





一段很简单的代码:
<template>
<div>
<div>
aaa
<span> bbb {{ name }} </span>
</div>
<div>
ccc
{{ name }}
</div>
</div>
</template>
<script>
export default {
data() {
return {
name: 'ddd'
};
}
};
</script>渲染出来的页面是这样子的:

页面的DOM结构是这样的:

我们会发现,渲染的结果中有很多空格,当然,上面的代码写的是刻意为之的,实际上可能并不会这样写,但是有些空格是避免不了的,尤其是换行的时候,比如这种
<div id="aaa" class="bbb ccc ddd" @click="add">
{{ name }}
</div>渲染出来是这样的

我用的是prettier来自动格式化,如果一行太长的时候,就会自动换行,插件会处理成这样:
<div id="aaa" class="bbb ccc ddd" @click="add">{{
name
}}</div>但是,真的好丑啊……强迫症表示不能忍
一般来说渲染成上面那样也没什么问题,但有时候会影响到样式,比如最前面那个例子,里面有空格,也许某些时候我并不想要空格,并且我不想把代码改的很丑
然后我找了挺久,并没有找到解决的办法,下面是vue-template-compiler的配置
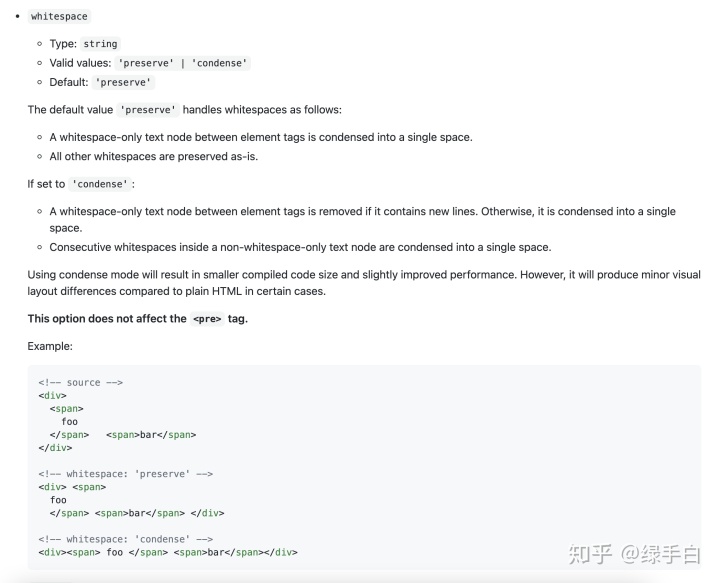
标签之间、标签和内容之间还是有空格,并没有我想要的选项
于是我又去翻了翻react,发现了这个:

啊哈,这不就是我想要的效果吗,可惜Vue这我没找到。
于是开始自己找方法,怎么办呢?
.vue文件是不能直接在浏览器中跑的,它有个编译的过程,将模版代码编译成render函数,既然vue-template-compiler中没有这个配置,那自己写一个?
于是就把vue-template-compiler的源码扒出来看了看,发现它是这样处理的:
function parseHTML (html, options) {
var stack = [];
var expectHTML = options.expectHTML;
var isUnaryTag$$1 = options.isUnaryTag || no;
var canBeLeftOpenTag$$1 = options.canBeLeftOpenTag || no;
var index = 0;
var last, lastTag;
while (html) {
last = html;
// Make sure we're not in a plaintext content element like script/style
if (!lastTag || !isPlainTextElement(lastTag)) {
var textEnd = html.indexOf('<');
if (textEnd === 0) {
// Comment:
if (comment.test(html)) {
var commentEnd = html.indexOf('-->');
if (commentEnd >= 0) {
if (options.shouldKeepComment) {
options.comment(html.substring(4, commentEnd), index, index + commentEnd + 3);
}
advance(commentEnd + 3);
continue
}
}
// http://en.wikipedia.org/wiki/Conditional_comment#Downlevel-revealed_conditional_comment
if (conditionalComment.test(html)) {
var conditionalEnd = html.indexOf(']>');
if (conditionalEnd >= 0) {
advance(conditionalEnd + 2);
continue
}
}
// Doctype:
var doctypeMatch = html.match(doctype);
if (doctypeMatch) {
advance(doctypeMatch[0].length);
continue
}
// End tag:
var endTagMatch = html.match(endTag);
if (endTagMatch) {
var curIndex = index;
advance(endTagMatch[0].length);
parseEndTag(endTagMatch[1], curIndex, index);
continue
}
// Start tag:
var startTagMatch = parseStartTag();
if (startTagMatch) {
handleStartTag(startTagMatch);
if (shouldIgnoreFirstNewline(startTagMatch.tagName, html)) {
advance(1);
}
continue
}
}
var text = (void 0), rest = (void 0), next = (void 0);
if (textEnd >= 0) {
rest = html.slice(textEnd);
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// < in plain text, be forgiving and treat it as text
next = rest.indexOf('<', 1);
if (next < 0) { break }
textEnd += next;
rest = html.slice(textEnd);
}
text = html.substring(0, textEnd);
}
if (textEnd < 0) {
text = html;
}
if (text) {
advance(text.length);
}
if (options.chars && text) {
options.chars(text, index - text.length, index);
}
} else {
var endTagLength = 0;
var stackedTag = lastTag.toLowerCase();
var reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([sS]*?)(</' + stackedTag + '[^>]*>)', 'i'));
var rest$1 = html.replace(reStackedTag, function (all, text, endTag) {
endTagLength = endTag.length;
if (!isPlainTextElement(stackedTag) && stackedTag !== 'noscript') {
text = text
.replace(/<!--([sS]*?)-->/g, '$1') // #7298
.replace(/<![CDATA[([sS]*?)]]>/g, '$1');
}
if (shouldIgnoreFirstNewline(stackedTag, text)) {
text = text.slice(1);
}
if (options.chars) {
options.chars(text);
}
return ''
});
index += html.length - rest$1.length;
html = rest$1;
parseEndTag(stackedTag, index - endTagLength, index);
}
if (html === last) {
options.chars && options.chars(html);
if (process.env.NODE_ENV !== 'production' && !stack.length && options.warn) {
options.warn(("Mal-formatted tag at end of template: "" + html + """), { start: index + html.length });
}
break
}
}
// Clean up any remaining tags
parseEndTag();
function advance (n) {
index += n;
html = html.substring(n);
}
function parseStartTag () {
var start = html.match(startTagOpen);
if (start) {
var match = {
tagName: start[1],
attrs: [],
start: index
};
advance(start[0].length);
var end, attr;
while (!(end = html.match(startTagClose)) && (attr = html.match(dynamicArgAttribute) || html.match(attribute))) {
attr.start = index;
advance(attr[0].length);
attr.end = index;
match.attrs.push(attr);
}
if (end) {
match.unarySlash = end[1];
advance(end[0].length);
match.end = index;
return match
}
}
}
……
}
通过index和advance函数来记录解析的位置和对模版字符串的截取,那么照着它的样子,把截取内容中首尾的空格删掉不就好了?
于是我加了个这个:
var newTemplate = '';
function advanceTemplate(n) {
const templatePart = html.substring(0, n).trim();
newTemplate += templatePart;
index += n;
html = html.substring(n);
}
这样在需要截取的地方,将原来的内容存下来就好了
稍微弄了下,变成了这样:vue-template-space
使用:
npm install vue-template-space添加一下配置
// vue.config.js
chainWebpack: config => {
config.module
.rule('vue')
.use('vue-template-space')
.loader('vue-template-space')
.end();
}
效果大概是这样:
<!-- source -->
<template>
<div>
<div> aaa
<span>
bbb {{ name }} </span>
</div>
<div>
ccc
{{ name }}
</div>
</div>
</template>
<!-- result -->
<template><div><div>aaa<span>bbb {{ name }}</span></div><div>ccc
{{ name }}</div></div></template>相当于
模版 -> 编译 -> render函数
变成
模版 -> 删除模版空格 -> 编译 -> render函数
(原文件不会变化)
最后:
可能会有bug(逃
以及
如果有什么更好的删除空格的方法,或者vue为啥不提供这个选项的原因,烦请告知,不胜感激















 3860
3860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









