









数组处理
array_contains
判断ARRAY数组a中是否存在元素v。
boolean array_contains(array<T> <a>, value <v>)
array_intersect
求两个数组之间的交集
array_union
求两个数组之间的并集
array_expect
求两个数组之间的差集
select
array_intersect(array(1, 2), array(2, 3)) i,
array_union(array(1, 2), array(2, 3)) u,
array_except(array(1, 2), array(2, 3)) e; ![]()
聚合函数
count
从执行结果来看
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计
从执行效率来看
- 如果列为主键,count(列名)效率优于count(1)
- 如果列不为主键,count(1)效率优于count(列名)
- 如果表中存在主键,count(主键列名)效率最优
- 如果表中只有一列,则count(*)效率最优
- 如果表有多列,且不存在主键,则count(1)效率优于count(*)
参考:HiveSql面试题11详解(count(1)、count(*)和count(列名)的区别)_hive count1和count*的区别-CSDN博客
分析函数导图

排名函数
row_number
排序相同时不会重复,唯一标记一条记录,顺序排名
SELECT
val,
row_number() over(ORDER by val) rn,
rank() over(ORDER by val) rk,
dense_rank() over(ORDER by val) drk
from (
select 1 as val
union all
select 1
union all
select 2
union all
select 2
union all
select 3
);
rank
排序相同时会重复,总数不变,跳跃排名
dense_rank
排序相同时会重复,总数会减少,等位排名
ntile
HIveSQL面试题17---按照某个字段进行动态分桶_hive sql 字段 分桶_莫叫石榴姐的博客-CSDN博客参考: HIveSQL面试题17---按照某个字段进行动态分桶_hive sql 字段 分桶_莫叫石榴姐的博客-CSDN博客
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值。将一个有序的数据集划分为多个桶(bucket),并为每行分配一个适当的桶数(切片值,第几个切片,第几个分区等概念)。它可用于将数据划分为相等的小切片,为每一行分配该小切片的数字序号。
NTILE不支持ROWS BETWEEN,比如NTILE(2) OVER(PARTITION BY dept_no ORDER BY salary ROWS BETWEEN 3 PRECEDING - AND CURRENT ROW)。
如果切片不均匀,默认增加第一个切片的分布。
Ntile函数使用
可以看成是:它把有序的数据集合平均分配到指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。(这个算法在很多当中使用,spark中数据分片的时候也是这个算法,只不过是不均匀的时候,优先分配给较大编号的分片,如下图所示)
语法是:ntile (num) over ([partition_clause] order_by_clause) as your_bucket_num
然后可以根据桶号,选取前或后 n分之几的数据。
数据会完整展示出来,只是给相应的数据打标签;具体要取几分之几的数据,需要再嵌套一层根据标签取出。
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
ntile 用于将分组数据按照顺序切分成n片(n桶),返回当前切片值(桶序号).切片值就是桶的序号。类似于hive中分桶,用于求百分比。
对于一组数字(1,2,3,4,5,6),ntile(2)切片后为(1,1,1,2,2,2)
(1,2,3,4,5,6,7),ntile(2)切片后为(1,1,1,1,2,2,2)
其序号的标定类似于hive中分桶的原理。
又叫分桶函数或分片函数。ntile(n),n表示分桶或分片的个数。
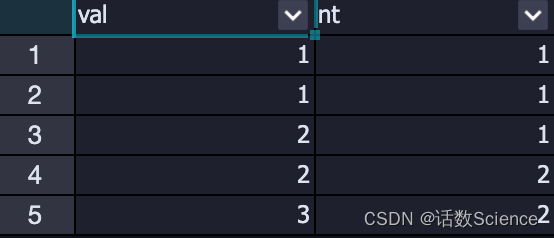
SELECT
val,
ntile(2) over(ORDER by val) nt
from (
select 1 as val
union all
select 1
union all
select 2
union all
select 2
union all
select 3
);
percent_rank
percent_rank() 函数为分布函数:
- 用于返回某个排序数值在数据集中的百分比排位,其值分布在0-1之间【0,1】
- 此函数用于计算数值在数据集内的相对位置。
- 计算公式:当前行rn -1 / 组内行数 -1 其中减去1表示排位时候不包括他本身,表示他前面有多少人比他值低或高,在实际中有一定分析意义。
- 使用场景:用于关心排在我前面的有多少人。
- 如:班级成绩为例,返回的百分数60%表示某个分数排在班级总分排名前60%。
- 比如站队:我往往关心的是排在我前面的有多少人。如下一组数据:
- 如成绩为20的人,排在他前面的有5个人,除去自身,总共有6个人,那么他的相对排名百分比为 5/6
- 成绩为10的,排在他前面的有6个人,除去自身,那么整个群体中都比他的分数高,所以也就是100%
-
注意点:(1)percent_rank()对重复值的处理(2)percent_rank()对NULL值的处理
-
特点:首尾一定是0 和1
-
cume_dist():累积百分比
和percent_rank()差不多,区别在于是否排除自身影响
含义:
升序排序:表示小于等于当前值的人数所占百分比
降序排序:大于等于当前值的人数所占百分比 -
举例一:求去除最大最小值后的平均值
with salary as ( select '10001' emp_num , '1' dep_num , '60117' salary union all select '10002' emp_num , '2' dep_num , '92102' salary union all select '10003' emp_num , '2' dep_num , '86074' salary union all select '10004' emp_num , '1' dep_num , '66596' salary union all select '10005' emp_num , '1' dep_num , '66961' salary union all select '10006' emp_num , '2' dep_num , '81046' salary union all select '10007' emp_num , '2' dep_num , '94333' salary union all select '10008' emp_num , '1' dep_num , '75286' salary union all select '10009' emp_num , '2' dep_num , '85994' salary union all select '10010' emp_num , '1' dep_num , '76884' salary ) SELECT dep_num,cast(avg(salary) as decimal(18,0)) as avg_salary from( SELECT emp_num ,dep_num ,salary ,PERCENT_RANK() over(PARTITION BY dep_num ORDER BY salary) as rate from salary ) t where rate != 0 and rate != 1 group by dep_num; -
举例二

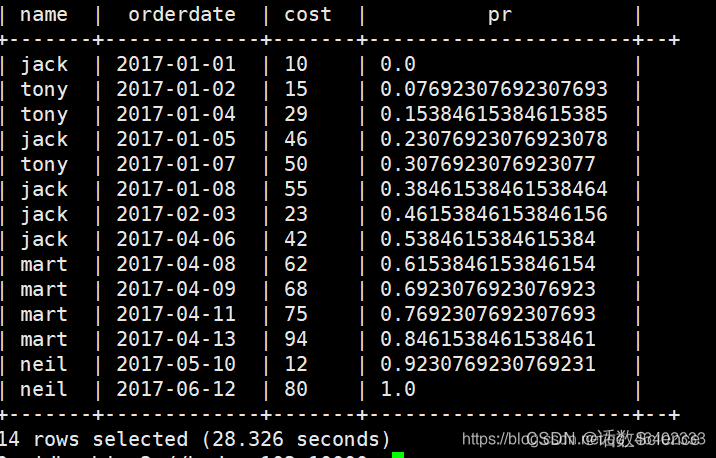
参考:HiveSql一天一个小技巧:如何巧用分布函数percent_rank()求去掉最大最小值的平均薪水问题_hive percent_rank_莫叫石榴姐的博客-CSDN博客
cume_dist
计算一行在组中的相对位置。小于等于当前值的行数/分组内总行数。
with student as (
select '001' as classId,'001' as stuId,'math' as course,15 as score
union all
select '001','002','math',20
union all
select '001','003','math',35
union all
select '001','004','math',40
union all
select '001','005','math',48
union all
select '001','006','math',60
union all
select '001','007','math',69
union all
select '001','008','math',80
union all
select '001','009','math',89
union all
select '001','010','math',100
union all
select '001','001','english',99
union all
select '001','002','english',100
union all
select '001','003','english',87
union all
select '001','004','english',10
union all
select '001','005','english',50
union all
select '001','006','english',30
union all
select '001','007','english',58
union all
select '001','008','english',68
union all
select '001','009','english',78
union all
select '001','010','english',89
union all
select '002','001','math',15
union all
select '002','002','math',20
union all
select '002','003','math',35
union all
select '002','004','math',40
union all
select '002','005','math',48
union all
select '002','006','math',60
union all
select '002','007','math',69
union all
select '002','008','math',80
union all
select '002','009','math',89
union all
select '002','010','math',100
union all
select '002','001','english',99
union all
select '002','002','english',100
union all
select '002','003','english',87
union all
select '002','004','english',10
union all
select '002','005','english',50
union all
select '002','006','english',30
union all
select '002','007','english',58
union all
select '002','008','english',68
union all
select '002','009','english',78
union all
select '002','010','english',89
)
select
stuId,classId,course,score,percent_part
from (
select
stuId,classId,course,score,
cume_dist() over (partition by classId order by score) as percent_part
from
student
where
course = 'math'
) tmp
where tmp.percent_part > 0.8;
列转行
collect_set
将多行某些列的多行进行去重合并
参考:【hive】列转行—collect_set()/collect_list()/concat_ws()函数的使用场景_collect_list函数-CSDN博客
参考:hive中collect_set() over()结合使用_mob649e815375e5的技术博客_51CTO博客
collect_list
将多行某些列的多行进行合并
- collect_list()的底层是使用ArrayList来实现的,当put到这个ArrayList的时候,不一定哪个Mapper先,哪个Mapper后,所以会出现4、5、6在1、2、3前面的可能性,所以通过row_number() over()排序再collect_list,只能实现局部有序,而不能实现全局有序
concat_ws
CONCAT_WS 可以将数组使用制定分隔符进行元素拼接
注意区分concat函数和concat_ws函数
- concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL
- concat_ws函数在连接字符串的时候,只要有一个字符串不是NULL,就不会返回NULL。
sort_array
可以通过sort_array将collect_list的数组进行排序
行转列
join
with t as (
select '001' as partner , '原始证件号' as label,'9111030275820228X7' as value
union all
select '001' as partner , '统一社会信用代码' as label,'8111030275820228X7' as value
union all
select '002' as partner , '原始证件号' as label,'6111030255820228Y7' as value
union all
select '002' as partner , '统一社会信用代码' as label,'5111030255820228Y7' as value
)
select t1.partner
,t1.value as a
,t2.value as b
from (
select partner, value from t where label='原始证件号'
) t1 join (
select partner, value from t where label='统一社会信用代码'
) t2
on t1.partner = t2.partner
;max
with t as (
select '001' as partner , '原始证件号' as label,'9111030275820228X7' as value
union all
select '001' as partner , '统一社会信用代码' as label,'8111030275820228X7' as value
union all
select '002' as partner , '原始证件号' as label,'6111030255820228Y7' as value
union all
select '002' as partner , '统一社会信用代码' as label,'5111030255820228Y7' as value
)
select partner
,max(case when label='原始证件号' then value else null end) as a
,max(case when label='统一社会信用代码' then value else null end) as b
from t
group by partner
;str_to_map
with t as (
select '001' as partner , '原始证件号' as label,'9111030275820228X7' as value
union all
select '001' as partner , '统一社会信用代码' as label,'8111030275820228X7' as value
union all
select '002' as partner , '原始证件号' as label,'6111030255820228Y7' as value
union all
select '002' as partner , '统一社会信用代码' as label,'5111030255820228Y7' as value
)
select partner
,mmap['原始证件号'] as a
,mmap['统一社会信用代码'] as b
from
(select partner
,str_to_map(concat_ws(',',collect_list(concat_ws(':',label,value))),',',':' ) as mmap
from t
group by partner
) t
+----------+---------------------+---------------------+
| partner | a | b |
+----------+---------------------+---------------------+
| 002 | 6111030255820228Y7 | 5111030255820228Y7 |
| 001 | 9111030275820228X7 | 8111030275820228X7 |
+----------+---------------------+---------------------+
2 rows selected (1.178 seconds)常用函数
coalesce
COALESCE是一个函数, (expression_1, expression_2, ...,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。
nvl
hive中的nvl函数为判断是否为空值,和oracle判断空值使用的函数一致。nvl叫做空值转换函数。
NVL函数的格式如下:NVL(expr1,expr2)
在mysql和sqlsever中分别使用的是nullif和ifnull
coalesce与nvl区别
NVL:如果第一个值为NULL取默认值,默认值是自己赋值上去的是个常数。支持两个参数。其本质是个函数。
SELECT nvl(nvl(nvl(nvl(nvl(c1, c2), c3), c4), c5), c6) AS c FROM v;coalesce:如果第一个参数为空就取第二个参数的值,第二个参数可以为常数也可以为表达式(字段,语句等)。以此类推,支持多个参数。更常用,其本质是个语句,更像个if语句,效率更高,建议使用。
SELECT COALESCE(C1, C2, C3, C4, C5, C6) AS c FROM V;字符串处理
instr
字符串查找函数:
语法: instr(string str, string substr)
返回值: int
说明:返回字符串 substr 在 str 中首次出现的位置
select instr('abcdf','df') --4find_in_set
语法: find_in_set(string str, string strList)
返回值: int
说明: 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回:0
select find_in_set('de','ef,ab,de'); --3
select find_in_set('de','ef,ab,def'); --0locate
语法:locate(string substr, string str[, int pos])
返回值:int
说明:返回字符串 substr 在 str 中从 pos 后查找,首次出现的位置
我们知道locate()函数可以判断某个字符在字符串中的位置,如果不在该字符串中返回0值,如果在返回字符对应的索引位置。
select locate('1','10002,21002,11001,11001') --1
select locate('a','abcda',1) --1
select locate('a','abcda',2) --5like
不推荐,效率低:locate > regexp > like
select '10002,21002,11001,11001' like '%1%'; --trueregexp
用regexp正则匹配。注意此时regxp()里面的正则为regexp('.*1.*')
select '10002,21002,11001,11001' regexp('.*1.*'); --truetranslate
string translate(string|varchar <str1>, string|varchar <str2>, string|varchar <str3>)
将str1出现在str2中的每个字符替换成str3中相对应的字符。无匹配则不替换。
- translate(input, from, to)
- input:输入字符串【集是要被替换的字符串】
- from:需要匹配的字符【即需要被替换的字符】,这里一定要注意是字符不是字符串
- to :用哪些字符来替换被匹配到的字符
- 注意点:这里from的字符与to字符在位置上存在一 一对应关系,也就是from中每个位置上的字符用to中对应位置的字符替换。
注意translate()与replace()替换的区别:
- translate():为字符替换只要字符在输入串中匹配到就会将该字符按照to中对应的字符替换。from 与to:位置上一一对应,单个字符替换
- replace():是严格按照from指定的字符串替换成to中的字符串。from与to:没有位置上对应关系,就是整体串上的替换
--如果 from 字符串长度>to的字符串长度 ,例如TRANSLATE('abcdef-abcdef','adbc','123') 意思是把 a替换为1,b替换为2,c替换为3,d替换为空,即删除掉。
select TRANSLATE('abcdef-abcdef','abcd','123'), --123ef-123ef
--如果 from里有重复字符 比如abca,1231,重复的字符a对应to的替换不会起作用
select TRANSLATE ('abcdaabbaaabbb','aa','12')--1bcd11bb111bbb;--1bcd11bb111bbb
--from长度<to的长度,不报错但是to里面长的字符没有意义
select TRANSLATE ('abcdaabbaaabbb','a','123')--1bcd11bb111bbb
举例:计算数组中非零元素的个数
SELECT concat_ws(',',array('0','1','3','6','0'));--0,1,3,6,0
SELECT translate(concat_ws(',',array('0','1','3','6','0')),',0','');--136
SELECT translate(concat_ws(',',array('0','1','3','6','0')),'0,','');--136replace
string replace(string <str>, string <old>, string <new>)
将字符串中与指定字符串匹配的子串替换为另一字符串。
regexp_replace
string regexp_replace(string <source>, string <pattern>, string <replace_string>[, bigint <occurrence>])
将source字符串中第occurrence次匹配pattern的子串替换成指定字符串replace_string后返回结果字符串。
length
计算字符串str的长度。
区别:size(array | map)
repeat
string repeat(string <str>, bigint <n>)
返回将str重复n次后的字符串。
lpad
string lpad(string <str1>, int <length>, string <str2>)
用字符串str2将字符串str1向左补足到length位。
select lpad('a',3,'z'); --zzarpad
string rpad(string <str1>, int <length>, string <str2>)
用字符串str2将字符串str1向左补足到length位。
select rpad('a',3,'z'); --azzJSON处理
get_json_object
语法:get_json_object(json_string, '$.key')
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。这个函数每次只能返回一个数据项。
select get_json_object('{"name":"zhangsan","age":18}','$.name');
--zhangsan
select
get_json_object('{"name":"zhangsan","age":18}','$.name'),
get_json_object('{"name":"zhangsan","age":18}','$.age');
--zhangsan 18json_tuple
语法:json_tuple(json_string, k1, k2 ...)
说明:解析json的字符串json_string,可指定多个json数据中的key,返回对应的value。如果输入的json字符串无效,那么返回NULL。注:tuple:元
注意:上面的json_tuple函数中没有$. 如果在使用json_tuple函数时加上$.就会解析失败:
select
b.name
,b.age
from tableName a lateral view
json_tuple('{"name":"zhangsan","age":18}','name','age') b as name,age;
--zhangsan 18解析JsonArray
需要使用到其他函数:explode和regexp_replace
--第一步:把一个json数组转化为多个json字符串
SELECT explode(split(
regexp_replace(
regexp_replace(
'[
{"website":"baidu.com","name":"百度"},
{"website":"google.com","name":"谷歌"}
]',
'\\[|\\]' , ''), --将json数组两边的中括号去掉
'\\}\\,\\{' , '\\}\\;\\{'), --将json数组元素之间的逗号换成分号
'\\;') --以分号作为分隔符(split函数以分号作为分隔)
);
--{"website":"baidu.com","name":"百度"}
--{"website":"google.com","name":"谷歌"}
--为什么要将json数组元素之间的逗号换成分号?
--因为元素内的分隔也是逗号,如果不将元素之间的逗号换掉的话,后面用split函数分隔时也会把元素内的数据给分隔,这不是我们想要的结果。
--第二步:使用json_tuple来解析
SELECT json_tuple(json, 'website', 'name')
FROM (
SELECT explode(split(regexp_replace(regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;'))
as json) t;
--www.baidu.com 百度
--google.com 谷歌又比如:
| goods_id | json_str |
|---|---|
| 1,2,3 | [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}] |
select good_id,get_json_object(sale_json,'$.monthSales') as monthSales
from tableName
LATERAL VIEW explode(split(goods_id,','))goods as good_id
LATERAL VIEW explode(split(regexp_replace(regexp_replace(json_str , '\\[|\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;')) sales as sale_json;数字处理
percentile和percentile_approx
hive中有两个函数percentile和percentile_approx,可以用来计算分位数。如上四分位数,下四分位数,中位数等
而中位数即2分位数,那么同样可以使用该函数计算。具体使用方如下:
- percentile:percentile(col, p) col是要计算的列(值必须为int类型,否则报类型不对错误),p的取值为0-1,若为0.5,那么就是2分位数,即中位数。
- percentile_approx:percentile_approx(col, p)。列col为数值类型也可以。
- percentile_approx还有一种形式percentile_approx(col, p,B),参数B控制内存消耗的近似精度,B越大,结果的精度越高,越耗内存,执行效率越低。默认值为10000。当col字段中的distinct值的个数小于B时,结果就越接近准确的百分位数。也就是说后台执行的过程是先做了一个select distinct col limit B,然后排序得到分位数。如果distinct值特别多的情况下,仅仅是去重就是一个巨大的运算负担,更别说排序了。有时候计算的时候,往往会卡在map阶段不动,而当把B从10000调到100的时候很快就能跑出来了。
- 真正的中位数只能用percentile来计算,输入需要为整数类型,使用percentile_approx(输入为浮点型)计算得到的并不是真正的中位数,也就是所说的近似中位数,经过大量数据验证,有时候这个近似中位数和真正的中位数差别还是很大的。
如何对有小数的数据求取中位数呢?
可以把小数转换为整数,然后再求取中位数(如原有的字段值保留小数后✖️乘10000或100等转换成整数)
rand
语法: rand(),rand(int seed)函数
返回值: double随机数
说明:返回一个0到1范围内的随机数。若是指定种子seed,则会等到一个稳定的随机数序列。
> select rand();
0.9629742951434543
> select rand(0);
0.8446490682263027
> select rand(null);
0.8446490682263027ps:如果想要取的0-9或者1-10之间的随机数,x10后向下向上取整即可
select cast(floor(rand() * 10) as int)
select cast(ceiling(rand() * 10) as int)pmod
pmod(int a, int b)
pmod(double a, double b)
返回a除以b的余数的绝对值
select pmod(10,4); --2round
round(x,y):round是四舍五入函数,无y值时默认保留整数,y值大于零时,意为小数点后保留位数,小于零时,是在整数的基础上四舍五入,比如round(129,-1),结果为130
select round(1.455, 2) #结果是:1.46,即四舍五入到十分位
select round(1.5) #默认四舍五入到个位,结果是:2
select round(255, -1) #结果是:260,即四舍五入到十位,此时个位是5会进位floor
floor(x):向下取整
select floor(1.4) # 结果是:1ceil
ceiling(x) 或 ceil(x):向上取整
select ceil(1.4) #结果是:2cast
cast(x as y):这个函数是个重点,它用来做类型装换,可以将x转换为y类型,如cast(123.4 as int),结果为123
decimal
decimal(m,n)表示数字总长度为m位,小数位为n位,那么整数位就只有m-n位了。这与MySql是不一样的,MySql就直接表示整数位为m位了。
日期处理
--------------------------月度计算--------------------------
-- 上月末
SET odps.sql.hive.compatible = true;
select date_sub(trunc(current_date, 'MM'), 1);
-- 上月初
SET odps.sql.hive.compatible = true;
select trunc(add_months(current_date, -1), 'MM');
-- 本月初
SET odps.sql.hive.compatible = true;
select trunc(current_date, 'MM');
-- 本月末
SET odps.sql.hive.compatible = true;
select last_day(current_date());
-- 本周一
SET odps.sql.hive.compatible = true;
--周一:MO;周二:TU;周三:WE ;周四:TH ;周五:FR ;周六:SA;周日SU
select date_sub(next_day(current_date, 'MO'), 7);
-- 本周末
SET odps.sql.hive.compatible = true;
select date_sub(next_day(current_date, 'MO'), 1);
-- 上周一
SET odps.sql.hive.compatible = true;
select date_sub(next_day(current_date, 'MO'), 14);
-- 上周末
SET odps.sql.hive.compatible = true;
select date_sub(next_day(current_date, 'MO'), 8);
-- 根据当前日期得出星期几
--0 当等于0是当前天为星期日
--1 当等于1是当前天为星期1
--2 当等于2是当前天为星期2
--3 当等于3是当前天为星期3
--4 当等于4是当前天为星期4
--5 当等于5是当前天为星期5
--6 当等于6是当前天为星期6
SET odps.sql.hive.compatible = true;
select pmod(datediff(current_date, '2012-01-01'), 7);
--------------------------季度计算--------------------------
--季度初方法一
SET odps.sql.hive.compatible = true;
select concat_ws('-', cast(year(current_date) as string), cast(ceil(month(current_date()) / 3) * 3 - 2 as string), '1');
--季度初方法二
SET odps.sql.hive.compatible = true;
select case quarter(current_date)
when 1 then concat(year(current_date), '-01-01')
when 2 then concat(year(current_date), '-04-01')
when 3 then concat(year(current_date), '-07-01')
when 4 then concat(year(current_date), '-10-01')
end as q_first_day;
--获取季度末的方法
--ceil(当前月份 / 3 ):获取当前时间所处的季度(Hive高版本可用quater()函数代替)
SET odps.sql.hive.compatible = true;
--ceil(当前月份 / 3 ) *3:得到当前月份所处的季度末月份
--ceil(当前月份 / 3 ) *3 - 2 :获取当前月份所处的季度初的月份
--ceil(当前月份 / 3 ) *3 + 1 :获取当前月份所处的季度的下一个季度初的月份
select date_sub(concat_ws('-', cast(year(current_date) as string), cast(ceil(month(current_date()) / 3) * 3 + 1 as string), '1'),1);
--------------------------年度计算--------------------------
--关于年的计算
SET odps.sql.hive.compatible = true;
--年开始日期
select trunc(current_date, 'YYYY');
--年结束的日期
SET odps.sql.hive.compatible = true;
select date_sub(trunc(add_months(current_date, 12), 'YYYY'), 1);
unix_timestamp
unix_timestamp函数用法(输入为string形式,输出为bigint形式)
unix_timestamp() 得到当前时间戳(秒数)
- 如果参数date满足yyyy-MM-dd HH:mm:ss形式,则可以直接unix_timestamp(string date) 得到参数对应的时间戳
- 如果参数date不满足yyyy-MM-dd HH:mm:ss形式,则我们需要指定date的形式,在进行转换
- 如输入时间为2021-06-18,那么后面就需要指定时间格式,因为标准的格式为yyyy-MM-dd HH:mm:ss形式否则返回NULL
--标准形式,不用指定格式
hive> select unix_timestamp('2021-06-18 10:11:12');
OK
1623982272
Time taken: 0.258 seconds, Fetched: 1 row(s)
--非标准形式,不指定格式返回NULL
hive> select unix_timestamp('2021-06-18');
OK
NULL
Time taken: 0.342 seconds, Fetched: 1 row(s)
--非标准形式,需要指定格式
hive> select unix_timestamp('2021-06-18','yyyy-MM-dd');
OK
1623945600
Time taken: 0.782 seconds, Fetched: 1 row(s)
--Hive中处理毫秒级别的时间戳
select to_utc_timestamp(1623982272358, 'GMT');
hive> select to_utc_timestamp(1623982272358, 'GMT');
OK
2021-06-18 10:11:12.358
Time taken: 0.468 seconds, Fetched: 1 row(s)
---Hive获取系统毫秒级的时间戳
select current_timestamp()
,cast(current_timestamp() as double)*1000 as msg_time
hive> select current_timestamp()
> ,cast(current_timestamp() as float)*1000 as msg_time;
OK
2021-06-19 17:36:52.708 1.62409533E12
Time taken: 0.323 seconds, Fetched: 1 row(s)
--hive对毫秒级别时间戳的处理公式
where from_unixtime(cast(substr(msg_time,1,10) as bigint),'yyyy-MM-dd')='$lastday'trunc
查询当月、当季、当年第一天
- select trunc('2020-12-03','MM'); --2020-12-01
- select trunc('2020-12-03','Q'); --2020-10-01 hive3.0开始支持
- select trunc('2020-12-03','YEAR'); --2020-01-01
- select trunc('2020-12-03','Y'); --2020-01-01
- select trunc('2020-12-03','YYYY'); --2020-01-01
last_day
last_day(string date) — 返回该月最后一天的日期
select last_day(current_date());--2023.11.27该月的最后一天2023-11-30next_day
- 返回date之后的下一个周的dayOfWeek的天
- next_day(string date,string dayOfWeek)
select next_day(current_date,'MO'); --2023.11.27之后的周一2023-12-04current_date()或current_date
当前日期
select current_date; --2023-11-27add_months
add_months(string date,int months) — 返回months月之后的date,months可以是负数
select add_months(current_date(),1); --当前2023-11-27的下月2023-12-27months_between
语法:months_between(date1, date2)
返回值: double
描述: 返回两日期的间隔月份
select months_between('2023-11-27', '2023-09-26'); --2.032258064516129to_date
- 语法:to_date(string timestamp)
- 返回值: 2.1.0版本前返回string,2.1.0版本后返回date
- 描述: 将一个字符串date按照"yyyy-MM-dd"格式转成日期值.
select to_date(current_timestamp); --2023-11-27date_format
格式化日期:date_format(date, 'yyyy-MM-dd')
datediff
求日期间隔天数:date_diff(end_date, start_date)
date_add
语法:date_add(date/timestamp/string startdate, tinyint/smallint/int days)
返回值: 2.1.0版本前返回string,2.1.0版本后返回date
描述:返回开始日期startdate增加天数days后的日期
select date_add('2023-11-27', 5); --2023-12-02date_sub
语法: date_sub(date/timestamp/string startdate, tinyint/smallint/int days)
返回值: 2.1.0版本前返回string,2.1.0版本后返回date
描述: 返回开始日期startdate减少天数days后的日期
select date_sub('2023-11-27', 5); --2023-11-22year
语法:year(string date)
返回值:int
描述:提取日期中的年份部分
select year(current_timestamp); --2023month
语法:month(string date)
返回值: int
描述:提取日期中的月份部分
select month(current_timestamp); --11hour
语法:hour(string date)
返回值:int
描述:提取日期中的小时部分
select hour(current_timestamp); --18dayofweek
获取当前日期的星期几。这里本周的第一天是周日,使用时候注意转换。Hive低版本没有该函数,Hive2.1版本之后才有,如果版本较低建议使用pmod方法获取当前日期的星期几,参考下文。
select dayofweek('2023-11-27 18:25:22'); --2 周一weekofyear
语法:weekofyear(string date)
返回值:int
描述: 返回指定日期处于当年的第几周
select weekofyear('2022-05-29'); --48quarter
获取当前日期所处的季度
select quarter('2023-11-27 18:30:22'); --4
--低版本没有该函数,可以用ceil(month(date) / 3)来代替
select CEIL(month('2023-11-27 18:30:22') / 3); --4炸裂函数
| 函数 | 作用 | 举例 |
|---|---|---|
| explode | 一行变多行 | [1,2,3] 1 2 3 |
| posexplode | 一行变多行,附带索引 | [1,2,3] 0 1 1 2 2 3 |
lateral view
1.Lateral View 用于 和UDTF函数【explode,split】结合来使用。
2.首先通过UDTF函数将数据拆分成多行,再将多行结果组合成一个支持别名的虚拟表。
3.主要解决在select使用UDTF做查询的过程中查询只能包含单个UDTF,不能包含其它字段以及多个UDTF的情况。
4.语法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
lateral:侧,外侧,横,横向
lateral view outer
lateral view 与 lateral view outer的区别:
主要就是当explode函数里传入的数据是否为null,
- lateral view explode(null) temp as id 时,结果不显示任何数据(注意是指其他字段的数据也不返回);
- lateral view outer explode(null) temp as id 时,结果显示其他字段是有数据的,但id显示为null。
explode
特点是不仅炸裂出数值,还附带索引,实现多列进行多行转换;
WITH temp AS ( SELECT '1,2,3' AS examp_data, 'hello' AS other)
SELECT
data,
other
FROM temp LATERAL VIEW explode(split(examp_data, ',')) view1 as data;
--结果
data other
1 hello
2 hello
3 hello
WITH temp AS
( SELECT 'a,b,c,d' as examp_data1,'2:00,3:00,4:00,5:00' as examp_data2)
SELECT
data1
,data2
FROM temp
LATERAL VIEW explode(split(examp_data1,',')) view1 as data1
LATERAL VIEW explode(split(examp_data2,',')) view1 as data2;
--结果
data1 data2
a 2:00
a 3:00
a 4:00
a 5:00
b 2:00
b 3:00
b 4:00
b 5:00
c 2:00
c 3:00
c 4:00
c 5:00
d 2:00
d 3:00
d 4:00
d 5:00posexplode
WITH temp AS
( select 'a,b,c,d' as examp_data1,'2:00,3:00,4:00,5:00' as examp_data2)
SELECT
index1
,data1
,index2
,data2
FROM temp
LATERAL VIEW posexplode(split(examp_data1,',')) view1 as index1,data1
LATERAL VIEW posexplode(split(examp_data2,',')) view1 as index2,data2
WHERE index1=index2;
--结果
index1 data1 index2 data2
0 a 0 2:00
1 b 1 3:00
2 c 2 4:00
3 d 3 5:00窗口函数
| 函数 | 作用 | 说明 |
|---|---|---|
| count(1) over() | 窗口内条目数 | |
| sum() over() | 窗口内累计值 | |
| max() over() | 最大值 | |
| row_number() over() | 排序 | |
| rank() over() | 排序 | |
| first_value() over() | 截止到当前行,第一个值 | |
| last_value() over() | 截止到当前行,最后一个值 | |
| lead() over() | 往下第n行 | |
| lag() over() | 往上第n行 |
总结:
不指定窗口时,不排序默认第一行到最后一行,排序默认第一行到当前行
rows between
指定窗口时 --rows between 起始位置 and 结束位置
- N preceding:往前多少行
- N following:往后多少行
- current row:当前行
- unbounded:起点或者终点,没有边界
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
range between
rows表示行,就是前n行,后n行
而range表示的是具体的值,比这个值小n的行,比这个值大n的行
range between是以当前值为锚点进行计算,比如:
range between 4 preceding AND 7 following表示:如果当前值为10的话就取前后的值在6到17之间的数据。
sum(close) range between 100 preceding and 200 following
则通过字段差值来进行选择。如当前行的 close 字段值是 200,那么这个窗口大小的定义就会选择分区中 close 字段值落在 100 至 400 区间的记录(行)。
应用举例:求近30天周期内累计消费金额
sum(price) over(partition by user_id order by date rows between preceding 30 and current row)
--上面通过rows between不准确,因为会存在时间缺失的记录,所以要用range between
sum(price) over(partition by user_id order by cast (date as date) range between preceding 30 and current row)
参考:HiveSQL一天一个小技巧:如何准确求近30天指标?_hive sql 近30天_莫叫石榴姐的博客-CSDN博客
窗口聚合函数:SUM、AVG、COUNT、MAX、MIN
以SUM为例
总结:如果不使用 over(),窗口大小是针对查询产生的所有数据
功能:用于实现数据分区后的聚合
语法:fun_name(col1) over (partition by col2 order by col3)
示例:实现分区内的累加,其他的原理类似
不指定窗口时,不排序默认第一行到最后一行,排序默认第一行到当前行
指定窗口时
- rows between 起始位置 and 结束位置
- N preceding:往前多少行
- N following:往后多少行
- current row:当前行
- unbounded:起点或者终点,没有边界
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
参考:Hive--开窗函数--窗口聚合函数:SUM、AVG、COUNT、MAX、MIN_count窗口函数-CSDN博客
FIRST_VALUE
- 功能:取每个分区内某列的第一个值
- 语法:FIRST_VALUE(col,true/false) over (partition by col1 order by col2)
- 第二个参数为true,跳过空值(默认为false)
LAST_VALUE
- 功能:取每个分区内某列的最后一个值
- 语法:LAST_VALUE(col,true/false) over (partition by col1 order by col2)
- 第二个参数为true,跳过空值(默认为false)
LAG
- 功能:取每个分区内某列的前面的第N个值
- 语法:LAG(col,N,defaultValue) over (partition by col1 order by col2)
LEAD
- 功能:取每个分区内某列的后面的第N个值
- 语法:LEAD(col,N,defaultValue) over (partition by col1 order by col2)
first_value
last_value
row_number
rank
lag
LAG(col, n, DEFAULT) 用于统计窗口内往上第n行值
- 参数1:列名
- 参数2:往上第n行(可选,默认为1)
- 参数3:默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
lag:落后于
CREATE TABLE IF NOT EXISTS test_login_log
(
cookieid STRING,
createtime STRING,
url STRING
);
INSERT OVERWRITE TABLE test_login_log VALUES
('cookie1','2015-04-10 10:00:02','url2'),
('cookie1','2015-04-10 10:00:00','url1'),
('cookie1','2015-04-10 10:03:04','url3'),
('cookie1','2015-04-10 10:50:05','url6'),
('cookie1','2015-04-10 11:00:02','url7'),
('cookie1','2015-04-10 10:10:00','url4'),
('cookie1','2015-04-10 10:50:01','url5'),
('cookie2','2015-04-10 10:00:02','url22'),
('cookie2','2015-04-10 10:00:00','url11'),
('cookie2','2015-04-10 10:03:04','url33'),
('cookie2','2015-04-10 10:50:05','url66'),
('cookie2','2015-04-10 11:00:00','url77'),
('cookie2','2015-04-10 10:10:00','url44'),
('cookie2','2015-04-10 10:50:01','url55');
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
LAG(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as last_1_time,
LAG(createtime,2) over (partition by cookieid order by createtime) as last_2_time
from test_login_log;
--结果
cookieid createtime url rn last_1_time last_2_time
cookie1 2015-04-10 10:00:00 url1 1 1970-01-01 00:00:00 \N
cookie1 2015-04-10 10:00:02 url2 2 2015-04-10 10:00:00 \N
cookie1 2015-04-10 10:03:04 url3 3 2015-04-10 10:00:02 2015-04-10 10:00:00
cookie1 2015-04-10 10:10:00 url4 4 2015-04-10 10:03:04 2015-04-10 10:00:02
cookie1 2015-04-10 10:50:01 url5 5 2015-04-10 10:10:00 2015-04-10 10:03:04
cookie1 2015-04-10 10:50:05 url6 6 2015-04-10 10:50:01 2015-04-10 10:10:00
cookie1 2015-04-10 11:00:02 url7 7 2015-04-10 10:50:05 2015-04-10 10:50:01
cookie2 2015-04-10 10:00:00 url11 1 1970-01-01 00:00:00 \N
cookie2 2015-04-10 10:00:02 url22 2 2015-04-10 10:00:00 \N
cookie2 2015-04-10 10:03:04 url33 3 2015-04-10 10:00:02 2015-04-10 10:00:00
cookie2 2015-04-10 10:10:00 url44 4 2015-04-10 10:03:04 2015-04-10 10:00:02
cookie2 2015-04-10 10:50:01 url55 5 2015-04-10 10:10:00 2015-04-10 10:03:04
cookie2 2015-04-10 10:50:05 url66 6 2015-04-10 10:50:01 2015-04-10 10:10:00
cookie2 2015-04-10 11:00:00 url77 7 2015-04-10 10:50:05 2015-04-10 10:50:01lead
与LAG相反 ,LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
- 第一个参数为列名,
- 第二个参数为往下第n行(可选,默认为1),
- 第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
lead:带领
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
LEAD(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as next_1_time,
LEAD(createtime,2) over (partition by cookieid order by createtime) as next_2_time
from
test_login_log;
--结果
cookieid createtime url rn next_1_time next_2_time
cookie1 2015-04-10 10:00:00 url1 1 2015-04-10 10:00:02 2015-04-10 10:03:04
cookie1 2015-04-10 10:00:02 url2 2 2015-04-10 10:03:04 2015-04-10 10:10:00
cookie1 2015-04-10 10:03:04 url3 3 2015-04-10 10:10:00 2015-04-10 10:50:01
cookie1 2015-04-10 10:10:00 url4 4 2015-04-10 10:50:01 2015-04-10 10:50:05
cookie1 2015-04-10 10:50:01 url5 5 2015-04-10 10:50:05 2015-04-10 11:00:02
cookie1 2015-04-10 10:50:05 url6 6 2015-04-10 11:00:02 \N
cookie1 2015-04-10 11:00:02 url7 7 1970-01-01 00:00:00 \N
cookie2 2015-04-10 10:00:00 url11 1 2015-04-10 10:00:02 2015-04-10 10:03:04
cookie2 2015-04-10 10:00:02 url22 2 2015-04-10 10:03:04 2015-04-10 10:10:00
cookie2 2015-04-10 10:03:04 url33 3 2015-04-10 10:10:00 2015-04-10 10:50:01
cookie2 2015-04-10 10:10:00 url44 4 2015-04-10 10:50:01 2015-04-10 10:50:05
cookie2 2015-04-10 10:50:01 url55 5 2015-04-10 10:50:05 2015-04-10 11:00:00
cookie2 2015-04-10 10:50:05 url66 6 2015-04-10 11:00:00 \N
cookie2 2015-04-10 11:00:00 url77 7 1970-01-01 00:00:00 \N分组函数
概述
- GROUPING SETS:根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
- GROUPING__ID:表示结果属于哪一个分组集合,属于虚字段
- CUBE:根据GROUP BY的维度的所有组合进行聚合。
- ROLLUP:为CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
grouping sets
CREATE TABLE test_student_year_score(
name string comment '姓名',
syear string comment '学年',
course string comment '科目',
score int comment '分数'
);
INSERT OVERWRITE TABLE test_student_year_score VALUES
('李四','2020','数学',60),
('李四','2020','语文',70),
('李四','2019','语文',80),
('张三','2020','数学',60),
('张三','2021','语文',90),
('王五','2020','语文',100);
SELECT
course,
syear,
AVG(score) as avgscore
FROM
test_student_year_score
GROUP BY
course,
syear;
--结果
course syear sumscore
数学 2020 60.0
语文 2019 80.0
语文 2020 85.0
语文 2021 90.0
SELECT
course,
syear,
AVG(score) as avgscore
FROM
test_student_year_score
GROUP BY
course,
syear
GROUPING SETS (
course,
syear,
(course, syear)
);
--结果
course syear avgscore
\N 2019 80.0
\N 2020 72.5
\N 2021 90.0
数学 \N 60.0
数学 2020 60.0
语文 \N 85.0
语文 2019 80.0
语文 2020 85.0
语文 2021 90.0grouping__id
grouping_id计算方法
grouping sets 中的每一种粒度,都对应唯一的 grouping__id 值,其计算公式与 group by 的顺序、当前粒度的字段有关。
具体计算方法如下:
- 将 group by 的所有字段 倒序 排列。
- 对于每个字段,如果该字段出现在了当前粒度中,则该字段位置赋值为1,否则为0。
- 这样就形成了一个二进制数,这个二进制数转为十进制,即为当前粒度对应的 grouping__id。
举例grouping sets class, sex, (class, sex) 的3种粒度的统计结果为例:
- group by 的所有字段倒序排列为:sex class
- 对于 3 种 grouping sets,分别对应的二进制数为:
序号 grouping set 给倒序排列的字段(sex class)赋值 对应的十进制(grouping__id 的值)
1 class 01 1
2 sex 10 2
3 class,sex 11 3
示例:group by c1,c2,c3 grouping sets(c1,c2,c3)
grouping__id:
0: ()
1:(c1)
2:(c2)
3:(c1,c2)
4:(c3)
5:(c1,c3)
6:(c2,c3)
7:(c1,c2,c3)
通过实践,每种组合的id已注定,不受grouping sets()中先后影响,但会受group by中key的先后影响,把c1与c2调换位置,那么结果中的grouping__id也会改变。
with cube
SELECT
course,
syear,
AVG(score) as avgscore
FROM
test_student_year_score
GROUP BY
course,
syear
WITH CUBE;
--结果
course syear avgscore
\N \N 76.66666666666667
\N 2019 80.0
\N 2020 72.5
\N 2021 90.0
数学 \N 60.0
数学 2020 60.0
语文 \N 85.0
语文 2019 80.0
语文 2020 85.0
语文 2021 90.0with rollup
SELECT
course,
syear,
AVG(score) as sumscore
FROM
test_student_year_score
GROUP BY
course,
syear
WITH ROLLUP;
--结果
course syear sumscore
\N \N 76.66666666666667
数学 \N 60.0
数学 2020 60.0
语文 \N 85.0
语文 2019 80.0
语文 2020 85.0
语文 2021 90.0总结:
- grouping sets()的灵活性最高
- group by rollup 是 grouping sets() 的部分
- group by cube 是 grouping sets() 的全部组合
















 2193
2193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











