







什么是DataOps?
DataOps是包括人,流程和技术的一组体系,用来管理代码,工具,基础架构和数据本身,从而实现三个核心功能:
- 将DevOps的敏捷开发和持续集成应用到数据领域
- 优化和改进数据管理者(生产者)和数据消费者的协作
- 持续交付数据流生产线
而下图则高度抽象的体现了DataOps的三要素:持续集成,持续开发,持续部署
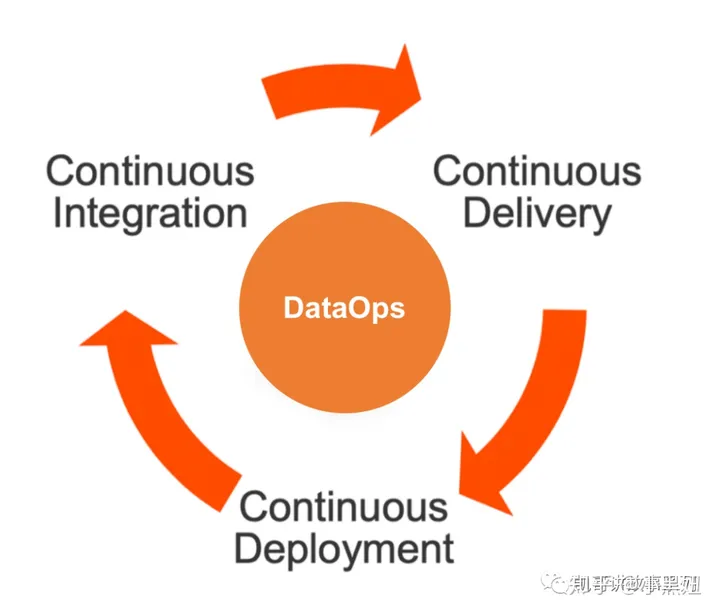
为什么需要DataOps?
DataOps的出现,从因为数字化转型进入了数据为核心的智能时代,为了满足企业对于数据管理,数据利用的三大战略趋势:
1. 数据分析民主化/Democratization of Data Analytics
原来数据分析能力是企业少数人需要掌握和构建的能力,而现在数据分析已经在走向民主化的趋势,任何一个岗位都需要数据的支撑。所以如何能够让数据和分析能力可以广泛的被所有背景的人所掌握,成为了企业数据部门所追求的目标。
2. 数据技术多元化/Diversification of Data Technology
十年以来,数据处理和利用的技术(Data-Tech)的发展突飞猛进,从原来的中心化的数据仓库,ETL技术,衍生到了一个繁杂的数据技术体系,细分成多种数据处理领域,比如:
- 数据分析
- 数据可视化
- 机器学习
- 云数据处理
- 流式数据处理
- 离线数据处理
3. 业务价值精益化/Lean of Business Value
企业对于数据部门的诉求,从“更好的管理数据资产”已经转化为“更快的产生业务价值”。那么如何能够精益化的识别数据的业务价值,并且快速验证,产生和转化业务价值,成为了企业数据部门的头等大事。
这个背景下,DataOps承担着持续支持业务价值产生的使命,如何能够加速业务价值的试验,是错,识别,生产的周期,支撑精益业务价值体系是DataOps构建的核心目标。
DataOps的四个能力构成
DataOps被业界公认的分成了四个关键构成,或者说是能力结构。
如下图所示,在Agile,DevOps和Lean的加持下,DataOps包括数据工程、数据集成、数据安全和隐私,数据质量四个能力构成:
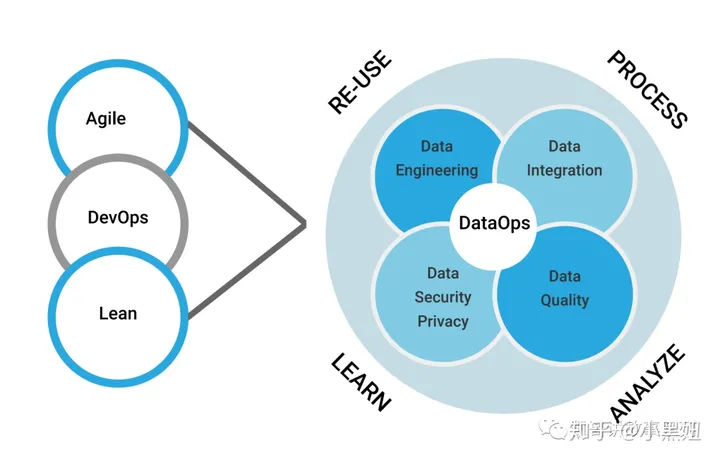
1. 数据工程/Data Engineering
DataOps的核心是数据工程能力,就是利用软件工程来处理和加工数据的能力,也就是从数据源到数据产品中间的过程。
一般包括数据清晰,数据处理,特征工程等过程。
2. 数据集成/Data Integration
在数据处理过程中,处理多样化的数据来源,让他们能够相互集成,相互补充,是DataOps里面很重要的能力,主要包括不同数据源系统,数据模型,数据平台,数据格式,数据标准等多方的集成处理过程。
3. 数据安全和隐私/Data Security & Privacy
在DataOps的全过程中,如何能够提供全方位,端到端的数据安全和隐私的管理支撑,是非常重要的核心功能,所以行业里有时候也称其为:DataSecOps。
4. 数据质量/Data Quality
数据质量管理是DataOps的重要价值和能力,我们一般用下面的7个维度来度量数据的质量,一致性,准确性,可靠性,有序性,唯一性和及时性:
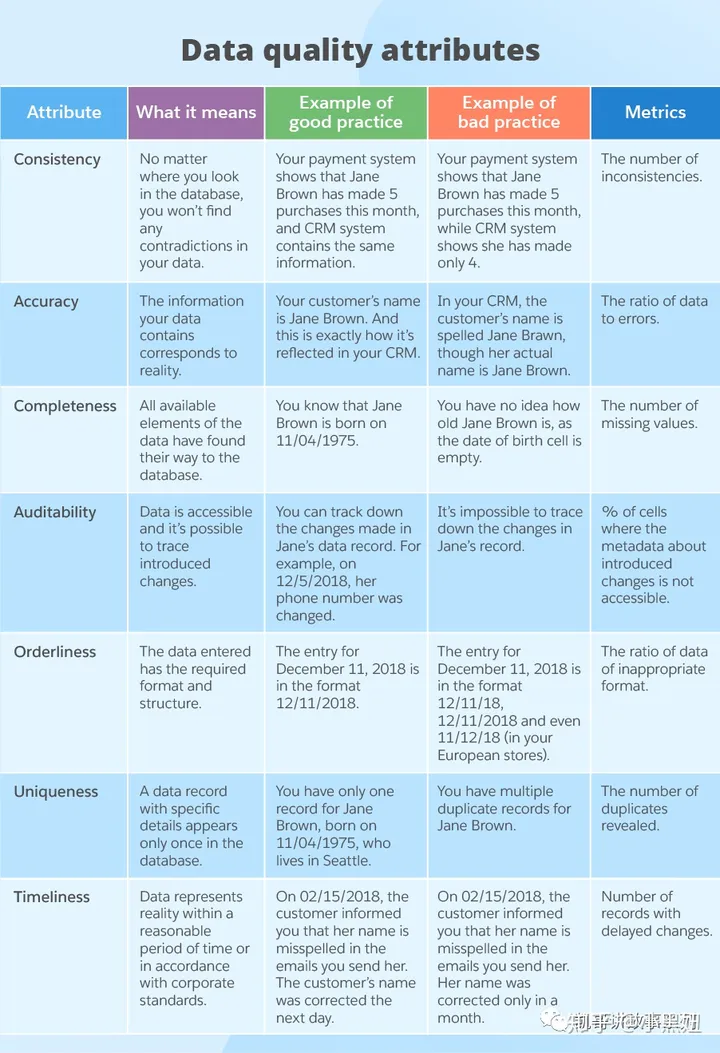
成功DataOps的五大特点CAUTA
1. 持续/Continuous
DataOps首要保证的就是尽可能的持续性,不间断,不论什么样的情况出现,都能够自适应的持续让Data Pipeline流动起来,所以持续性是DataOps的首要特质。
持续性可以总结为三个关键点:
- 保证当流数据和元数据发生变化时能够持续
- 交易系统数据日志数据对于DataOps的最小影响
- 对于所有的源系统和目标系统都有一定的优化
2. 敏捷Agilitly
在持续的基础上,DataOps需要一定的敏捷性,能够快速响应外部的各种变化,主要从三个角度:
- 支持多种部署模式,公有云,私有云
- 自动支持数据湖和数据仓库
- 支持未来的架构变化
3. 全面/Universal
作为企业全域数据的底座,DataOps要全面的支持所有的场景和数据,如下图所示例,列示出了常用的30种数据源和40种目标数据。
4. 可信/Trust
数据的可信包括三个层面:
- 数据目录:保证数据资产和用户产生的数据集的可访问性
- 数据血缘:能够清晰的知道数据从哪里来的,是怎么被加工和处理的过程
- 数据验证:确保每一个源数据在变化的时候所有相关的数据集也被复制和更新
只有满足以上的三点要求,才能被认为数据是可信的。
5. 自动/Automation
自动化是DataOps的重要基础能力,从数据的产生,处理到交付数据产品和服务,整个过程要尽可能的自动化处理。


















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











