






 本文介绍如何使用DS9查看数据,并通过Python分析JSON文件中时区出现的频率。首先,从链接获取数据,将JSON转为DataFrame,处理缺失值,然后统计并展示出现最多的前十个时区。接着,文章探讨了在Windows和非Windows环境下时区的分布情况,对环境列过滤NaN值后,展示不同环境下各时区的出现次数和占比。
本文介绍如何使用DS9查看数据,并通过Python分析JSON文件中时区出现的频率。首先,从链接获取数据,将JSON转为DataFrame,处理缺失值,然后统计并展示出现最多的前十个时区。接着,文章探讨了在Windows和非Windows环境下时区的分布情况,对环境列过滤NaN值后,展示不同环境下各时区的出现次数和占比。
数据来源:https://pan.baidu.com/s/133OljtVd4ajMA84aJ0Uujg#list/path=%2F
密码:56y6
第一部分:求出现次数最多的前十个时区
思路:将原json文件转换成python字典对象,并创建DataFrame,对数据进行处理后(空值、NaN值),根据‘tz’字段统计时区出现次数
step1
import json
example=[json.loads(line) for line in open(r'C:UsersAdministratorDownloadspydata-book-2nd-editiondatasetsbitly_usagovexample.txt')]
#将json字符串转换成python字典对象
import pandas as pd
frame=pd.DataFrame(example)
#根据example创建DataFramestep2
frame1=frame1.fillna('Missing')
#用missing填充'frame1中的NaN值
frame1[frame1=='']='Unknown'
#用'Unknown'填充frame1中的空值step3
tz_counts = frame1['tz'].value_counts()
tz_counts[:10]
America/New_York 1251
Unknown 521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
Missing 120
Europe/London 74
Asia/Tokyo 37
Pacific/Honolulu 36
Europe/Madrid 35
#利用value_counts()函数,列出时区列出现次数最多的前十位step4 Seaborn
import seaborn as sns
sns.barplot(x=data.values,y=data.index)
#通过Seaborn绘制时区列出现次数最多的前十位的柱形图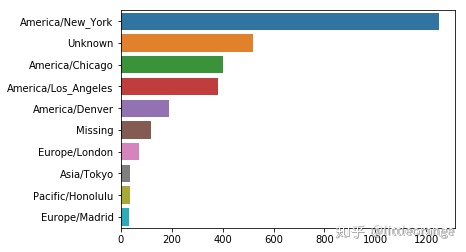
第二部分 求Windows和非Windows环境下出现次数最多的前十个时区
思路:‘a’列包含了具体的环境,过滤NaN值后,求得不同环境下,各时区的出现次数及占比数
frame2=frame[frame['a'].notnull()]
#布尔表达式为过滤'a'列为NaN值的所在行,返回新的数据。如果没有过滤,之后对系统的区分,会存在偏差
import numpy as np
frame2['os']=np.where(frame2['a'].str.contains('Windows'),'Windows','Not Windows')
#如果'a'列的字段中含有Windows,则返回'Windows',否则返回'Not Windows',此数组为frame2的新增'os'列.
frame2=frame2.groupby(['tz','os']).size().unstack().fillna(0)
#根据是否为Windows对时区出现次数进行分类计数,并重塑,在结果中用0代替NaN值
frame2[:10]
os Not Windows Windows
tz
245.0 276.0
Africa/Cairo 0.0 3.0
Africa/Casablanca 0.0 1.0
Africa/Ceuta 0.0 2.0
Africa/Johannesburg 0.0 1.0
Africa/Lusaka 0.0 1.0
America/Anchorage 4.0 1.0
America/Argentina/Buenos_Aires 1.0 0.0
America/Argentina/Cordoba 0.0 1.0
America/Argentina/Mendoza 0.0 1.0
#查看结果
index=frame2.sum(1).argsort()[-10:]
index
tz
Europe/Sofia 35
Europe/Stockholm 78
Europe/Uzhgorod 96
Europe/Vienna 59
Europe/Vilnius 77
Europe/Volgograd 15
Europe/Warsaw 22
Europe/Zurich 12
Pacific/Auckland 0
Pacific/Honolulu 29
#选取总和排名前十的时区
注:argsort()函数将数据从小到大排列,提取其对应的索引
frame3=frame2.take(index)
frame3
os Not Windows Windows
tz
America/Sao_Paulo 13.0 20.0
Europe/Madrid 16.0 19.0
Pacific/Honolulu 0.0 36.0
Asia/Tokyo 2.0 35.0
Europe/London 43.0 31.0
America/Denver 132.0 59.0
America/Los_Angeles 130.0 252.0
America/Chicago 115.0 285.0
245.0 276.0
America/New_York 339.0 912.0
frame3=frame3.stack()
frame3.name='total'
frame3=frame3.reset_index()
#添加索引和列名,重置索引
frame3[:10]
tz os total
0 America/Sao_Paulo Not Windows 13.0
1 America/Sao_Paulo Windows 20.0
2 Europe/Madrid Not Windows 16.0
3 Europe/Madrid Windows 19.0
4 Pacific/Honolulu Not Windows 0.0
5 Pacific/Honolulu Windows 36.0
6 Asia/Tokyo Not Windows 2.0
7 Asia/Tokyo Windows 35.0
8 Europe/London Not Windows 43.0
9 Europe/London Windows 31.0
sns.barplot(x='total',y='tz',hue='os',data=frame3)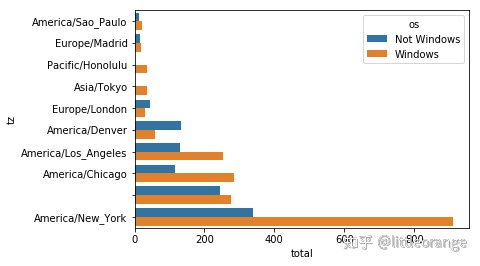
def norm_total(group):
group['normed_total'] = group.total / group.total.sum()
return group
results = count_subset.groupby('tz').apply(norm_total)
sns.barplot(x='normed_total', y='tz', hue='os', data=results)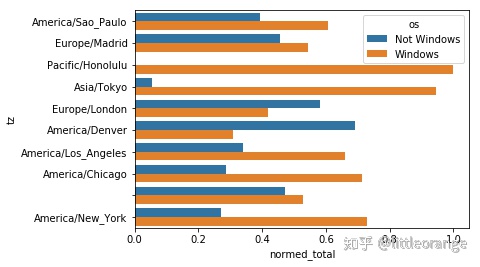


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









