





一、线性回归(Linear Regression)介绍
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x +e,e为误差服从均值为0的正态分布。线性回归是经济学的主要实证工具。例如,它是用来预测消费支出,固定投资支出,存货投资,一国出口产品的购买,进口支出,要求持有流动性资产,劳动力需求、劳动力供给。
二、算法步骤
1)预测房价的线性方程,其中theta(i)表示的是第i个特征x(i)的权重,h(x)是根据特征和相应的权重所预测的房价。
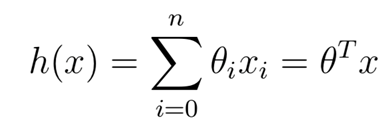
2)损失函数是用来评估线性函数好坏,损失函数J是对每个样本的估计值与真实值的平方进行求和,得到整个样本预测的值跟真实值之间的差距和损失。
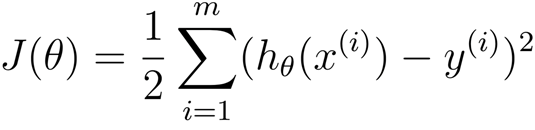
3)使用梯度下降寻找最优的线性方程转换为求解损失函数的最小值,也就是求解得到J取得最小值的时候的权重向量,权重的更新规则如下所示:

4)不断迭代,得到J取得较小值的权重向量。
三、数据集介绍
波士顿房价数据集,其实例数量是506个,实例包括了属性和房价,帮助预测的属性数量是13个,属性包含是CRIM 城镇人均犯罪率,ZN 占地面积超过2.5万平方英尺的住宅用地比例等等。训练集选取70%的数据集,测试集选取30%的数据集,训练集和测试集中都包括数据的特征属性和真实房价。
四、代码实现和结果展示
为了标准化数据特征的范围和加快收敛速度,在线性回归算法中采用了特征缩放的方法,特征缩放的方法包括调节比例(Rescaling)和标准化方法(Standardization)。Iteration(迭代次数)是1000,learning rate(学习率)是0.0001,权重刚开始初始化为零向量,正则化的惩罚因子是10。
特征所放的思路参考链接:https://blog.csdn.net/xlinsist/article/details/51212348;这两种方法分别对应代码函数:Rescaling()和Standardization().

#任务:将训练集和测试和预测的J_theta分别展示在图上
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
def loadDataSet():
boston=datasets.load_boston()
data=boston.data
label=boston.target
dataNum=data.shape[0]
print(dataNum)
testRatio=0.3
testNum=int(dataNum*testRatio)#因为乘出来有可能不是整数
trainNum=dataNum-testNum
train_x=data[0:trainNum,:]#train_data
test_x=data[trainNum:,:]#test_data
train_y=label[0:trainNum]#train_label
test_y=label[trainNum:]
return train_x,train_y,test_x,test_y
# def train_model(train_x,train_y,theta,iteration,learning_rate,my_lambda):#my_lambda是正则化参数
def train_model(train_x, train_y, theta, iteration, learning_rate):
m=train_x.shape[0]
n=train_x.shape[1]
print(m)
print(n)
J_theta=np.zeros((iteration,1))#先初始化一个J(theta)列向量,cost function
train_x=np.insert(train_x,0,values=1,axis=1)#train_x是n*n的矩阵,需要增加一个x0特征(x0=1),即增加一个列向量(放在第一列)
for i in range(iteration):
#这里是否要用到temp来暂时存储theta,用不到
J_theta[i] = sum((train_y[:, np.newaxis] - np.dot(train_x, theta)) ** 2) / 2.0#dot是内积,sum函数是将减掉后的列向量求和成一个数
theta=theta+learning_rate*(np.dot(train_x.T,train_y[:, np.newaxis] - np.dot(train_x, theta)))
#上面代码的优化(正则化)
# J_theta[i] = (sum((train_y[:, np.newaxis] - np.dot(train_x, theta)) ** 2) +my_lambda*(np.dot(theta.T,theta)-theta[0]**2))/(2.0*m)
#正则化
# theta=theta*(1-learning_rate*my_lambda/m)-learning_rate/m*np.dot(train_x.T,(np.dot(train_x, theta)-train_y[:, np.newaxis] ))
# theta[0]=theta[0]-learning_rate/m*np.dot(train_x[:,0].T,(train_y[:, np.newaxis] - np.dot(train_x, theta)))
# x_iteration=np.linspace(0,iteration,num=iteration)
# plt.plot(x_iteration,J_theta)
# plt.show()
return theta,J_theta
#特征缩放(feature scaling)的问题,标准化方法
def Standardization(x):
m=x.shape[0]
n=x.shape[1]
x_average=np.zeros((1,n))
sigma=np.zeros((1,n))
x_result=np.zeros((m,n))
x_average=x.mean(axis=0)#用np的mean函数来求每一列的平均值
# x_average=sum(x)/m
# sigma=(sum((x-x_average)**2)/m)**0.5
sigma=x.var(axis=0)#用np的var函数来求每一列的方差
x_result=(x-x_average)/sigma
return x_result
#特征缩放中的调节比例方法
def Rescaling(x):
m=x.shape[0]
n=x.shape[1]
x_min=np.zeros((1,n))
x_max=np.zeros((1,n))
x_result=np.zeros((m,n))
x_min=x.min(axis=0)#获得每个列的最小值
x_max=x.max(axis=0)#获得每个列的最大值
x_result=(x-x_min)/(x_max-x_min)
return x_result
def predict(test_x,test_y,theta,iteration,my_lambda):#用学习模型学习得来的最好参数,theta是(n+1)*1的矩阵
test_x=np.insert(test_x,0,values=1,axis=1)
m=test_x.shape[0]
h_theta=np.dot(test_x,theta) # np.dot(test_x,theta)是m*1的矩阵
J_theta=np.zeros((iteration,1))#先初始化一个J(theta)列向量,cost function
J_theta = (sum((test_y[:, np.newaxis] - np.dot(test_x, theta)) ** 2) )/ 2.0
#正则化
# J_theta = (sum((test_y[:, np.newaxis] - np.dot(test_x, theta)) ** 2) + my_lambda * (np.dot(theta.T, theta) - theta[0] ** 2)) / (2.0 * m)
rootMeanSquaredError=(sum((h_theta-test_y[:, np.newaxis])**2)/m)**0.5
print("rootMeanSquaredError",rootMeanSquaredError)
return h_theta,J_theta
if __name__=='__main__':
train_x, train_y, test_x, test_y=loadDataSet()
train_x = Standardization(train_x)
test_x=Standardization(test_x)
# train_x =Rescaling(train_x)
# test_x = Rescaling(test_x)
n=test_x.shape[1]+1
theta=np.zeros((n,1))#theta是n+1 * 1的列向量
iteration = 1000
# my_lambda = 0.0001
# my_lambda = 0
my_lambda = 10
learning_rate = 0.0001
# theta,J_train=train_model(train_x, train_y,theta, iteration, learning_rate,my_lambda)#正则化
theta, J_train = train_model(train_x, train_y, theta, iteration, learning_rate) # 正则化
h_theta,J_test=predict(test_x, test_y, theta,iteration,my_lambda)
# x_iteration=np.linspace(0,iteration,num=iteration)
结果展示:
注:RootMeanSquareError是均方根误差,是一种常用的测量数值之间差异的量度。
表1 线性回归预测房价结果
正则化和特征缩放
Standardization
Rescaling
正则化
不正则化
正则化
不正则化
RootMeanSquareError
18.22
无穷大
13.18
10.88
表1说明,在特征缩放的标准化方法中,正则化的均方根误差比不正则化的误差小得多;在特征缩放的调节比例方法中,不正则化的均方根误差比正则化后的小;在同时正则化或者不正则化的情况下,调节比例方法的均方根误差相对来说比标准化方法要小。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









