






UniAD:端到端自动驾驶通用算法框架
上海人工智实验室提出了自动驾驶通用算法框架——Unified Autonomous Driving(UniAD)。UniAD 首次将检测,跟踪,建图,轨迹预测,占据栅格预测以及规划整合到一个基于 Transformer 的端到端网络框架下,在 nuScenes 数据集下的所有相关任务都达到 SOTA 性能,尤其是预测和规划效果远超其他模型。
UniAD多个共享BEV 特征的Transformer 网络首次将跟踪,建图,轨迹预测,占据栅格预测统一到一起, 并且使用不依赖高精地图的Planner 作为一个最终的目标输出,同时使用Plan 结果作为整体训练的loss 来源。虽然整体称为端到端,但是各个模块直接确实有着明显的界限和区隔,并非一个整体黑盒网络。 各个模块间有了相当的可解释性,也有利于训练和Debug,为自动驾驶端到端的设计提供了一个很好的范本。
项目地址:https://github.com/OpenDriveLab/UniAD
论文地址:https://arxiv.org/abs/2212.1015
一、核心技术
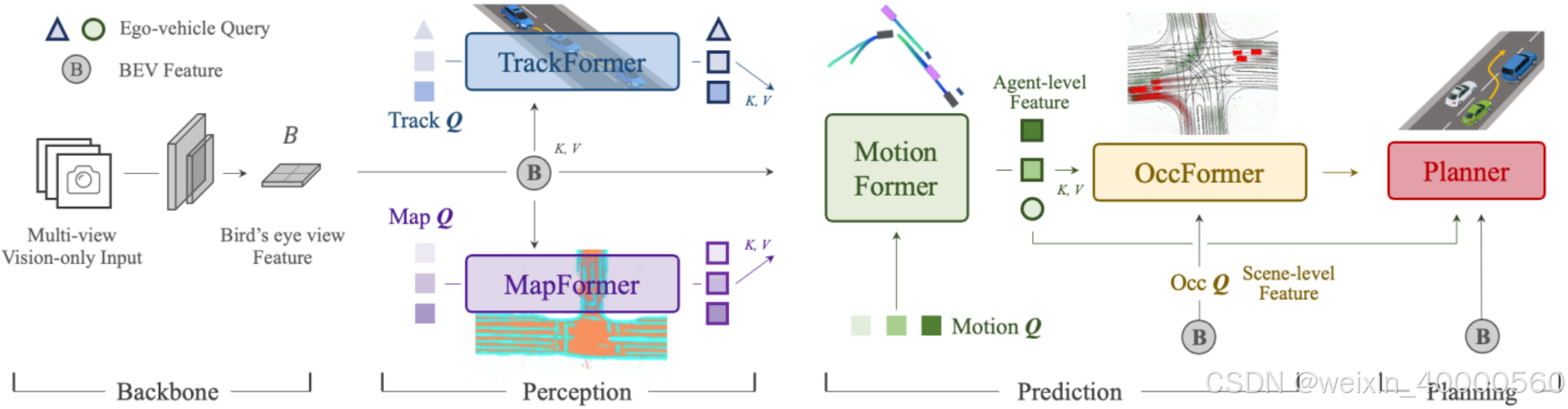
整体而言,UniAD利用多组query实现了全栈Transformer的端到端模型。上图所示,UniAD由2个感知模块(TrackFormer、MapFormer),2 个预测模块(MotionFormer、OccFormer)以及一个规划模块(Planner)组成。其中感知和预测模块是通过Transformer架构进行预测,每个模块输出的特征会传递到之后的模块来辅助下游任务。
如图所示, UniAD 由 4 个采用的 Transformer Decoder 结构的感知模块(TrackFormer & MapFormer)、预测模块(MotionFormer & OccFormer), 以及规划模块(Planner)组成. Queries
Q
Q
Q起到连接各个节点, 跑通整个 Pipeline 的作用。
说明: 图中不带边框的三角、圆、正方形表示输入的特征(Feature), 带边框的表示输出的特征.Ⓑ 表示 BEV Feature, 五个模块都会用到。
从流程上看:
1、首先backbone是多摄像头提取特征,透视图特征通过BEVFormer转换为Bev鸟瞰图空间供后续模块使用。
2、TrackFormer根据Bev信息进行推理,融合了检测和跟踪任务,输出为目标检测和跟踪的信息;
3、MapFormer根据Bev信息给出实时地图构建结果;作为道路要素的语义抽象和执行全景分割。
4、MotionFormer将TrackerFormer、MapFormer和Bev结果进行融合。捕获智能体和maps的交互和预测每个智能体的未来轨迹。
5、OccFormer是Motion Former与Bev 特征融合作为占据栅格网络预测的输入,以Bev特征作为查询,智能体知识作为键K和值V,预测多步未来占用。
6、Planner利用MotionFormer的表达性自我-车辆查询来预测规划结果,并远离OccFormer预测的被占用区域,以避免碰撞。
1.1、核心方案一:多组query的全Transformer模型
UniAD 利用多组 query 实现了全栈 Transformer 的端到端模型,我们可以从具体 Transformer 的输入输出感受到信息融合。在 TrackFormer 中,Track query 通过与 BEV 特征通过 attention 的方式进行交互,输出特征。类似的,Map query 经过 MapFormer 的更新后,得到特征。MotionFormer 使用 Motion query 与特征、以及 BEV 特征进行交互,得到未来轨迹以及特征。OccFormer 以密集的 BEV 特征为 Q 和稀疏的特征对应的位置信息和作为K 和 V 来构建实例级别的占据栅格。
1.2、核心方案一:基于最终“规划”为目标
在TrackFormer中,Track query 中包含一个特定的ego-vehicle query用来表示自车属性。规划模块 (Planner) 将MotionFormer更新后的 ego-vehicle query与BEV特征进行交互,此时ego-vehicle query包含对整个环境的感知与预测信息,因此能更好的学习Planning任务。为了减少碰撞,我们还利用占据栅格预测模块OccFormer 的输出对自车路径进行优化,避免行驶到未来可能有物体占用的区域。在这个过程中,全部的模块通过输出特定的特征来帮助实现最终的目标“规划”。
二. 框架
下面对各个模块进行具体的阐述。
2.1. Perception: TrackFormer
该模组可以同时实现检测和多目标追踪功能,并且这个过程中不依赖于任何不可导的后处理过程。TrackFormer中包含两种query,一种是传统的检测query,另一种是用于在多帧之间追踪agent的追踪query。具体来说就是在每一个时间步会初始化一些检测query,主要负责检测第一次出现的agent,同时跟踪queries则会对历史帧中已经被检测到的agents进行持续建模,检测queries和跟踪queries都是从BEV特征
B
B
B中抽取的agent的抽象特征。
随着时间帧推移,当前帧中的跟踪queries会与历史帧记录的跟踪queries进行自注意力机制进行交互,以此来整合时序上的信息。若相关的agent在一段时间内都没有出现,则会被定义为完全消失,那么这个自注意力机制也会相应停止。
TrackFormer 网络包含了N层, 并且最终输出状态
Q
A
Q_A
QA (这里的 A 指的是 Agent, 即障碍物).
Q
A
Q_A
QA提供了
N
a
N_a
Na个有效障碍物给下游的预测任务。
除了表征自车周围障碍物的 Query, UniAD 还提供了一个特殊的 Ego-Vehicle Query, 用来建模自车的状态, 这个在后续的 Planning 中也会被用到。
2.2. Perception: MapFormer
UniAD MapFormer 的设计基于 2D 全景分割(Panoptic Segmentation)方法 Panoptic SegFormer. 把道路元素稀疏地表示成 Map Query, 对 Lane 的位置和拓扑结构进行编码, 为后续的预测做准备。
对于驾驶场景中,车道线,分隔带以及十字路口等被设置为things,可驾驶区域被定义为stuff。
MapFormer也具有
N
N
N层结构,并且每层结构的输出都经过了监督,并且只有最后一层的输出queries
Q
M
Q_M
QM才会输出给 MotionFormer, 以实现障碍物和地图之间的交互。
2.3. Prediction: MotionFormer
UniAD中将MotionFormer设计为了E2E模式。利用之前TrackFormer与MapFormer中输出的动态agents的高度抽象queries
Q
A
Q_A
QA与
Q
M
Q_M
QM,MotionFormer可以预测所有agent在未来的多模态动作,比如以场景为中心的,可能性最高的
k
k
k条轨迹。这个过程仅需要一次前向传播就可以生成多个agent的多条轨迹。由于这省去了将所有场景转换到每个agent对应的坐标系下的过程,所以对于计算资源的节省和计算速度的提升具有显著的意义。与此同时,考虑到未来的ego和agents的动作其实会相互影响,所以TrackFormer中生成的ego-vehicle-query也会通过MotionFormer参与到与其他agents的交互中。最终输出的动作可以表示为:
{
X
^
i
,
k
∈
R
T
×
2
∣
i
=
1
,
.
.
.
,
N
a
;
k
=
1
,
.
.
.
,
κ
}
(1)
\lbrace \hat{X}_{i,k} \in \mathbb{R}^{T\times2} | i = 1,...,N_a;k=1,...,\kappa \rbrace \tag{1}
{X^i,k∈RT×2∣i=1,...,Na;k=1,...,κ}(1)
其中
i
i
i表示障碍物的 Index,
k
k
k表示轨迹的 Index,
T
T
T表示预测几秒(Horizon)。
2.3.1. MotionFormer
MotionFormer 由 N 层网络组成, 每层网络都有三种交互方式: Agent-Agent, Agent-Map 和 Agent-Goal Point。
对于每一个 Motion Query
Q
i
,
k
Q_{i,k}
Qi,k, 它与其他障碍物
Q
A
Q_A
QA或者地图元素
Q
M
Q_M
QM的交互可以用如下公式表示:
Q
a
/
m
=
M
H
C
A
(
M
H
S
A
(
Q
)
,
Q
A
/
Q
M
)
(2)
Q_{a/m} = MHCA(MHSA(Q), Q_A/Q_M) \tag{2}
Qa/m=MHCA(MHSA(Q),QA/QM)(2)
其中 MHCA, MHSA 分别表示多头交叉注意力Multi-Head Cross-Attention 和多头自注意力Multi-Head Self-Attention。
由于目标点同样重要,所以为了完善预测轨迹,还需要利用可变形注意力(deformable attention)机制建立agent和目标点之间的注意力:
Q
g
=
D
e
f
o
r
m
A
t
t
n
(
Q
,
X
^
T
l
−
1
,
B
)
(3)
Q_g = DeformAttn(Q, \hat{X}^{l-1}_{T}, B) \tag{3}
Qg=DeformAttn(Q,X^Tl−1,B)(3)
其中
X
^
T
l
−
1
\hat{X}^{l-1}_{T}
X^Tl−1是上一层网络的预测轨迹的 EndPoint。
D
e
f
o
r
m
A
t
t
n
(
q
,
r
,
x
)
DeformAttn(q, r, x)
DeformAttn(q,r,x)是一个 可变形注意力(Deformable Attention)模型, 输入是 Query
q
q
q , 参考点(reference points)
r
r
r和空间特征
x
x
x。利用可变形注意力可以让预测轨迹根据终点的周边环境进一步优化。
三种交互方式是并行计算的, 计算得到的结果
Q
a
Q_a
Qa,
Q
m
Q_m
Qm和
Q
g
Q_g
Qg将被连接整合到一起, 然后传入多层感知器(Multi-Layer Perceptron, MLP), 最终得到查询的上下文(Query Context)
Q
c
t
x
Q_{ctx}
Qctx .
Q
c
t
x
Q_{ctx}
Qctx这个上下文query会在下一层被优化或者直接编码为输出结果。
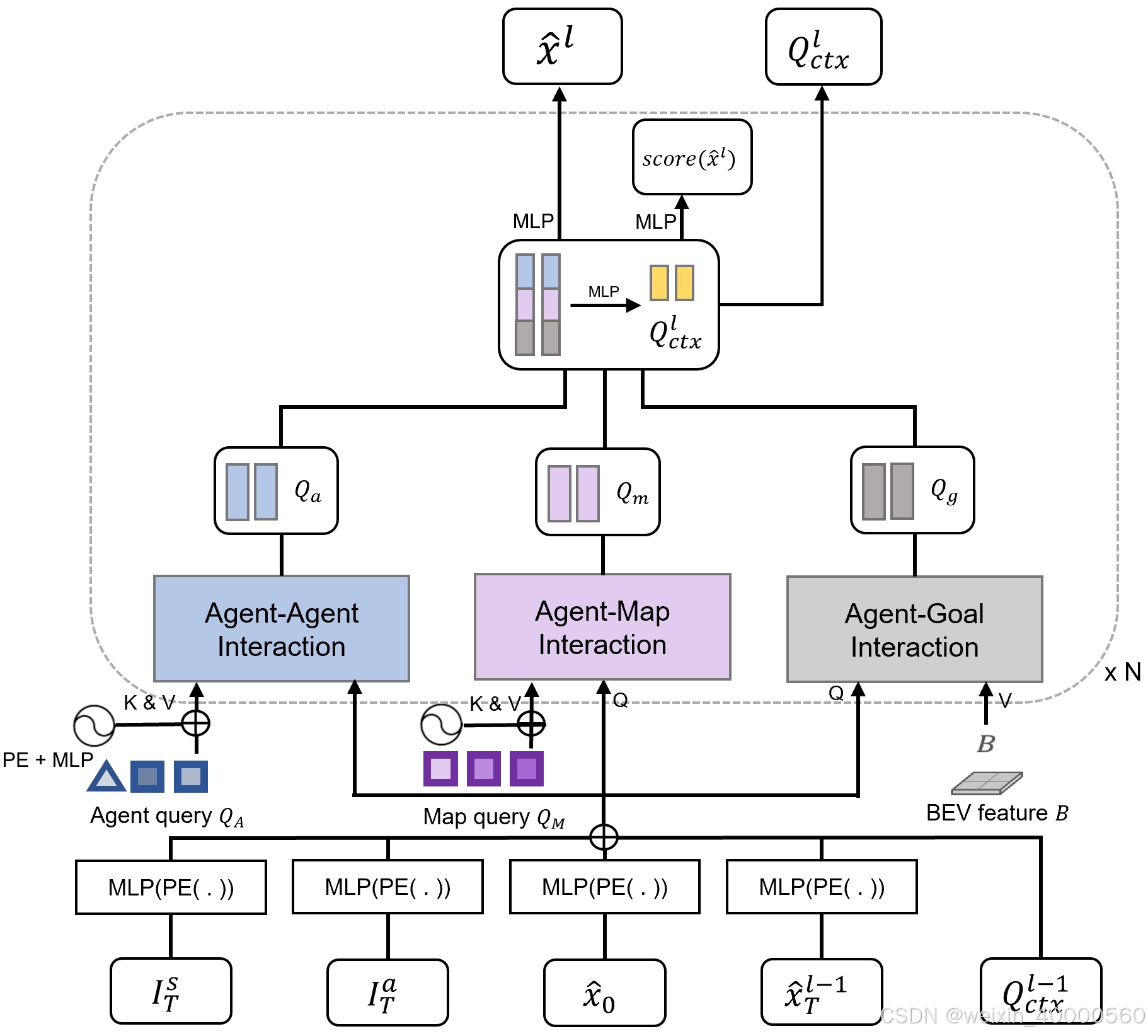
如上图MotionFormer。它由N个堆叠的交互模块组成,每个模块内会进行agent-agent,agent-map 和 agent-goal point(轨迹终点)的关系建模。 agent-agent 和 agent-map 交互模块使用标准的Transformer解码器层,agent-goal交互模块构是建在可变形的交叉注意力模块上。
2.3.2. Motion Queries
MotionFormer 的每层网络的输入查询叫做运动查询(Motion Queries), 由上下文查询
Q
c
t
x
Q_{ctx}
Qctx和位置查询
Q
p
o
s
Q_{pos}
Qpos两个部分组成。
Q
p
o
s
Q_{pos}
Qpos整合了4种位置信息:场景层面的锚点(Scene-Level Anchors)位置
I
s
I_s
Is。交互对象agent层面的锚点(Agent-Level Anchors)位置
I
a
I_a
Ia。交互对象agent当前的位置。预测的目标点的位置。
Q
p
o
s
=
M
L
P
(
P
E
(
I
s
)
)
+
M
L
P
(
P
E
(
I
a
)
)
+
M
L
P
(
P
E
(
X
^
0
)
)
+
M
L
P
(
P
E
(
X
^
T
l
−
1
)
)
(4)
Q_{pos} = MLP(PE(I^s)) + MLP(PE(I^a)) + MLP(PE(\hat{X}_0)) + MLP(PE(\hat{X}^{l-1}_{T})) \tag{4}
Qpos=MLP(PE(Is))+MLP(PE(Ia))+MLP(PE(X^0))+MLP(PE(X^Tl−1))(4)
其中,
P
E
(
.
)
PE(.)
PE(.)代表正弦位置编码,后接MLP,用于编码位置点。
X
^
T
0
\hat{X}^{0}_{T}
X^T0表示第一层的
I
s
I^s
Is。场景级锚框代表global坐标系下的先前运动数据(prior movement statistics),agent级锚框主要在当前坐标系下对可能的运动进行捕捉。这两种锚框都是通过 k-means对轨迹真值的终点进行聚类所得,目的是缩小预测的不确定性。与先验知识不同,起点是对每个agent进行位置编码,终点则是逐层对锚框进行的动态优化。
2.3.3. Non-linear Optimization
统的行动预测都是直接利用感知的结果,比如agent的位置和相关的轨迹。但是这并没有考虑到前序模块输出结果的不确定性,直接从这些结果暴力回归,可能会导致预测模块的效果不尽人意。
因为从感知得到的不完美的障碍物位置和 Heading 的进行暴力回归可能会导致大曲率和大加减速情况下产生不现实的轨迹. 为了解决这个问题, 当感知给一个不精确的起始点的时候, UniAD 采用非线性平滑来适应调整轨迹来使得其物理上可行. 用如下公式表示:
X
~
∗
=
a
r
g
m
i
n
X
c
(
X
,
X
~
)
(5)
\tilde{X}^* = arg \underset{X}{min} c(X, \tilde{X}) \tag{5}
X~∗=argXminc(X,X~)(5)
其中,
X
~
\tilde{X}
X~和
X
~
∗
\tilde{X}^*
X~∗分别表示Ground-Truth 和平滑后的轨迹。
X
X
X由 Multiple-Shooting 产生, 代价函数如下:
c
(
X
,
X
~
)
=
λ
∥
X
,
X
~
∥
2
+
λ
g
o
a
l
∥
X
,
X
~
T
∥
2
+
∑
ϕ
∈
Φ
ϕ
(
X
)
(6)
c(X, \tilde{X}) = \lambda \lVert X, \tilde{X} \rVert_2 + \lambda_{goal} \lVert X, \tilde{X}_T \rVert_2 + \sum\limits_{\phi \in \Phi}\phi(X) \tag{6}
c(X,X~)=λ∥X,X~∥2+λgoal∥X,X~T∥2+ϕ∈Φ∑ϕ(X)(6)
其中
λ
x
y
\lambda_{xy}
λxy和
λ
g
o
a
l
\lambda_{goal}
λgoal是超参, 运动学方程
Φ
\Phi
Φ由五个参数, 分别是加加速度、曲率、曲率变化率、加速度和横向加速度。代价方程对目标轨迹进行正则化处理,使其符合运动学约束条件。值得注意的是目标轨迹优化仅在训练中进行,不影响推理。
2.4. Prediction: OccFormer
占据栅格地图是一种离散的 BEV 表示, 每个 Cell 有一个可信度(Belief)来表示这个 Cell 是否被占用了, 而占据预测(Occupancy Prediction)的任务是找出栅格地图未来如何变化。
以往的占用模型都采用RNN结构,根据BEV特征图进行未来的预测。这种方法将整个BEV特征都压缩进了RNN的隐藏状态,很难以agent为单位进行预测,因此通常采用人工后处理的方式生成每个agent的占用,这中agent的信息利用不充分也导致这些模型很难在全局范围内预测所有agent的行为。
OccFormer 则从以下两个方面整合了场景层面(Scene-Level)和交互障碍物agent层面(Agent-Level)的语义:
稠密场景特征通过注意力模块可以在展开至未来时间段时获得agent级别的特征;
在交互障碍物层面的特征和场景特征之间简单地通过矩阵乘积的方式产生实例的占据网格, 而不需要很重的后处理。
OccFormer 由
T
O
T_O
TO个序列块组成,
T
O
T_O
TO表示 Prediction Horizon(即预测轨迹多少秒)代表预测时长。 并且考虑到稠密占用的计算消耗巨大,
T
O
T_O
TO比之前轨迹预测的时间段
T
T
T要小一些。每个序列块的输入是包含了丰富的agent信息的特征
G
t
G^t
Gt以及从上一层获取的稠密特征
F
t
F^t
Ft,输出为包含了实例级别和场景级别信息的
t
t
t时间步的稠密特征
F
t
F^t
Ft。为了使agent特征
G
t
G^t
Gt包含动态和空间先验,需要对MotionFormer中生成的motion queries在模态维度进行最大池化,表示为
Q
X
∈
R
N
a
×
D
Q_X \in \mathbb{R}^{N_a \times D}
QX∈RNa×D,其中
D
D
D为特征维度。然后
Q
X
Q_X
QX与上游的追踪query
Q
A
Q_A
QA与位置编码
P
A
P_A
PA通过一个时间性(temporal-specific)MLP进行融合:
G
t
=
M
L
P
t
(
[
Q
A
,
P
A
,
Q
X
]
)
,
t
=
1
,
.
.
.
,
T
o
(7)
G^t = MLP_t([Q_A, P_A, Q_X]) , t=1,...,T_o \tag{7}
Gt=MLPt([QA,PA,QX]),t=1,...,To(7)
其中
[
.
]
[.]
[.]代表了concat操作。
Pixel-agent interaction.设计这部分主要目的是在预测未来占用时统一场景级别和agent级别的理解。UniAD将稠密特征
F
d
s
t
F^t_{ds}
Fdst作为queries,实例级特征作为key和value来随时间更新稠密特征。具体来说就是,
F
d
s
t
F^t_{ds}
Fdst通过自注意力层来模拟远距离的网格之间的响应,然后通过交叉注意力层来建模agent特征
G
t
G^t
Gt与逐网格特征之间的交互。为了建立像素和agent之间的联系,UniAD采用注意力掩码来限制每个像素只能看到占用该像素的agent。稠密特征的更新过程为:
D
d
s
t
=
M
H
C
A
(
M
H
S
A
(
F
d
s
t
,
G
t
,
a
t
t
n
−
m
a
s
k
=
Q
m
t
)
)
D^t_{ds} = MHCA(MHSA(F^t_{ds}, G^t, attn-mask = Q^t_{m}))
Ddst=MHCA(MHSA(Fdst,Gt,attn−mask=Qmt))
注意力掩码
Q
m
t
Q^t_{m}
Qmt的语义类似于占用,并且是由附加的agent级别特征和稠密特征
F
d
s
t
F^t_{ds}
Fdst相乘获得的。这其中我们将agent级别的特征定义为掩码特征
M
t
=
M
L
P
(
G
t
)
M^t = MLP(G^t)
Mt=MLP(Gt)。随后,
D
d
s
t
D^t_{ds}
Ddst被上采样到四分之一的
B
B
B的尺寸,并进一步将
D
d
s
t
D^t_{ds}
Ddst与模块的输入
F
t
−
1
F^{t-1}
Ft−1相结合,作为一个残差。
Instance-level occupancy. 为了从原始尺寸为
H
×
W
H \times W
H×W的BEV特征
B
B
B中得到占用预测,场景级别特征
F
t
F^{t}
Ft被上采样为
F
d
e
c
t
∈
R
C
×
H
×
W
F^t_{dec} \in \mathbb{R}^{C \times H \times W}
Fdect∈RC×H×W。对于agent级别的特征,粗糙的掩码特征
M
t
M^t
Mt通过另外一个MLP被更新为占用特征
U
t
∈
R
N
a
×
C
U^t \in \mathbb{R}^{N_a \times C}
Ut∈RNa×C。最终在
t
t
t时刻的实例级别占用可以由下式计算:
O
^
A
t
=
U
t
.
F
d
e
c
t
(8)
\hat{O}^t_A = U^t .F^t_{dec} \tag{8}
O^At=Ut.Fdect(8)
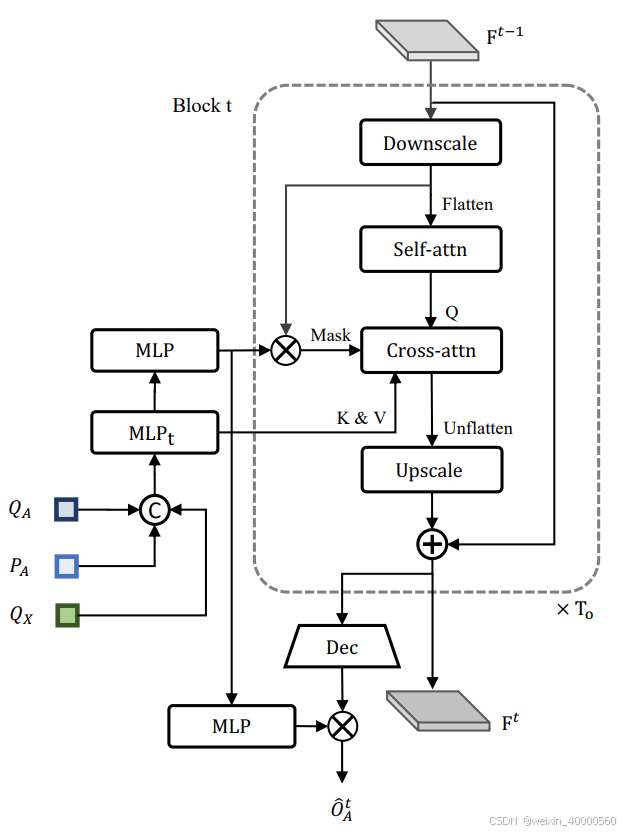
如上图OccFormer。它由
T
0
T_0
T0个顺序模块组成,其中
T
0
T_0
T0是时间范围(包括当前和未来帧),每个模块负责生成一个特定帧的占用栅格。 将上游传递的物体特征
Q
A
Q_A
QA,物体位置特征
P
A
P_A
PA,轨迹特征
Q
X
Q_X
QX进行编码用于表示物体的动态运动特征,并通过注意力机制对密集的场景特征(BEV特征)和稀疏的物体运动特征进行充分交互,最终解码为实例级别的占用栅格预测。
2.5. Planning: Planner
没有高精地图的 Planning 往往需要一个高阶的指令来指导往哪个方向走, 因此, UniAD 将原始的导航信号(左转, 右转, 直行)转化成三种可以学习的 Embeddings, 叫做 Command Embeddings. 利用 BEV 的特征
B
B
B来使 Planner 处理周围障碍物, 转化为未来的 Waypoints
τ
^
\hat{\tau }
τ^。为了避免碰撞, UniAD 用牛顿法来优化
τ
^
\hat{\tau}
τ^:
τ
∗
=
a
r
g
m
i
n
τ
f
(
τ
,
τ
^
,
O
^
)
(9)
\tau^* = arg \underset{\tau}{min} f(\tau, \hat{\tau}, \hat{O}) \tag{9}
τ∗=argτminf(τ,τ^,O^)(9)
其中
τ
^
\hat{\tau}
τ^是原始的规划预测,
τ
∗
\tau^*
τ∗表示优化后的规划后的自车轨迹,
τ
\tau
τ是多个 Shooting 轨迹.
O
^
\hat{O}
O^是从 OccFormer 融合得到的经典的二进制占据地图(Binary Occupancy Map).
f
(
τ
,
τ
^
,
O
^
)
f(\tau, \hat{\tau}, \hat{O})
f(τ,τ^,O^)代价函数 由以下公式计算:
f
(
τ
,
τ
^
,
O
^
)
=
λ
c
o
o
r
d
∥
τ
,
τ
^
∥
2
+
λ
o
b
s
∑
t
D
(
τ
t
,
O
^
t
)
(10)
f(\tau, \hat{\tau}, \hat{O}) = \lambda_{coord} \lVert \tau, \hat{\tau} \rVert_2 + \lambda_{obs}\sum\limits_{t}\mathcal{D}(\tau_t,\hat{O}^t) \tag{10}
f(τ,τ^,O^)=λcoord∥τ,τ^∥2+λobst∑D(τt,O^t)(10)
D
(
τ
t
,
O
^
t
)
=
∑
(
x
,
y
∈
S
)
1
σ
2
π
e
x
p
(
−
∥
τ
t
−
(
x
,
y
)
∥
2
2
2
σ
2
)
(11)
\mathcal{D}(\tau_t,\hat{O}^t) = \sum\limits_{(x,y \in S)} \frac{1}{\sigma \sqrt{2\pi}} exp(- \frac{\lVert \tau_t - (x, y) \rVert^2_2 }{2\sigma^2}) \tag{11}
D(τt,O^t)=(x,y∈S)∑σ2π1exp(−2σ2∥τt−(x,y)∥22)(11)
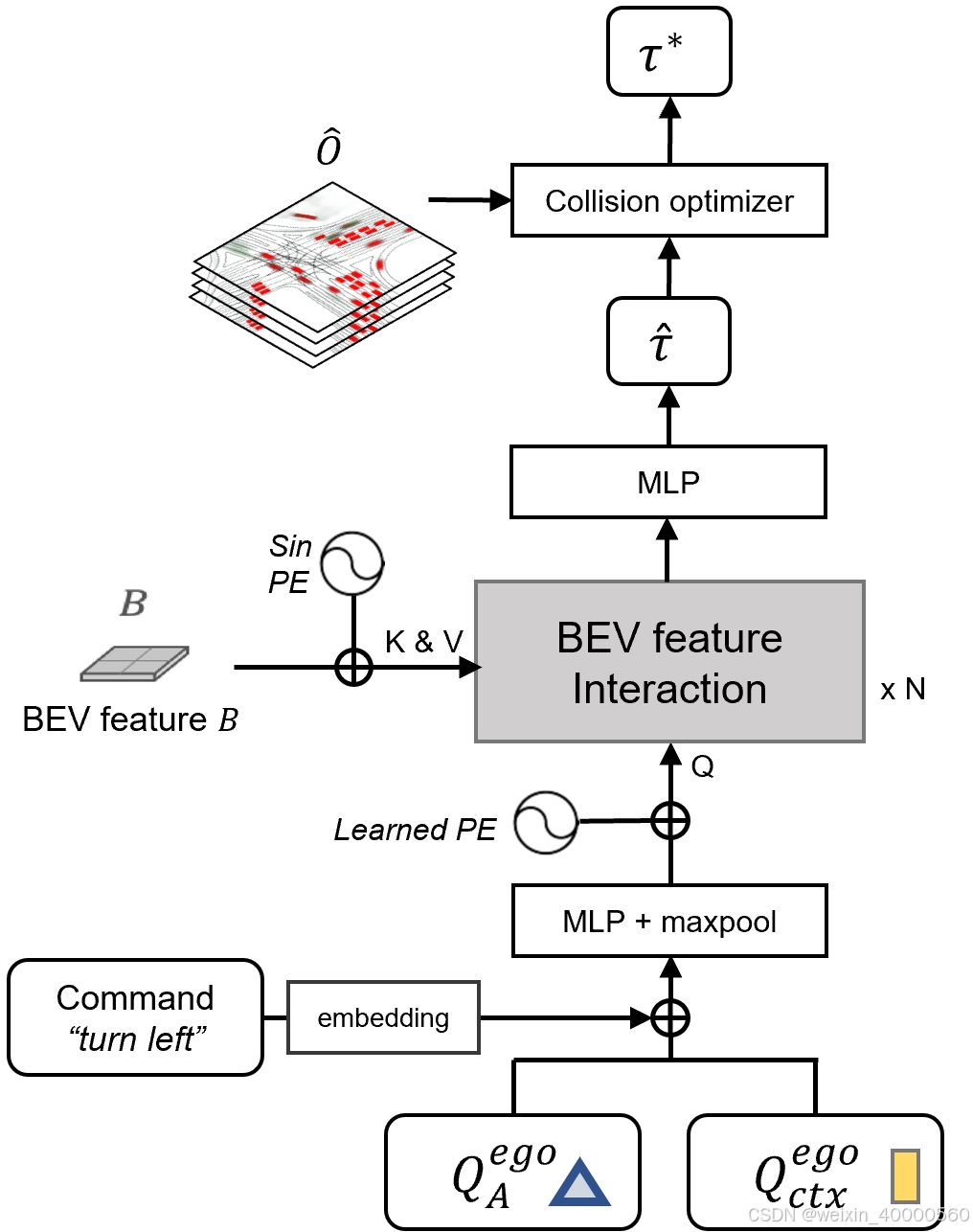
上图Planner。
Q
A
e
g
o
Q^{ego}_A
QAego和
Q
c
t
x
e
g
o
Q^{ego}_{ctx}
Qctxego分别是来自跟踪模块和轨迹预测模块的自车特征。通过使用 MLP 层进行编码,BEV特征交互模块采用标准 transformer decoder 层进行构建。最终通过碰撞优化器对预测轨迹进行再次优化,以达到更安全的路径规划。
三、实验结果
3.1、感知结果
对于表2中的多目标跟踪性能,与 MUTR3D 和 ViP3D 相比,UniAD 分别取得了+6.5和+14.2 AMOTA(%)的显着改进。此外,UniAD 取得了最好的 IDS 分数(越低越好),展示了UniAD在物体跟踪上的时序一致性。对于表3中的在线地图,UniAD 显示了出色的地图分割能力,尤其是在车道线分割的表现上(与BEVFormer相比+7.4 IoU(%))。
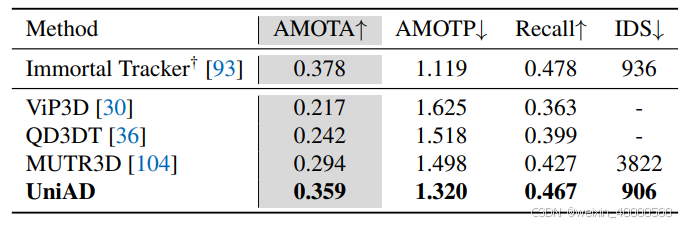
表2:UniAD在端到端多目标跟踪(MOT)任务上的所有指标上都取得了很大的优势。
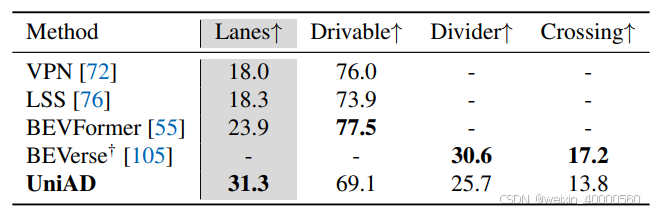
表3:UniAD 的地图生成(分割)能力,其在车道分割上取得了最好的性能。
3.2、预测结果
轨迹预测结果如表4所示,与 PnPNet 和 ViP3D 相比,UniAD 显著优于之前基于相机输入的端到端方法,并且在minADE 上分别将错误率减少了38.3%和65.4%。对于表5所示的占用栅格预测任务性能,UniAD在近距离区域取得了显着进步,与 FIERY 和 BEVERSE 相比,UniAD 在 IoU near(%)上分别取得了 4.0 和 2.0 的明显提升。
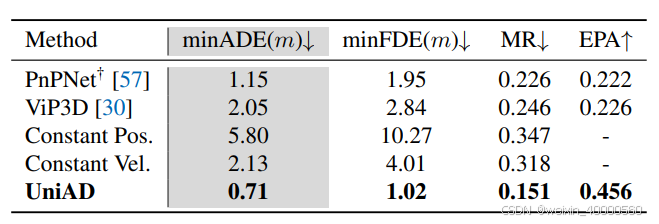
表4:UniAD 在轨迹预测的所有指标上均取得最好的性能。
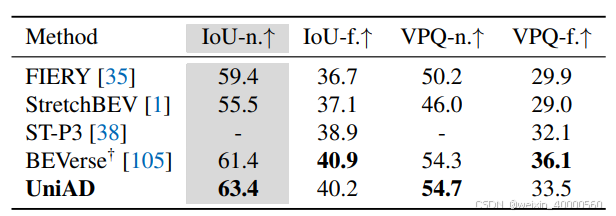
表5:UniAD 在自车附近区域的占用栅格预测结果得到显著改善,这对规划更为关键。
3.3、规划结果
与 ST-P3 相比,UniAD 将规划L2误差和碰撞率分别降低了51.2%和56.3%,并优于其它基于 LiDAR 输入的方案。
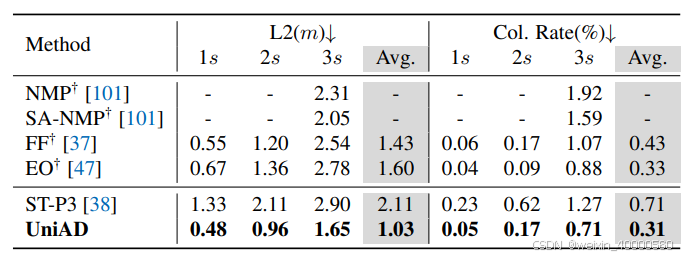
表6:UniAD 的规划性能超过了之前的所有方案,说明了 UniAD 设计的有效性。
3.4、消融研究
为了验证以目标为导向的设计理念是否真正发挥作用,本文对感知及预测中的各个模块进行了广泛的消融研究,如表7所示,以证明前序模块的有效性和必要性。
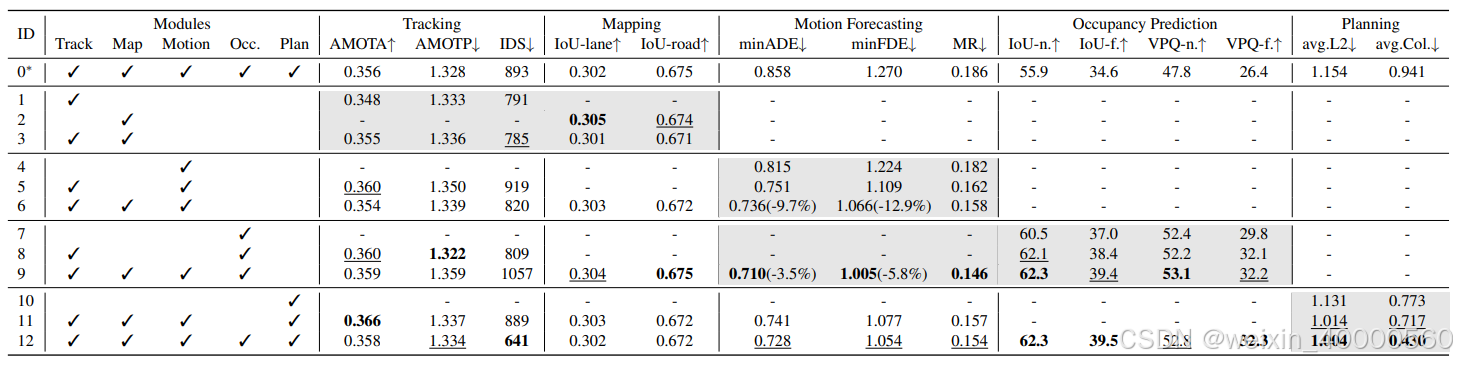
表7:感知及预测中的各个模块对下游任务的帮助。
前景
面对一个巨大的,并且分模块的任务, 训练过程一定是非常不稳定的。
文章中提到,根据他们的经验,他们会先训练6次Percecption(Track 和 Map )部分, 再训练20次整体, 最后得到比较好的结果。
这种训练方式也是得益于整体设计的相对解耦,感知模块可以被单独训练。能够在获得一个相对已经稳定的感知结果的基础上, 进行后续模块的训练,同时也对感知模块进行优化。
这种设计为工业界使用提供了一定的便利,多个模块之间的输出可以被单独debug, 也能被统一优化。而在工业界相对比较多的本车Plan 相关数据也为整个网络的训练提供了保证。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









