





上次我们讨论了编译器前端的语法与词法定义和分析,那么从这篇开始我们就要实际动手写一些代码啦。在开始写代码之前,前端我们还有最后一个概念要一起来了解一下:语义分析。语义分析:
语义分析可能是整个前端里面最复杂也是最重要的一个部分了, 这里是我们使用前两步产生的结果来真正的理解源程序所要表达的功能。 那么通过上一步的语法分析,我们已经可以把源输入的程序解析成一条一条的语法规则,我们则可以根据这些不同的语法规则来触发语义行为(Semantic Action) 通过这些语义行为我们来根据不同的语法规则进行含义解析。中间表达 (Intermediate Representation)/ IR:
这里我们插入一个概念叫做中间表达。 这个大概是编译器的最核心的思想,也就是通过一层一层的中间表达,把源语言逐步向目标语言转化。AST 抽象语法树 (Abstract Syntax Tree):
这是我们在这篇教程里第一个自己建立的中间表达形式,我们通常叫它抽象语法 (AST) 。那么AST是做什么的呢? 我们为什么需要它呢?
在对输入程序进行分析之后,我们就可以开始把它转化成一种更适合处理的数据结构了,由于程序本身的上下关联性,这个数据结构很难不是一棵树。这个转换之后我们依然保留了源程序的所有结构。也可以说基本是没一个语句都会对应一个或多个AST Node。
那么我们通过一个例子来了解一下AST吧, 这里我们继续用上面那段程序来说吧~
如果不记得之前说的程序的话,这里再列一下上面那段程序
main let
var name : int := 1;
in begin
name := name + 1;
printi(name);
end; 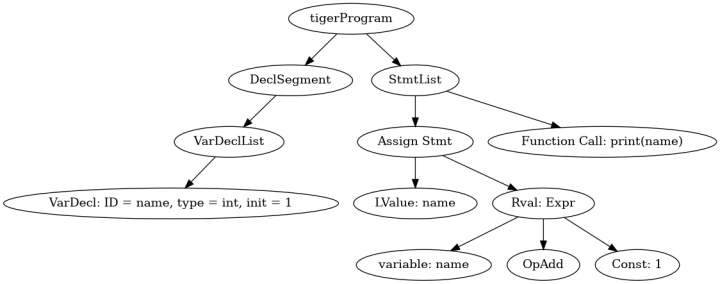
那么我们来看上面这个抽象语法树,首相最上面是树的入口,也就是tigerProgram, 这个tigerProgram就是我们整个程序的入口了。那么我们之前看到的语法里面,我们知道每一个tigerProgram都是由一个DeclSegment 和一个 StmtList构成的。 那么对应的我们也可以在AST中看到这两个组成部分。左面的DeclSegment 和右面的 StmtList。可能敏锐的你已经发现了,这个虽然依然保留着程序的结构,但是已经不再具有Token等直接从源程序引用的部分了。所以自然而然这里不重要的那些用来标记程序各个部分的关键字【例如main, let, var等】也就被省略了。动手实践
上面说了那么多理论,相信很多朋友已经等不急要写一些代码来开动啦!这就是今天的动手部分啦,一起动手写Parser吧。 我这里用Antlr来做例子,当然你也可以使用其他的Parser Generator 比如 Flex+Yacc/Bison 或者Pest的Yacc。 选择Antlr作为例子是因为Antlr支持为C++, Java ,Python等多种语言生成代码,可能会方便大家学习。
(可能有些人会说用一个生成的语法分析器分析速度会比较慢,而且也会提供相对比较弱的错误提示,但是我觉得作为一个学习用的编译器,通过使用这样的工具来节省宝贵的时间是相当好的办法。)
首先我在这里把我们这个程序的语法贴出来,如果使用的不是Antlr的话就可能需要自己转换一下。
grammar Tiger;
@header {
package org.codetector.llvm.tigerc.parser;
}
tigerProgram : KeywordMain KeywordLet declSegment KeywordIn KeywordBegin stmtList KeywordEnd;
declSegment: (typeDecl | varDecl | funcDecl)*;
typeDecl: KeywordType ID Equals type Semicolon;
type: typeId
| KeywordArray LBracket IntLit RBracket KeywordOf typeId
| ID;
typeId: KeywordInt | KeywordFloat;
varDecl: KeywordVar idList Colon type optionalInit Semicolon;
idList: ID (Comma ID)*;
optionalInit: | OpAssign constant;
funcDecl: KeywordFunction ID LParen paramList RParen (retType)? KeywordBegin stmtList KeywordEnd Semicolon;
paramList: | param (Comma param)*;
retType: Colon type;
param: ID Colon type;
stmtList: (stmt)*;
stmt: ifStmt
| assignStmt
| callStmt
| whileStmt
| forStmt
| breakStmt
| returnStmt
| letStmt;
letStmt: KeywordLet declSegment KeywordIn stmtList KeywordEnd Semicolon;
returnStmt: KeywordReturn expr Semicolon;
breakStmt: KeywordBreak Semicolon;
forStmt: KeywordFor ID OpAssign expr KeywordTo expr KeywordDo stmtList KeywordEnddo Semicolon;
whileStmt: KeywordWhile expr KeywordDo stmtList KeywordEnddo Semicolon;
assignStmt: lvalue OpAssign rValue;
rValue: expr Semicolon;
callStmt: (lvalue OpAssign)? ID LParen exprList RParen Semicolon;
ifStmt: KeywordIf expr KeywordThen stmtList ifStmtTail;
ifStmtTail: KeywordEndif Semicolon
| KeywordElse stmtList KeywordEndif Semicolon;
expr: orTerm;
orTerm: andTerm (BinOpOr andTerm)*;
andTerm: leTerm (BinOpAnd leTerm)*;
leTerm: geTerm (BinOpLeq geTerm)*;
geTerm: ltTerm (BinOpGeq ltTerm)*;
ltTerm: gtTerm (BinOpLt gtTerm)*;
gtTerm: neTerm (BinOpGt neTerm)*;
neTerm: eqTerm (BinOpNeq eqTerm)*;
eqTerm: subTerm (BinOpEq subTerm)*;
subTerm: addTerm (BinOpMinus addTerm)*;
addTerm: divTerm(BinOpPlus divTerm)*;
divTerm: mulTerm (BinOpDivide mulTerm)*;
mulTerm: parnTerm (BinOpTimes parnTerm)*;
parnTerm: (LParen expr RParen) | lvalue | constant;
//expr: constant exprTail
// | lvalue exprTail
// | LParen expr RParen exprTail;
//exprTail: BinOpPlus highExpr | highExpr;
//
//highExpr: BinOpPower expr | expr ;
//exprTail: | binaryOperator expr;
constant: IntLit | FloatLit;
exprList: | expr (Comma expr)*;
lvalue: ID (LBracket expr RBracket)?;
KeywordMain : 'main' ;
KeywordArray : 'array' ;
KeywordRecord : 'record' ;
KeywordBreak : 'break' ;
KeywordDo : 'do' ;
KeywordElse : 'else' ;
KeywordEnd : 'end' ;
KeywordFor : 'for' ;
KeywordFunction : 'func' ;
KeywordIf : 'if' ;
KeywordIn : 'in' ;
KeywordLet : 'let' ;
KeywordOf : 'of' ;
KeywordThen : 'then' ;
KeywordTo : 'to' ;
KeywordType : 'type' ;
KeywordVar : 'var' ;
KeywordWhile : 'while' ;
KeywordEndif : 'endif' ;
KeywordBegin : 'begin' ;
KeywordEnddo : 'enddo' ;
KeywordReturn : 'return' ;
KeywordInt : 'int';
KeywordFloat : 'float';
BinOpPlus : '+';
BinOpMinus : '-';
BinOpTimes : '*';
BinOpDivide : '/';
BinOpEq : '==';
BinOpNeq : '!=';
BinOpLt : '<';
BinOpGt : '>';
BinOpLeq : '<=';
BinOpGeq : '>=';
BinOpAnd : '&';
BinOpOr : '|';
OpAssign : ':=' ;
Equals : '=' ;
Colon : ':' ;
Semicolon : ';' ;
Comma : ',' ;
LParen : '(' ;
RParen : ')' ;
LBracket : '[' ;
RBracket : ']' ;
ID : [A-Za-z][A-Za-z0-9_]* ;
IntLit : '0' | [1-9][0-9]* ;
FloatLit : [0-9]+ '.' [0-9]* ;
Comment : '/*' .*? '*/' -> skip ;
Whitespace : [ trn]+ -> skip ;
这里面可能最迷惑的就是那一长串的expr了(xxTerm)这里简单解释一下,为了保证我们的这些运算符号有正确的关联(括号最先,位与最低一次类推按顺序排列的),注意这里只是保证了运算关联的正确性,至于运算顺序我们在生成 AST 的时候再修正。
如果上面说的还不是很清楚那么我们用
a := 1 + 2 * 3 + 4;
这个例子来说明吧, 那么我们知道这个运算顺序应该是先 3*4 之后再加到一起。 但是如果我我们根据上面的Antlr语法来进行解析我们会得到如下的解析树
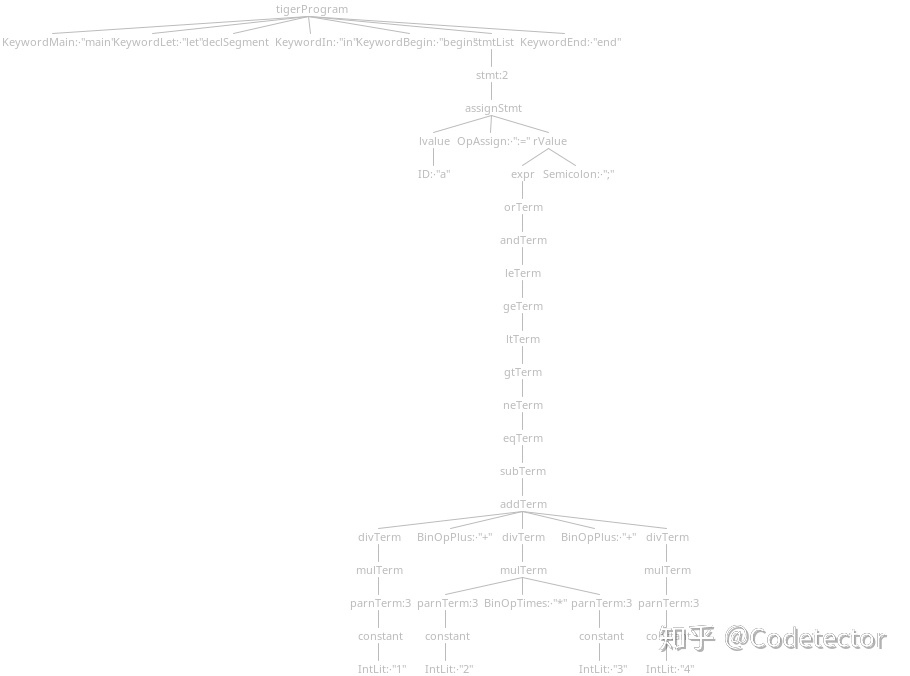
那么我们可以看到这里 2*3 被正确的关联在一起了。 但是这 1+(2*3)+4 却是在同一层级,这就是我们后面生成AST要进行拆解的部分啦。
[有兴趣的话可以考虑一下为什么我们选择再Parsing的时候处理关联]
这里推荐一下Antlr官方的IntelliJ插件 体验非常好
那么这次先到这里, 希望大家可以写写语法 玩一玩。 下次我们就开始讲怎么生成AST和一些IR生成
有什么问题欢迎评论私信















 9078
9078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









