







copy-on-write 是计算机领域相当经典的优化思想,当然你如果问一个Java 开发者 copy-on-write 有什么作用?他们往往第一反应就是:优雅地解决读多写少场景下的并发问题。
确实,众所周知,多线程环境下会出现 data race 的问题,我们以 Java 中的 ArrayList 为例,ArrayList 本身是不保证线程安全的,通常情况,要保证多线程环境下不出问题,就要给 ArrayList 加上读写锁,读要读锁,写要写锁,读与读之间不互斥,读与写之间要互斥,写与写之间也要互斥。
然而,对于读多写少的场景来说,频繁地读取必然导致频繁地加锁,而与写互斥的情况却很少出现,这似乎有点不『经济』,这时候 CopyOnWriteArrayList(以下简称 COWList) 就登场了。COWList 的总体设计思想是在读的过程中去掉了锁,而在写的过程中则需要引入互斥锁,但是这个锁不会影响到读本身,也就进一步释放了读的性能瓶颈,这里具体怎么做到的呢?来看看代码:
(只截取了部分 CopyOnWriteArrayList 代码片段 )
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
/**
* {@inheritDoc}
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
return get(getArray(), index);
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}代码中可以看到三个重要的关键点:
- COWList 读操作是无锁的;
- COWList 写与写之间是互斥的;
- 底层持有的数组变量 array 是通过 volatile 修饰的。
JMM 的 happens-before 语义保证了 volatile 变量的内存可见性,这使得任意线程在任意时间点读取 array 变量的时候都能保证读到最新值;而写的过程中,除了互斥保证以外,还需要将 array 数组拷贝一个副本出来,对副本进行修改后再将该副本的引用赋值给 array 变量,以替换原先的引用,而这个替换过程是原子性的。
不错,copy-on-write 在这里确实解决了读多写少的并发痛点,但这很容易将开发者引入一个思维误区,会先入为主地认为 copy-on-write 只有在并发场景才受用,其实不然。
操作系统领域早早就已经将 copy-on-write 优化策略利用了起来,当然与上述 COWList 不同的是,OS 领域 copy-on-write 核心思想则是 lazy copy。我们知道应用程序通常是不会直接和物理内存打交道的,所谓的内存寻址只是针对虚拟内存空间而言,而从虚拟内存到物理内存的映射则需要借助 MMU (存储管理单元)实现。
以 linux 为例,当通过系统调用(syscall)从一个已经存在的进程 P1 中 fork 出一个子进程 P2,OS会为 P2 创建一套与 P1 保持一致映射关系的虚拟内存空间,从而实现了 P1 和 P2 对物理空间的共享,这样做的目的是为了减少对物理内存的消耗,毕竟两份完全一样的数据没必要额外占用多一倍物理内存空间。此后,如果 P1 或 P2 需要更改某段内存,则须为其按需分配额外物理内存,将共享数据拷贝出来,供其修改,这里注意,无论父还是子进程,只要有修改,就会涉及到内存拷贝,这里的影响粒度范围是内存页,linux 内存页大小为 4KB。
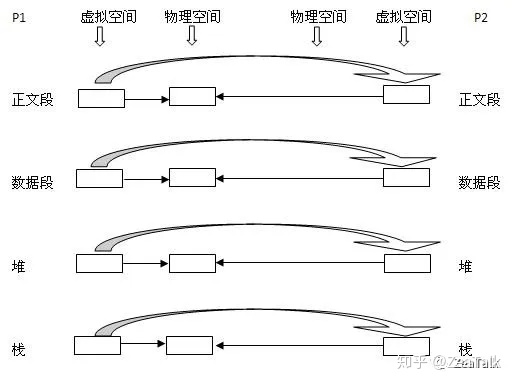
通过OS copy-on-write 的过程我们可以总结出两个重要的特性:
- 父子进程的内存共享的数据仅仅是fork那一时间点的数据,fork 后的数据不会有任何共享;
- 所谓 lazy copy,就是在需要修改的时候拷贝一个副本出来,如果没有任何改动,则不会占用额外的物理内存。
基于这两个特性我们可以知道,copy-on-write 的在 OS 领域的设计初衷可能并非为了解决并发读的效率问题,参考维基[1]对 copy-on-write 的定义:
写入时复制(英语:Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。
很明显,如若我们利用 OS 这层优化策略,我们将大大减少了对物理内存的消耗,同时也提高了创建进程的效率,因为 OS 一开始并不需要给 fork 出来的新进程分配物理内存空间。因此 copy-on-write 非常适合内存快照的 dump,例如 redis 的 rdb dump。至于为什么合适,我认为有如下几点:
- 考虑到 dump 的对象理应是某一时间点的内存快照信息,根据特性1,这里完美契合;
- dump 内存过程是耗时的,务必不能占用主线程资源,应当合理利用 CPU 多线程的优势,这里 fork 进程去处理 dump 任务本身就是理所应当的;
- 如果内存快照本身已经占用了50%以上的内存资源,如果不采用 copy-on-write 策略,显然无法 fork 出任何进程,因为没有足够的物理内存可以分配。
综上,无论 redis 还是数据库,或是其他中间件,采用 OS 层面 copy-on-write 优化策略实现 dump 内存快照功能都是非常合理的,或许会问为什么不用多线程的方式去做,而用多进程?
copy-on-write 只是一套思想理念,至于你用进程和线程,我相信实现效果上并无差别,唯一的差别是你通过系统调用直接 fork 出来的进程就已经囊括了 copy-on-write 优化策略了,而你却尝试用线程去实现一套与 OS 层面一样的逻辑,这又是何苦呢?
参考资料:
[1]https://zh.wikipedia.org/wiki/%E5%AF%AB%E5%85%A5%E6%99%82%E8%A4%87%E8%A3%BD















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









