






说到缓存穿透,网上有很多的文章,但大多数文章只是简单的几句话概括了一下,并没有做深入的分析,于是触发了我写这片文章,要把缓存穿透说通透说明白了。
缓存穿透
我们先来说一下什么是缓存穿透,缓存穿透指的是用户访问一个不存在的key,于是绕过了缓存,直接请求数据库。当此并发量过大时就容易导致数据库的吞吐率降低,甚至因压力过大而进程挂掉。
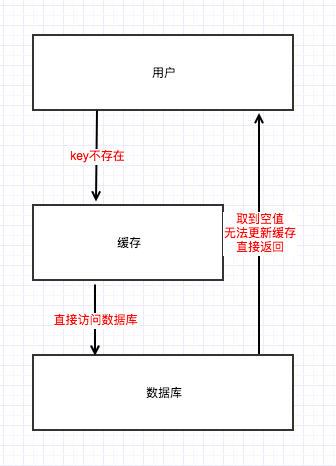
解决思路
我们用一个特定的值表示不存在,比如"nil",现实当中可以设置的再复杂一点,保证这个值不会被真实的场景用到。
然后每次我们通过key从数据库中请求获得空数据时,把key和"nil"以string形式插入缓存,这样下次我们请求时就可以从缓存中读取了。当然最好能设置一个过期时间,使无用的数据不至于长时间占用内存。
redis的操作命令如下:
SET key nil EX 10
复制代码
下面是改进的流程图
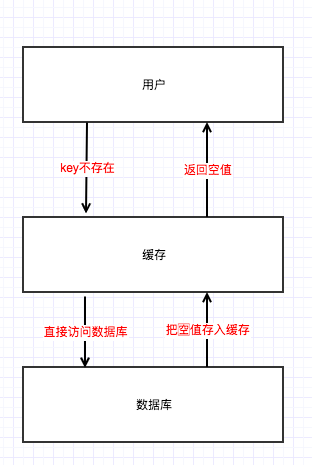
那这样是不是就万事大吉了呢?
我们来思考一下这种场景,用户发送100w个不相同的并且不存在数据库的key。这样每次请求后,还是会穿透缓存。
所以设置"nil"值到缓存的方案只适用于应对相同key的情况,对于大量不同的key还是没有办法解决。
那该怎么办呢?
那如果说我们有神秘系统,这个系统包含我们用到的所有的key(缓存中存在的和已过期的key),用户访问后在缓存中查不到,我们再到神秘系统中查找,如果存在这个key,那证明数据库中是有数据的,可以访问数据库,如果不存在这个key,则表示数据库中无数据,可以直接返回。 具体的流程图如下:
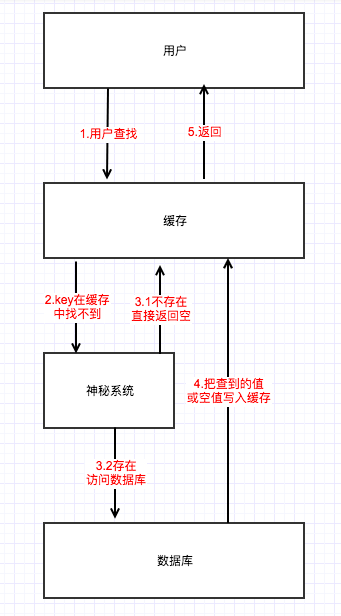
那这神秘的系统该怎么做呢?
有的小伙伴可定想到了,我们可以用redis的string类型啊,存成{key:1}的形式。这样做当然可以,但是用string存储,内存开销是非常大的,有点得不偿失啊。
那怎么办呢?这里,我们就可以使用布隆过滤器了。
布隆过滤器
原理
布隆过滤器是什么?我们从先来看一下布隆过滤器的原理图:
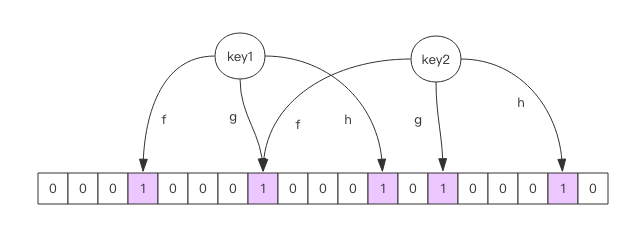
布隆过滤器底层可以认为是一个很大的数组,数组里面每一项为boolean类型,默认为false。
我们把key1插入布隆过滤器中,在插入前会执行f(),g(),h()三个计算,算出对应的hash值(3,7,11),这个hash值对应的是数组中的位置,于是我们把对应的位置设置为true。
我们插入key2,依然通过f(),g(),h()三个函数计算,计算出hash值为(7,13,17),我们继续把对应的位置设置为true。
刚才我们分析了插入,然后我们来看查询。
我们查询key1,通过三个方法计算出hash值为(3,7,11),我们再查看对应的数组中的值都为1,所以证明key1是存在的
我们查询key3,通过三个方法计算,算出hash值为(3,13,14),我们在查看对应数组中的值(1,1,0),不都为1 证明key3是不存在的。
这里有一种特殊的情况,我们存入key4,算出来hash值为(3,13,17),我们查询数组中的对应的值为(1,1,1), 都为1 表明存在,但事实上key4是不存在的。当然这个误差是可控的。
所以我们可以得出结论:
布隆过滤器中存在的不一定存在(误诊的概率很小),不存在的一定不存在。
复制代码
工具
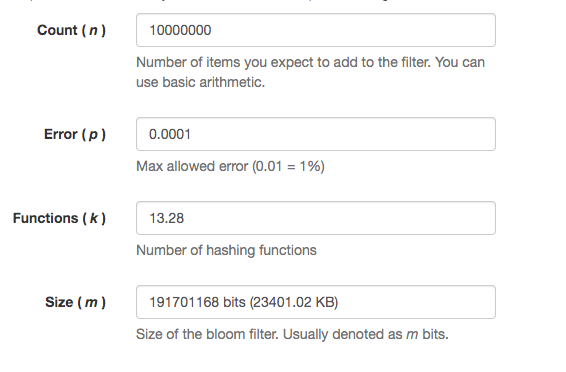
这里推荐一个布隆过滤器的工具
我们输入1千万的数据,错误率在万分之一,发现只要23m的内存,可以说非常的省内存。
实现布隆过滤器
那我们如何实现布隆过滤器呢? 我推荐两种方案:
使用redis的位图和程序的算法来实现。
使用redis的扩展 rebloom
这里要注意一下:rebloom这个扩展只能使用reids4.0以上版本,如果是4.0以下版本,建议使用第一种方案。
我们大体来说以下reboom的使用方法:
安装:
git clone git://github.com/RedisLabsModules/rebloom
cd rebloom
make
redis-server --loadmodule /path/to/rebloom.so
复制代码
使用:
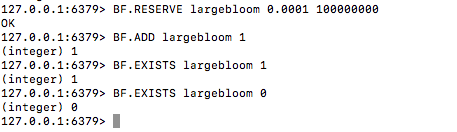
BF.RESERVE largebloom 0.001 10000000 // 设置错误率为万分之一,容量为1千万的,名为"largebloom"的布隆过滤器
BF.ADD largebloom 1 // 把"1"加入布隆过滤器中
BF.EXISTS largebloom 1 // 验证"1"是否存在
BF.EXISTS largebloom 0 // 验证"0"是否存在
方案合并
上面我们讲了一下如何防止缓存穿透,但在访问数据库的时候,会出现另一个风险,叫做缓存击穿。至于如何防止缓存击穿,我们在上一篇文章当中已有相应的说明了。文章地址我放在下面方便小伙伴阅读:
我们现在把缓存穿透与缓存击穿的两个方案合并一下,可以得出预防的具体步骤:
1.在初始化缓存的时候,需要同步生产一个布隆过滤器,所有可能用到的key放入布隆过滤器中(这里要注意,初始化缓存时,范围是热点数据,而初始化布隆过滤器时,范围是所有用的到数据的key)。
每次新增缓存,同样需要把key加入布隆过滤器中
查询的流程如下面的流程图所示:
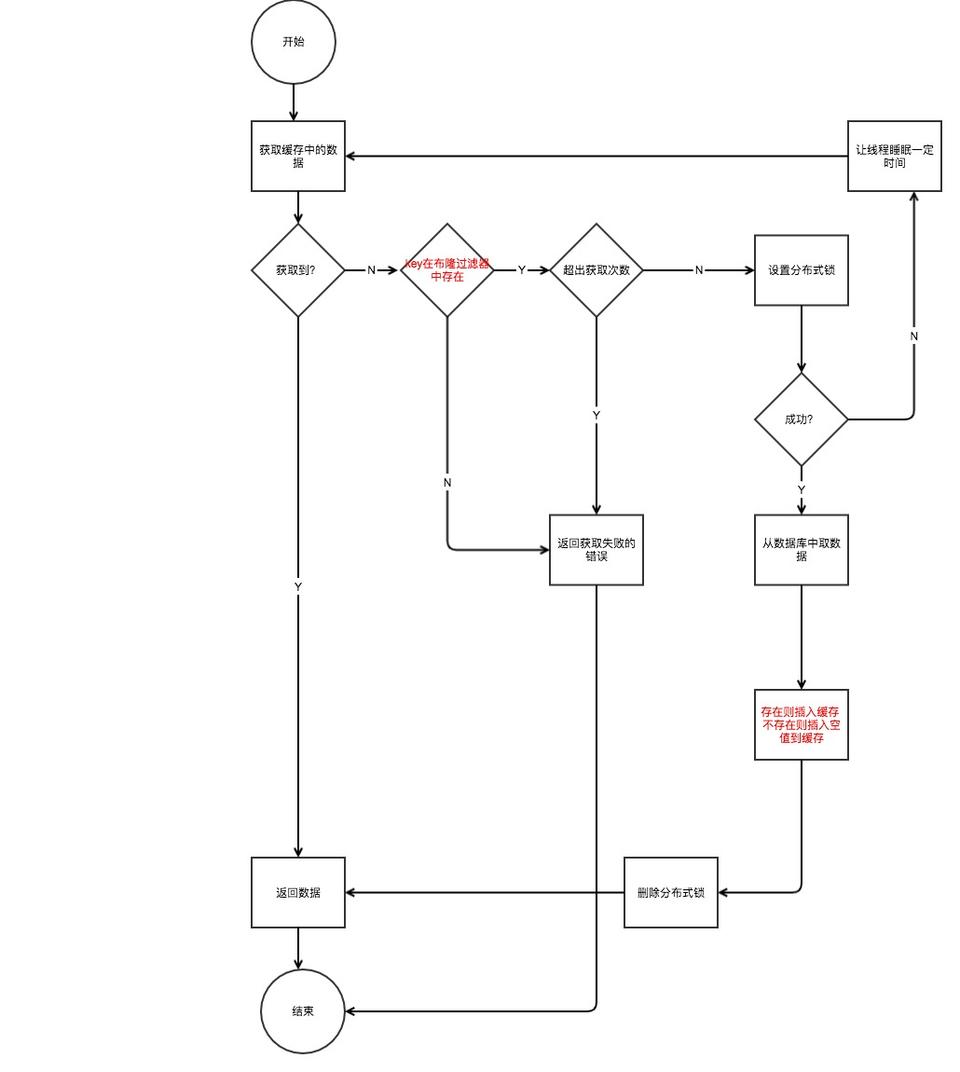
红色表示新增或者修改的流程。新增或修改的地方有两处,其他和之前的流程一样。
1). 没获取到数据的时候增加了一个布隆过滤器验证,当key不存在时,直接返回。
2). 数据库查询操作后,如果有数据,则插入数据,没有数据则插入空值。
总结
我们今天讲了如何防止缓存穿透,主要是两点:
使用布隆过滤器过滤掉不存在的key。
因为布隆过滤器有误诊行为,所以需要使用string类型的存储来防止漏网之鱼。
我们还分析了布隆过滤器的原理以及使用的方法。总结下来记住一句话:“布隆过滤器说有不一定有,说没有那一定没有”。
最后我们把缓存穿透与缓存击穿的预防方法结合了起来,给出了一套总体的方案。
感谢大家的阅读,也欢迎大家在留言区提供宝贵的意见,哪怕是砖也行,谢谢大家。















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









