






include 作用
指定需要编译处理的文件列表,支持 glob 模式匹配,文件的解析路径相对于当前项目的 tsconfig.json 文件位置
匹配规则
*:匹配零个或者多个字符(包括目录的分隔符)?:匹配任一字符(包括目录分隔符)**/:匹配任何层级的嵌套目录
如果没有明确指定文件扩展名。那么默认情况下仅会包含
.ts、.tsx和.d.ts类型的文件。但是如果allowJs选项被设置成了true,那么.js和.jsx文件也会被包含其中
示例
当我们的目录结构如下
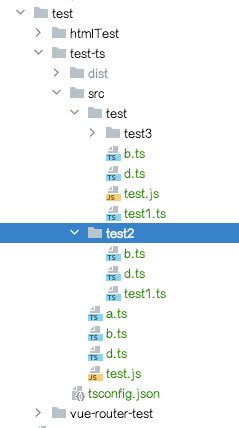
include配置为src或者src/时,src下的所有文件都会经过ts的编译include配置为src/*时,src下第一层级的子文件会经过ts的编译include配置为src/*.js时,src下第一层级的子文件以.js结尾的会经过ts的编译include配置为src/**/*时,src下的所有文件都会经过ts的编译,目录层级不限include配置为src/**/*.js时,src下以.js结尾的会经过ts的编译,并且在其对应的目录下面,目录层级不限include配置为**/*时,包含当前项目中所有文件
exclude 作用
用于指定当解析 include 选项时,需要忽略的文件列表
exclude的默认值是["node_modules", "bower_components", "jspm_packages"]加上outDir选项指定的值exclude配置为["src/*.ts"]代表忽略当前src下第一层级的ts文件- 任何被
files或include指定的文件所引用的文件也会被包含进来,A.ts引用了B.ts,因此B.ts不能被排除,除非引用它的A.ts在exclude列表中。
files 作用
用来指定需要编译的文件列表(注意,只能是文件,不能是文件夹)
- 如果其中任意一个文件无法找到,都会抛出错误
- 通过
files属性明确指定的文件却总是会被包含在内,不管exclude如何设置 - 这个配置项适用于你想要指定的文件数量比较少,并且不需要使用
glob模式匹配的情况。否则,请使用include配置项


















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











