/liaocheng/script/scrapy/scrapyDemoYou can start your first spider with:cd scrapyDemoscrapy genspider example example.comliaochengdeMacBook-Pro:scrapy liaocheng$ 使用genspider来生成一个基础的spider,使用命令scrapy genspider demo juejin.im, 后面这个网址是你要爬的网站,我们先爬自己家的
liaochengdeMacBook-Pro:scrapy liaocheng$ scrapy genspider demo juejin.imCreated spider 'demo' using template 'basic'liaochengdeMacBook-Pro:scrapy liaocheng$ 查看生成的目录结构
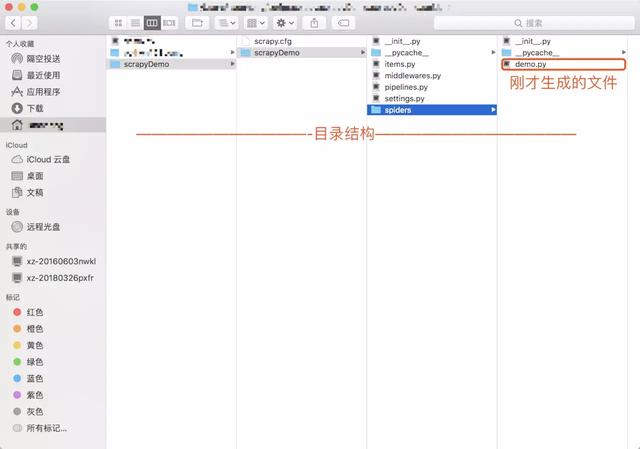
第三步,打开项目,开始编码
查看生成的的demo.py的内容
# -*- coding: utf-8 -*-import scrapyclass DemoSpider(scrapy.Spider): name = 'demo' ## 爬虫的名字 allowed_domains = ['juejin.im'] ## 需要过滤的域名,也就是只爬这个网址下面的内容 start_urls = ['https://juejin.im/post/5c790b4b51882545194f84f0'] ## 初始url链接 def parse(self, response): ## 如果新建的spider必须实现这个方法 pass可以使用第二种方式,将start_urls给提出来
# -*- coding: utf-8 -*-import scrapyclass DemoSpider(scrapy.Spider): name = 'demo' ## 爬虫的名字 allowed_domains = ['juejin.im'] ## 需要过滤的域名,也就是只爬这个网址下面的内容 def start_requests(self): start_urls = ['http://juejin.im/'] ## 初始url链接 for url in start_urls: # 调用parse yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): ## 如果新建的spider必须实现这个方法 pass编写articleItem.py文件(item文件就类似java里面的实体类)
import scrapyclass ArticleItem(scrapy.Item): ## 需要实现scrapy.Item文件 # 文章id id = scrapy.Field() # 文章标题 title = scrapy.Field() # 文章内容 content = scrapy.Field() # 作者 author = scrapy.Field() # 发布时间 createTime = scrapy.Field() # 阅读量 readNum = scrapy.Field() # 点赞数 praise = scrapy.Field() # 头像 photo = scrapy.Field() # 评论数 commentNum = scrapy.Field() # 文章链接 link = scrapy.Field()编写parse方法的代码
def parse(self, response): # 获取页面上所有的url nextPage = response.css("a::attr(href)").extract() # 遍历页面上所有的url链接,时间复杂度为O(n) for i in nextPage: if nextPage is not None: # 将链接拼起来 url = response.urljoin(i) # 必须是掘金的链接才进入 if "juejin.im" in str(url): # 存入redis,如果能存进去,就是一个没有爬过的链接 if self.insertRedis(url) == True: # dont_filter作用是是否过滤相同url true是不过滤,false为过滤,我们这里只爬一个页面就行了,不用全站爬,全站爬对对掘金不是很友好,我么这里只是用来测试的 yield scrapy.Request(url=url, callback=self.parse,headers=self.headers,dont_filter=False) # 我们只分析文章,其他的内容都不管 if "/post/" in response.url and "#comment" not in response.url: # 创建我们刚才的ArticleItem article = ArticleItem() # 文章id作为id article['id'] = str(response.url).split("/")[-1] # 标题 article['title'] = response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > h1::text").extract_first() # 内容 parameter = response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > div.article-content").extract_first() article['content'] = self.parseToMarkdown(parameter) # 作者 article['author'] = response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > div:nth-child(6) > meta:nth-child(1)::attr(content)").extract_first() # 创建时间 createTime = response.css("#juejin > div.view-container > main > div > div.main-area.article-area.shadow > article > div.author-info-block > div > div > time::text").extract_first() createTime = str(createTime).replace("年














 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









