






之前逛B站,发现一个很有趣的视频,
闲着无聊也写了个爬虫爬取B站的弹幕,目标是爬取B站的一部科幻电影流浪地球,主要的思路如下:
- 获取弹幕文件保存在csv文件中
- 打开csv文件提取弹幕信息并清洗数据
- 通过可视化展示弹幕信息
获取弹幕文件
当然爬取的第一步是要得到你爬取文件的链接
获取弹幕url
为了显示出时间,这里是按照弹幕发生时间爬取. B站的弹幕文件的规则是https://api.bilibili.com/x/v2/dm/history?type=1&oid=+视频弹幕cid信息+&date=+弹幕发送日期(格式为YY-MM-DD,例如2020-08-20)
于是我们要解决两个问题
- 视频弹幕的cid信息
- 日期格式生成
视频弹幕cid信息获取
用浏览器打开你想爬取的视频,这里以chrome举例
- 按下 ctrl+u,查看网页源代码
- 按下 ctrl+f,输入 cid 查找cid
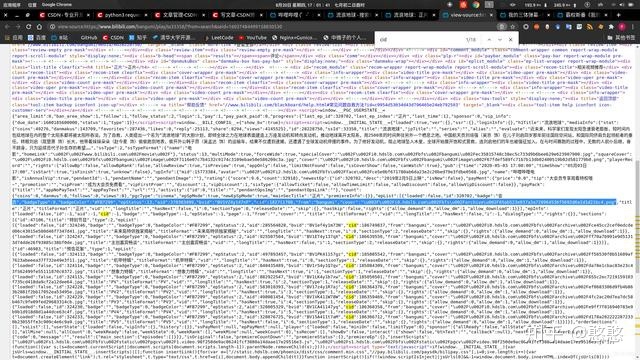
这里得到该视频的cid信息为182711708,简单的测试一下是否为我们想要的地址,将当天的地址合并得到弹幕文件地址为
https://api.bilibili.com/x/v2/dm/history?type=1&oid=182711708&date=2020-08-20
访问该链接得到以下结果
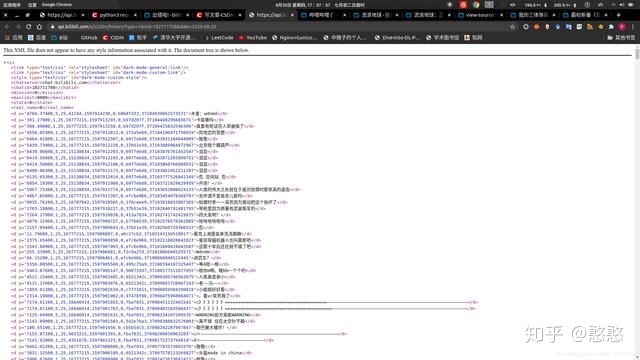
下一步就是获取日期
日期格式生成
日期格式直接使用datetime生成
import datetime
def create_assist_date(datestart = None,dateend = None):
# 创建日期辅助表
if datestart is None:
datestart = '2016-01-01'
if dateend is None:
dateend = datetime.datetime.now().strftime('%Y-%m-%d')
# 转为日期格式
datestart=datetime.datetime.strptime(datestart,'%Y-%m-%d')
dateend=datetime.datetime.strptime(dateend,'%Y-%m-%d')
date_list = []
date_list.append(datestart.strftime('%Y-%m-%d'))
while datestart<dateend:
# 日期叠加一天
datestart+=datetime.timedelta(days=+1)
# 日期转字符串存入列表
date_list.append(datestart.strftime('%Y-%m-%d'))
return date_list这样弹幕地址就可以通过 cid信息合并日期得到,下一步就是爬取信息
requests库爬取
B站获取历史弹幕需要登录信息,有很多种方法可以解决,这里采用的是获取登录后得到的cookies信息模拟登录.
获取cookies分为以下几步
- 打开B站,按下F12 进入开发者模式
- 选择network点击第一行得到右边的headers
- 找到cookies和user-agent,分别为requests.get()函数的cookies参数和headers参数
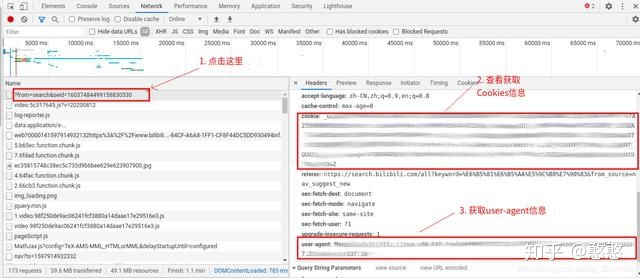
根据之前获得的url、cookies和user_agent,直接用下面的代码获取弹幕信息,然后利用BeautifulSoup库提取弹幕信息
import requests
# 这里填入自己的User-agent和cookie信息
headers = {
'User-Agent': "",
'Cookie': ""
}
def getDanmuKu(url):
danmu = requests.get(url, headers=headers)
# 解码弹幕内容为utf-8
danmu = danmu.content.decode('utf-8')
# 用BeatifulSoup提取弹幕信息
danmu = BeautifulSoup(danmu)
danmus=danmu.findAll('d')
# 将弹幕信息和内容分别用两个列表保存
danmu_info = []
danmu_text = []
for iter in danmus:
all_info.append(iter['p'])
all_text.append(iter.text)
return all_info, all_text保存弹幕到csv文件中
在当前文件目录下创建一个空文件夹csv,通过csv.writer 的writerow()方法写入弹幕数据
保存弹幕到csv文件中
在当前文件目录下创建一个空文件夹csv,通过csv.writer 的writerow()方法写入弹幕数据
def saveInCsv(all_info, all_text, date):
# 将弹幕文件保存在csv文件中
f=open('csv3/danmuinfo_' + str(date)+ '.csv','w', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(["时间", "弹幕模式", "字号大小", "颜色", "Unix格式时间戳", "弹幕种类", "发送者ID", "rowID"])
for single_info in all_info:
single_info = str(single_info).split(',')
csv_writer.writerow(single_info)
f.close()
f = open('csv3/danmutext_' + str(date) + '.csv', 'w', encoding='utf-8')
csv_writer=csv.writer(f)
for single_text in all_text:
csv_writer.writerow(single_text)
f.close()def saveInCsv(all_info, all_text, date):
# 将弹幕文件保存在csv文件中
f=open('csv3/danmuinfo_' + str(date)+ '.csv','w', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(["时间", "弹幕模式", "字号大小", "颜色", "Unix格式时间戳", "弹幕种类", "发送者ID", "rowID"])
for single_info in all_info:
single_info = str(single_info).split(',')
csv_writer.writerow(single_info)
f.close()
f = open('csv3/danmutext_' + str(date) + '.csv', 'w', encoding='utf-8')
csv_writer=csv.writer(f)
for single_text in all_text:
csv_writer.writerow(single_text)
f.close()打开CSV文件并清洗数据
思路如下:
- 打开csv文件,获取保存的弹幕文本
- 清除无意义的标点符号,这里可以自己进行相应的设置
- 利用字典记录弹幕出现的次数
- 根据弹幕次数排序字典
- 每次写入次数最多的十条弹幕信息到另外的CSV文件中
import jieba
import re,string
from zhon.hanzi import punctuation
import os
import csv
danmuCount = dict()
danmuNum = 0
punc = '~`!#$%^&*()_+-=|';":/.,?><~·!@#¥%……&*()——+-=“:’;、。?》《{} oh1O○〇●哈'
with open('danmuku3.csv', 'a', encoding='utf-8') as savefile:
writer = csv.writer(savefile)
writer.writerow(['name','type','value','date'])
for date in dateLists:
with open('csv3/danmutext_'+ date + '.csv', 'r', encoding='utf-8') as csvfile:
print('---分析日期', date, '弹幕...n')
reader = csv.reader(csvfile)
for line in reader:
danmuNum = danmuNum + 1
line = "".join(line)
line = re.sub(r"[%s]+" % punc, "", line)
# words_list = jieba.lcut(line)
# for word in words_list:
# data[line] = data[line] + 1
# line = line.lower()
if len(line) >= 2 and len(line) <= 15:
if danmuCount.get(line):
danmuCount[line] = danmuCount[line] + 1
else:
danmuCount[line] = 1
sortList = sorted(danmuCount.items(), key=lambda item:item[1], reverse=True)
if len(sortList)>10:
pltLists = sortList[:10]
for plttuple in pltLists:
saveLine = []
saveLine.append(plttuple[0])
saveLine.append('Chinese')
saveLine.append(plttuple[1])
saveLine.append(date)
writer.writerow(saveLine)可视化展示数据
这里参照的github开源库: Historical-ranking-data-visualization-based-on-d3.js
之前分析得到的csv文件的主要格式如下:
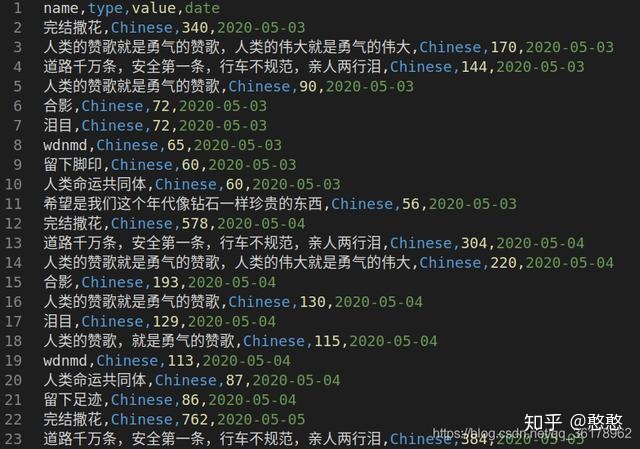
下载Historical-ranking-data-visualization-based-on-d3.js,用这个工具打开之前保存的csv文件,得到了一个动态展示弹幕的柱状图!
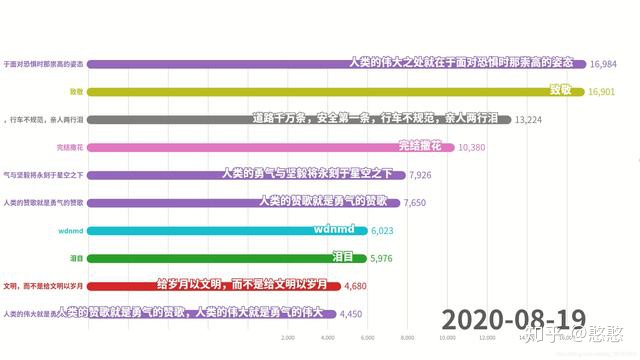
配上BGM就是一个很有趣的视频了
完整项目代码获取加下源码群:1136192749















 1587
1587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









