






今天又下雨了,小李最近很忙,下班后很累也十分懈怠,今天小李分享点别的东西吧,小李力求知识面广度要够。
那么为什么要分享今天这个话题呢?因为机器学习和深度学习里面初始化参数的时候、一般是初始为某种分布的, 而正态分布就是最常用的之一,那就应该去探究一下它是怎么生成的,而不是浮于表面。
一般,一种概率分布,如果其分布函数为y=F(x),那么,y的范围是0~1,求其反函数G,然后产生0到1之间的随机数作为输入,那么输出的就是,符合该分布的随机数了:
y = G(x)
以指数分布为例,假设参数为a,那么概率密度函数为y=exp(-ax);概率分布函数为y=1-exp(-ax)/a。反函数为
y = -ln[(1-x)*a]/a;
那如何生成符合正态分布的随机数呢?看看正态分布的概率密度曲线,是不是十分美,既有形体学美、又有工学美。
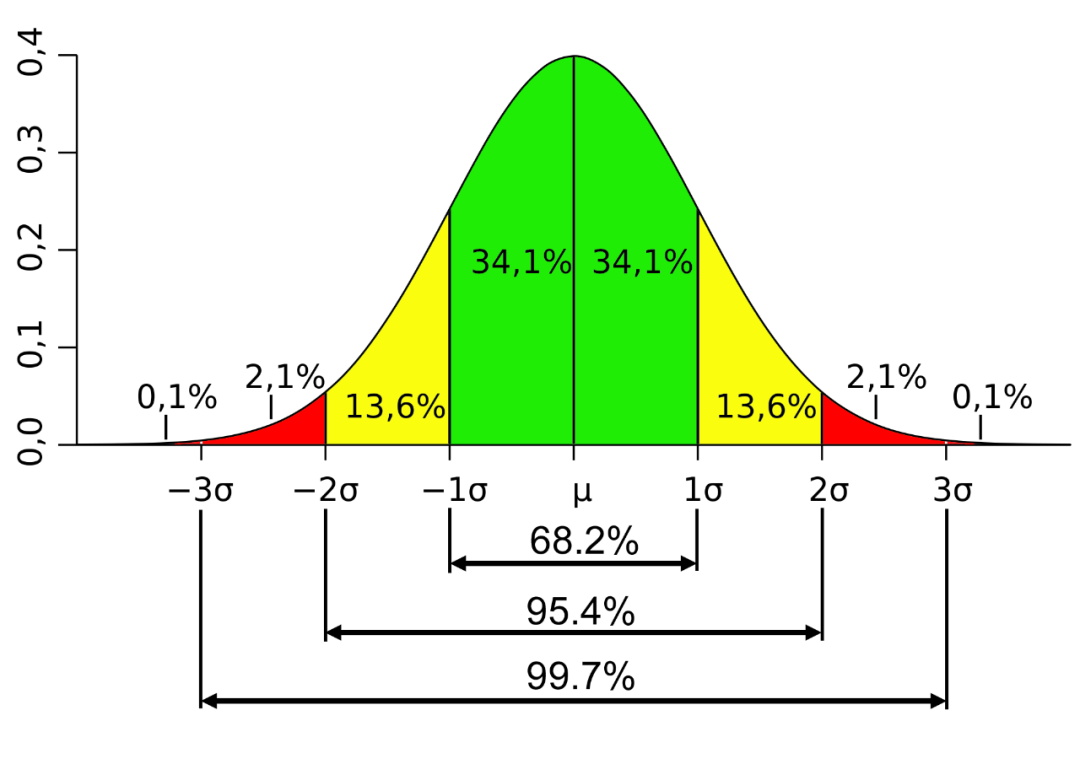
1 反函数法
先随机抽取一个[0,1]均匀分布的数字u,然后:
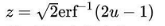
那么z就是符正态分布的随机数了。正态分布的概率分布函数如下图所示:
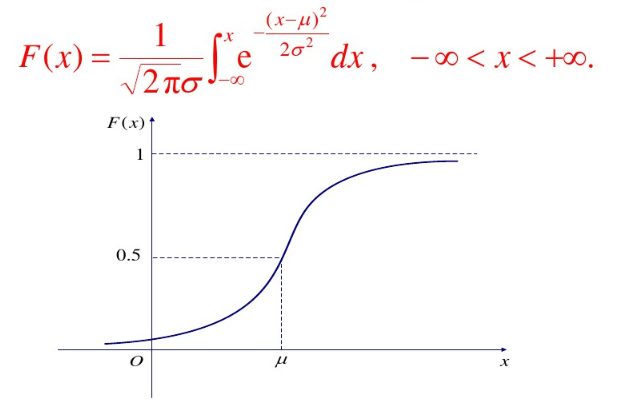
可以看出来它的反函数特复杂不好求。所以反函数法不适和用来求正态分布的随机数。
2 中心极限定理
正态分布不容易按照1中的做法,因为分布函数实在有点复杂。但是正态分布有一个特殊的性质,就是中心极限定理。其他任意分布的随机数,取大量,其均值服从高斯分布。严格的理论是这样的:对于服从均匀分布的随机变量,只要n充分大,随机变量
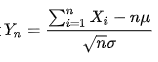
就服从均值为0,方差为1的正态分布。所以,很简单,取N个均匀分布的随机变量即可。特别的,一般可以取N=12,由于(0,1)均匀分布的均值为0.5,方差为1/12,直接带入上式,就可以了.
3 Box-Muller变换
最有效的办法,是Box-Muller方法。正态分布的另一特殊性质,与瑞利分布有关。二维正态分布下,两个分量如果独立,那么他的模服从瑞利分布。瑞利分布的话,就可以通过标准的分布函数求反函数的方法求得。
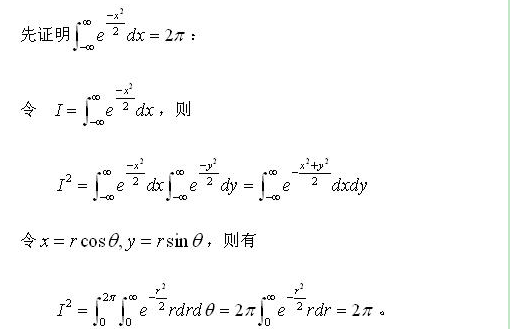

import numpy as npfrom scipy.special import erfinv def boxmullersampling(mu=0, sigma=1, size=1): u = np.random.uniform(size=size) v = np.random.uniform(size=size) z = np.sqrt(-2 * np.log(u)) * np.cos(2 * np.pi * v) return mu + z * sigma def inverfsampling(mu=0, sigma=1, size=1): z = np.sqrt(2) * erfinv(2 * np.random.uniform(size=size) - 1) return mu + z * sigma4 The Ziggurat algorithm(金字形神塔)
The Ziggurat algorithm 属于rejection sampling的一种。这个方法适用于分布函数是单调递减的情况,而正态分布的正半轴就属于这种情况,这里不再展开。















 2421
2421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









