





一、概念
目标检测是在真实场景中寻找类似车辆、人类等物体的过程,一般可以在给定的图像中寻找多个目标。它可以用在图像检索、安防、自动驾驶(ADAS)等系统。
目标可以有以下几种方式:
- 基于特征的目标检测
- Viola Jones目标检测
- 基于HOG特征的SVM分类
- 深度学习

一些目标检测应用场景
- DeepFace :Facebook用来人脸识别
- Google facial recognition system

- 人数统计

- 工业产品质量检查

- 自动驾驶
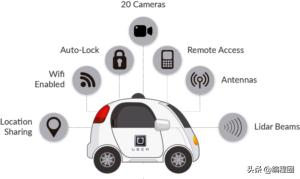
- 安防 人脸解锁

二、目标检测流程
不同目标检测算法的流程有所不同,但原理都差不多。下图是一个示例流程:
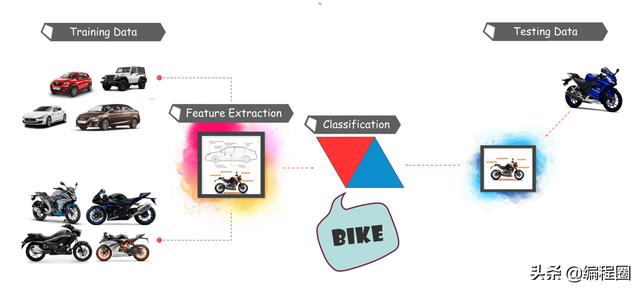
特征提取是关键动作,可以通过MatLab,OpenCV,Viola Jones 或深度学习来实现特征的提取。
三、实现
本文使用google训练好的模型 FasterRCNN+InceptionResNetV2或ssd+mobilenet V2来进行目标检测测试。
本文环境
- TensorFlow2.0
- 谷歌Colab
1. 导入包
#@title Imports and function definitions# Currently %tensorflow_version 2.x installs beta1, which doesn't work here.# %tensorflow_version can likely be used after 2.0rc0 !pip install tf-nightly-gpu-2.0-preview# For running inference on the TF-Hub module.import tensorflow as tfimport tensorflow_hub as hub# For downloading the image.import matplotlib.pyplot as pltimport tempfilefrom six.moves.urllib.request import urlopenfrom six import BytesIO# For drawing onto the image.import numpy as npfrom PIL import Imagefrom PIL import ImageColorfrom PIL import ImageDrawfrom PIL import ImageFontfrom PIL import ImageOps# For measuring the inference time.import time# Check available GPU devices.print("The following GPU devices are available: %s" % tf.test.gpu_device_name())2.
# 显示图片def display_image(image): fig = plt.figure(figsize=(20, 15)) plt.grid(False) plt.imshow(image)# 下载、预处理图片def download_and_resize_image(url, new_width=256, new_height=256, display=False): # 下载图片 _, filename = tempfile.mkstemp(suffix=".jpg") response = urlopen(url) image_data = response.read() image_data = BytesIO(image_data) pil_image = Image.open(image_data) # 统一大小 pil_image = ImageOps.fit(pil_image, (new_width, new_height), Image.ANTIALIAS) pil_image_rgb = pil_image.convert("RGB") pil_image_rgb.save(filename, format="JPEG", quality=90) print("Image downloaded to %s." % filename) if display: display_image(pil_image) return filename# 在图像上画框def draw_bounding_box_on_image(image, ymin, xmin, ymax, xmax, color, font, thickness=4, display_str_list=()): """Adds a bounding box to an image.""" draw = ImageDraw.Draw(image) im_width, im_height = image.size (left, right, top, bottom) = (xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height) draw.line([(left, top), (left, bottom), (right, bottom), (right, top), (left, top)], width=thickness, fill=color) # If the total height of the display strings added to the top of the bounding # box exceeds the top of the image, stack the strings below the bounding box # instead of above. display_str_heights = [font.getsize(ds)[1] for ds in display_str_list] # Each display_str has a top and bottom margin of 0.05x. total_display_str_height = (1 + 2 * 0.05) * sum(display_str_heights) if top > total_display_str_height: text_bottom = top else: text_bottom = bottom + total_display_str_height # Reverse list and print from bottom to top. for display_str in display_str_list[::-1]: text_width, text_height = font.getsize(display_str) margin = np.ceil(0.05 * text_height) draw.rectangle([(left, text_bottom - text_height - 2 * margin), (left + text_width, text_bottom)], fill=color) draw.text((left + margin, text_bottom - text_height - margin), display_str, fill="black", font=font) text_bottom -= text_height - 2 * margin# 图像上加注释def draw_boxes(image, boxes, class_names, scores, max_boxes=10, min_score=0.1): """Overlay labeled boxes on an image with formatted scores and label names.""" colors = list(ImageColor.colormap.values()) try: font = ImageFont.truetype("/usr/share/fonts/truetype/liberation/LiberationSansNarrow-Regular.ttf", 25) except IOError: print("Font not found, using default font.") font = ImageFont.load_default() for i in range(min(boxes.shape[0], max_boxes)): if scores[i] >= min_score: ymin, xmin, ymax, xmax = tuple(boxes[i]) display_str = "{}: {}%".format(class_names[i].decode("ascii"), int(100 * scores[i])) color = colors[hash(class_names[i]) % len(colors)] image_pil = Image.fromarray(np.uint8(image)).convert("RGB") draw_bounding_box_on_image( image_pil, ymin, xmin, ymax, xmax, color, font, display_str_list=[display_str]) np.copyto(image, np.array(image_pil)) return image3. 下载 OpenImagesV4图片
image_url = "https://farm1.staticflickr.com/4032/4653948754_c0d768086b_o.jpg" #@paramdownloaded_image_path = download_and_resize_image(image_url, 1280, 856, True)
4. 选择一种模型:
- FasterRCNN+InceptionResNet V2:准确度高
- ssd+mobilenet V2:小而且快
module_handle = "https://tfhub.dev/google/faster_rcnn/openimages_v4/inception_resnet_v2/1" #@param ["https://tfhub.dev/google/openimages_v4/ssd/mobilenet_v2/1", "https://tfhub.dev/google/faster_rcnn/openimages_v4/inception_resnet_v2/1"]detector = hub.load(module_handle).signatures['default']5. 定义函数加载图片
def load_img(path): img = tf.io.read_file(path) img = tf.image.decode_jpeg(img, channels=3) return img6. 检测函数
def run_detector(detector, path): img = load_img(path) converted_img = tf.image.convert_image_dtype(img, tf.float32)[tf.newaxis, ...] start_time = time.time() result = detector(converted_img) end_time = time.time() result = {key:value.numpy() for key,value in result.items()} print("Found %d objects." % len(result["detection_scores"])) print("Inference time: ", end_time-start_time) image_with_boxes = draw_boxes( img.numpy(), result["detection_boxes"], result["detection_class_entities"], result["detection_scores"]) display_image(image_with_boxes)7. 执行一个检测
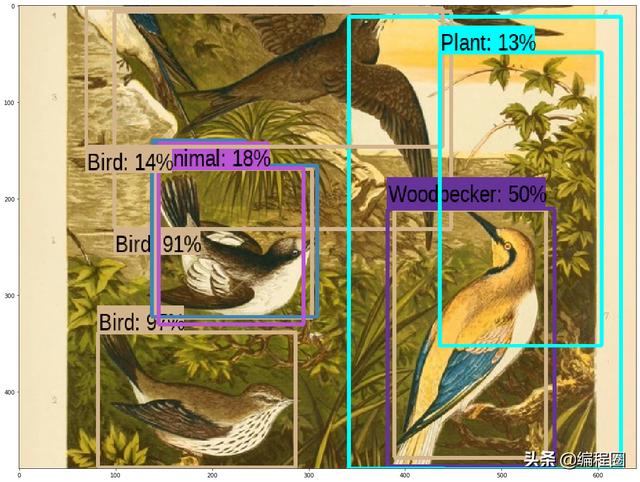
run_detector(detector, downloaded_image_path)
8. 测试更多图像
image_urls = ["https://farm7.staticflickr.com/8092/8592917784_4759d3088b_o.jpg", "https://farm6.staticflickr.com/2598/4138342721_06f6e177f3_o.jpg", "https://c4.staticflickr.com/9/8322/8053836633_6dc507f090_o.jpg"]for image_url in image_urls: start_time = time.time() image_path = download_and_resize_image(image_url, 640, 480) run_detector(detector, image_path) end_time = time.time() print("Inference time:")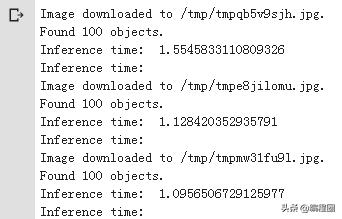
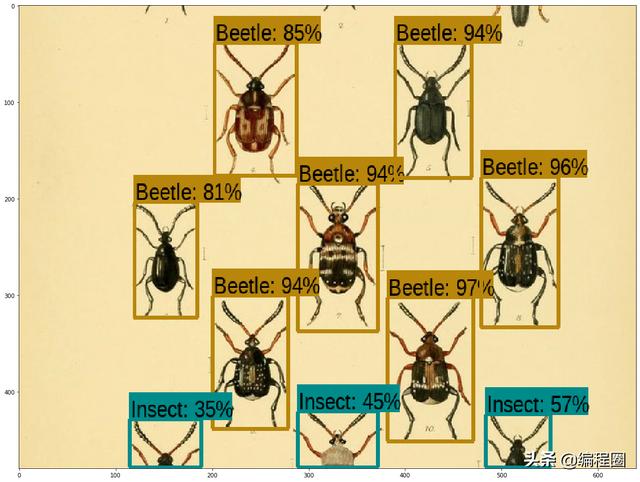
检测结果:
















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









