





一,小数据包
1,流量控制与“生产者-消费者模型”
调用send/write后,应用数据并没有被真正发送,只是被拷贝到了系统内核给这一个socket分配的发送缓冲区中。应用无法感知数据真正被发送的时机,它是由内核的TCP协议栈负责的。
发送窗口和接收窗口,也是针对发送缓冲区和接收缓冲区而言,他们作为TCP连接的双方,一个作为生产者,一个作为消费者,达到协同一致的生产-消费速率,而产生的算法模型。
即,发送者不能无限制的发送数据,需要考虑接收端中接收缓冲区的处理能力,而该处理能力是接收端通过发送窗口告诉服务端的。否则,大量接收端处理不过来的数据,会被丢弃导致重传,更多的数据报最终导致网络崩溃。
2,拥塞控制与数据传输
流量控制只是考虑在单个连接上的数据传输,但TCP数据包还需要经过网卡,交换机,路由器等一系列网络设备,而这些设备本身的能力也是有限的。所以,TCP协议必须考虑在有限的带宽上,如何兼顾多个连接上的效率和公平性控制。对应的就是拥塞控制算法。
TCP协议中的拥塞控制是通过拥塞窗口来完成的,而拥塞窗口本身是会随着网络状况实时调整的。传统的拥塞控制有2个阶段:慢启动,拥塞避免,拥塞发生。
2.1,当一个TCP连接成功后,慢启动开始,TCP从初始的拥塞窗口大小(cwnd=1,表示一个最大报文长度MSS大小的数据)开始,指数级(cwnd*2)将网络发送速率增加到一个阈值(ssthresh),慢启动就结束了。
2.2,慢启动后,拥塞避免开始,TCP会不断探测网络状态,并不断调整拥塞窗口大小。比如,当cwnd中所有的报文段都被确认后,才将cwnd+1,然后慢慢增加到网络的最佳值,直到网络拥塞,比如,开始出现丢包,进入拥塞发生。
2.3,TCP有2种判断丢包的逻辑,拥塞发生,对应2种丢包后的重传机制:
(1),超时重传:在重传计时器的时间内,一个ack都没收到,网络太差,重传计时器超时重传;
(2),快速重传:连续收到3个及以上的相同ack,表示网络还可以,不用等超时,直接重传。
因此,拥塞发生后,对应也有2种不同的恢复方法:
(1),拥塞严重(发生超时重传):ssthresh阈值减半,cwnd拥塞窗口置1,重新开始慢启动;
(2),拥塞不严重(发生快速重传):首先cwnd拥塞窗口减半,ssthresh阈值重置为cwnd,启动快速恢复,对应有不同的TCP Reno算法。
因此,在任何一个时刻,TCP发送缓冲区内的数据是否真的发送出去,取决于min((单个TCP连接上,点对点流量控制中,发送端与接收端共同协商的发送窗口大小),(多个TCP连接共享的带宽上,拥塞控制模型中,发送端独自根据网络状态来动态调整的拥塞窗口大小))。
3,一些有趣的场景
3.1,糊涂窗口综合征:接收端不能在刚刚读入非常少的字节数后,就向发送端发送更新窗口通知,而是应当在接收缓冲区大到一个合理范围后,才能发送。合理范围由RFC规范定义。
3.2,Nagle算法:在一些交互式场景下,比如,通过telnet或者ssh登录到一台远程服务器,发送端使用Linux命令行操作时,每次传输的数据可能非常小。根据其对实时性的要求,可以考虑开启或关闭Nagle算法。其中,Nagle算法提出,在任何一个时刻,未被确认的长度小于最大报文段长度MSS的TCP分组不能超过一个。这样,Nagle算法在接收端就可以把连续的几个小数据包存储起来,等待在途的小数据包被ACK确认后,再一次性发送出去。
3.3,延迟ACK:接收端如果对每一个TCP报文都使用不带任何数据分段,但又包含不可或缺元信息头的ACK报文进行确认,就会大量消耗带宽。因此,延时ACK表示,接收端在收到数据后并不会马上回复,而是在一段时间内累计需要发生的ACK报文,等待有数据需要发送给对端的时候,再将累计的ACK捎带一并发出。
虽然,Nagle算法和延迟ACK彼此阻碍,尤其是对时延敏感的交互式场景,可以通过设置Socket选项为TCP_NODELAY来关闭Nagle。但需要注意的是,现代计算机对两者的优化已经非常成熟,除非有十足的把握,否则不要轻易改变默认的Nagle算法。
3.4,合并写操作:使用writev或readv调用,配合iovec结构体数组,将多个请求一次发出,在应用层按需组合多个小数据包,避免Nagle算法引发的副作用。
二,UDP“已连接”
UDP是无连接协议,但是它可以调用connect函数。这里的connect并不会引起和目标服务器的网络交互,只是为了让应用程序接收“异步错误”的信息。
在传统UDP编程中,若服务端不开启,客户端会阻塞在recvfrom上,等待返回或超时。因此,通过UDP的socket进行connect操作,让该socket与服务端的地址和端口产生了联系,也给了系统内核必要的信息,使得内核收到的ICMP不可达信息可以反馈给socket。并且,该操作还能有一定程度的性能提升,减少了sendto发送信息时,频繁的地址初始化过程。
三,地址已经被使用
服务端程序首先断开连接并重启时,经常被出现地址已经被使用的情况,原因是以前提到的TIME_WAIT。
当客户端断开连接时,老的端口TIME_WAIT通常并不会有大的问题,因为客户端每次的端口都是随机的,就算碰巧“化身”了连接,系统内核协议栈的实现也能通过新连接的初始SYN序列号要大于TIME_WAIT连接下最后的序号大以及开启tcp_timestamps时,新连接的时间戳更大来避免。但服务端必须绑定在众所周知的端口上,因此,它首先断开连接并重启时,必须也要重用上次连接的端口,就会导致该问题。
1,正确的处理方法是设置socket的SO_REUSEADDR选项
1.1,允许服务端程序可以在极短的时间内,复用同相同的TIME_WAIT端口启动;
1.2,如果本机服务器有多个地址IP,它可以在不同的地址下使用相同的端口提供服务。根据客户端connect的不同IP,请求会被路由到不同的程序上,因为一个TCP连接,一定是使用一个唯一的四元组来标识;
1.3,因为四元组唯一标识一个有效连接,只要客户端程序的端口和上一个连接不同,服务端重用端口不会有任何问题。极小的概率下,碰巧客户端端口又相同,还有系统内核的SYN优化和tcp_timestamp来区分;
1.4,在bind是讲套接字和IP+端口的映射关系告诉系统内核,因此,需要在bind前设置SO_REUSEADDR才能将重用信息告诉内核,使其生效。
2,区分tcp_tw_reuse和SO_REUSEADDR
2.1,tcp_tw_reuse是内核态选项,SO_REUSEADDR是用户态选项;
2.2,tcp_tw_reuse常用于连接发起方主动关闭,通常为了防止客户端机器由于程序的某种bug导致的无效TIME_WAIT连接过多,导致系统的端口资源不足。而SO_REUSEADDR是服务端为了绑定在一个众所周知的端口上,必须在自己主动断开重启后,可以重用TIME_WAIT下的端口。当然,如果该端口在其他状态,同样是不能使用的。
四,理解TCP的流
TCP上传递的数据就像水管里的水一样,以流动的方式从发送到传送到接收端。
1,网络字节序
在网络字节流上,因为普通字符都是单个的字节,接收端可以拿过来直接解码。但对于数字,比如,int,float等包含多个字节的数据时,因为不同数据的存储尚未统一,存在大端字节序和小端字节序两种存储方式,解码程序需要判断数字高位到底是在字节流的前面还是后面,所以为了保证网络上传递的数据字节序相同,统一规定使用大端字节序,更符合人类的既定思维。与此同时,POSIX标准提出了统一的转换函数,对开发者屏蔽主机系统的存储顺序,帮助我们在主机字节序和网络字节序间灵活转换。
2,网络报文解析
虽然发送数据的顺序使TCP严格保证的,但只是一连串的字节流,并没有严格的分界,需要应用层想办法来处理数据间的分隔,确定每一条报文的边界。常见有2种方法:
2.1,发送端首先发送特定格式的消息头,接着在消息头中通知给接收端报文的长度,常见的RPC协议;

2.2,通过特殊字符来划分,比如,HTTP协议。
五,TCP并非总是“可靠”
TCP的可靠体现再TCP协议层是可靠的,而非应用层。如何理解这句话?
当调用write或read函数时,数据只是被发送到本机的发送缓冲区或是从接收缓冲区提取,而数据什么时候发送,是否已发送,是否需要重传,是否已经被ack确认,全部都被系统内核屏蔽在tcp的协议层实现里,应用层无法感知。比如,当tcp协议层返回ack确认后,接收端并没有办法保证ack过的数据,可以正常提交给应用程序处理。即,TCP协议的实现并没有提供给上层应用更多的异常处理细节。
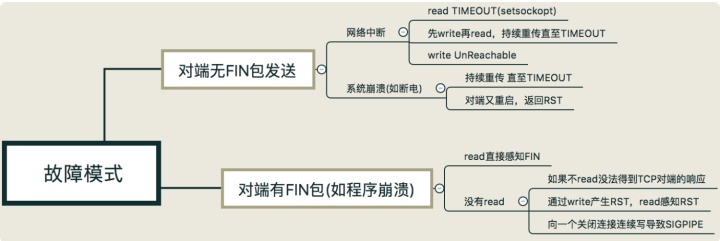
因此,TCP连接建立后,应用程序只能通过以read为核心的读操作和以wirte为核心的写操作,来感知可能的异常。有如下2大类,若干小类的情况:
1,对端无FIN包:对端没有调用close或shutdown,应用程序可以通过如下场景感知:
1.1,网络中断导致无FIN包
1),网络中的其他设备,比如路由器,发出的一条ICMP报文不可达目的网络或主机时,返回的“unreacheable”错误可以从read或write感知;
2),如果程序阻塞在read上,程序无法从阻塞中恢复,除非设置超时时间;
3),如果程序先write了一段数据流,接着阻塞在read上,Linux的协议栈会重传12次,约9分钟后,阻塞的read返回timeout。如果程序再次重试write,会立即失败并触发SIGPIPE信号。
1.2,程序崩溃导致无FIN包(区别于系统调用杀死进程)
1),无任何的不可达错误;
2),同1.1.2);
3),同1.1.3);
4),当对端程序崩溃后重启,重用TIME_WAIT端口后,重传的TCP分组到达对端的一个不存在的连接上,对端系统会返回RST重置分节。阻塞read调用会立即返回“连接重置”错误,表示连接重置;write操作也会失败,并触发SIGPIPE信号。
2,对端有FIN包:对端正常调用close或shutdown或系统调用杀死进程时,系统内核代为清理,应用程序无法区分,但可以通过如下场景感知:
2.1,阻塞read操作正常接收缓存中数据,直到返回值正常返回0(EOF);
2.2,在正常read到EOF前,发送write,接着再read,根据不同的内核实现,Linux 4.4内核,应用程序正常返回0;Mac OS 10.13.6内核,返回RST异常;
2.3,在正常read到EOF前,连续发送write,根据不同的内核实现,Linux 4.4内核,应用程序返回RST异常;Mac OS 10.13.6内核,触发SIGPIPE信号。
2.4,注意,在TCP网络编程的学习时,一定要区分应用层接收发送逻辑和内核协议层的接收发送逻辑,也就是区分2.2和2.3。比如,当对端协议层发送EOF,本机协议层正常接收回应ACK,但本机应用层可能并没有马上read,就不会感应到对端已退出。相反,如果本机应用层,仍在不停write,就只能通过write返回RST或触发信号中断来感知错误。
六,检查数据有效性
1,随时判断read和write返回值,并捕获SIGPIPE信号;
2,socket操作的超时机制;
3,随时防止缓冲区溢出;
4,在接收数据时,随时对变长报文头中的长度进行验证;
5,考虑使用一个全局循环缓冲区buffer对象作为应用层的读写缓冲。
七,参考文章
1,极客时间:网络编程实战 —— 盛延敏:(提高篇13-18讲)














 1134
1134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









