










题目
- 1 讲一下你门公司的大数据项目架构?
- 2 你在工作中都负责哪一部分
- 3 spark提交一个程序的整体执行流程
- 4 spark常用算子列几个,6到8个吧
- 5 transformation跟action算子的区别
- 6 map和flatmap算子的区别
- 7 自定义udf,udtf,udaf讲一下这几个函数的区别,编写的时候要继承什么类,实现什么方法
- 8 hive创建一个临时表有哪些方法
- 9 讲一下三范式,三范式解决了什么问题,有什么优缺点
- 10 讲一下维度建模的过程
- 11 维度表有哪几种
- 12 事实表有几种
- 13 什么是维度一致性,总线架构,事实一致性
- 14 什么是缓慢变化维,有哪几种?
- 15 什么是拉链表,如何实现?
- 16 什么是微型维度、支架表,什么时候会用到
- 17 讲几个你工作中常用的spark 或者hive 的参数,以及这些参数做什么用的
- 18 工作中遇到数据倾斜处理过吗?是怎么处理的,针对你刚刚提的方案讲一下具体怎么实现。用代码实现,以及用sql实现。
- 19 讲一下kafka对接flume 有几种方式。
- 20 讲一下spark是如何将一个sql翻译成代码执行的,里面的原理介绍一下?
- 21 spark 程序里面的count distinct 具体是如何执行的
- 22 不想用spark的默认分区,怎么办?(自定义Partitioner 实现里面要求的方法 )具体是哪几个方法?
- 23 有这样一个需求,统计一个用户的已经曝光了某一个页面,想追根溯是从哪几个页面过来的,然后求出在这几个来源所占的比例。你要怎么建模处理?
- 23 说一下你对元数据的理解,哪些数据算是元数据
- 24 有过数据治理的经验吗?
- 25 说一下你门公司的数据是怎么分层处理的,每一层都解决了什么问题
- 26 讲一下星型模型和雪花模型的区别,以及应用场景
答案
1 讲一下你门公司的大数据项目架构?
实时流和离线计算两条线
数仓输入(客户端日志,服务端日志,数据库)
传输过程(flume,kafka)
数仓输出(报表,画像,推荐等)
2 你在工作中都负责哪一部分
离线数据:数仓建模、数据治理、业务开发、稳定性
3 Spark提交一个程序的整体执行流程
包括向yarn申请资源、DAG切割、TaskScheduler、执行task等过程
Spark运行的基本流程:
- 用户在
Driver端提交任务,初始化运行环境(SparkContext等) - Driver根据配置向
ResoureManager申请资源(executors及内存资源) - ResoureManager资源管理器选择合适的
worker节点创建executor进程 Executor向Driver注册,并等待其分配task任务- Driver端完成
SparkContext初始化,创建DAG,分配taskset到Executor上执行。 - Executor启动线程执行task任务,返回结果。
Spark On Yarn的基本流程:
- Spark
Driver端提交程序,并向Yarn申请Application - Yarn接受请求响应,在NodeManager节点上创建AppMaster
AppMaster向Yarn ResourceManager申请资源(Container)- 选择合适的节点创建
Container(Executor进程) - 后续的Driver启动调度,运行任务
Yarn Client、Yarn Cluster模式在某些环节会有差异,但是基本流程类似。
Spark作业基本运行原理
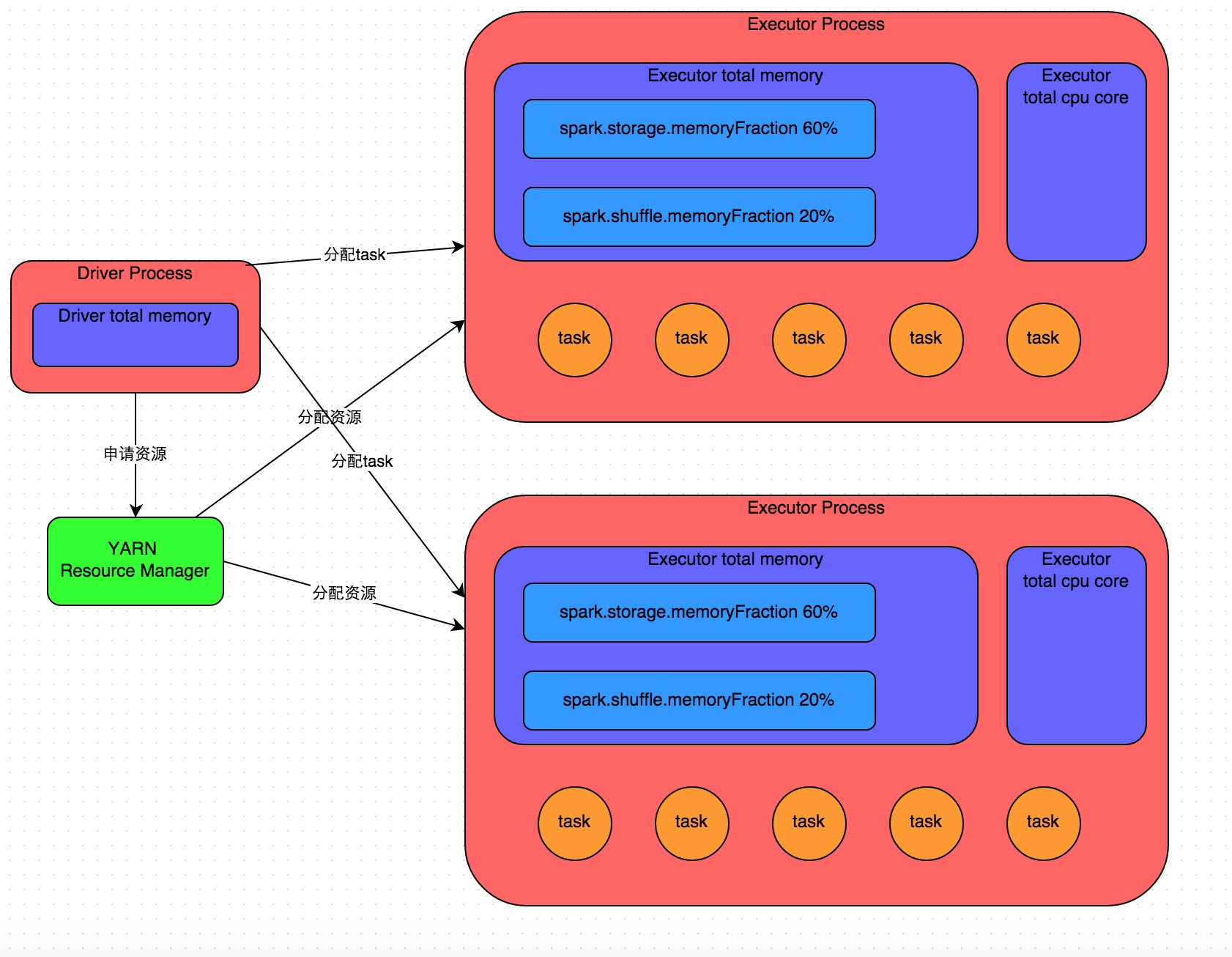
详细原理见上图。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
4 Spark常用算子列几个,6到8个吧
常用的RDD转换算子:
- filter(func) 筛选出满足函数func的元素,并返回一个新的数据集
- map(func) 将每个元素传递到函数func中,并将结果返回为一个新的数据集
- flatMap(func) 与map()相似,但每个输入元素都可以映射到0或多个输出结果
- groupByKey() 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
- reduceByKey(func) 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果
行动操作常用算子:
- count() 返回数据集中的元素个数
- collect() 以数组的形式返回数据集中的所有元素
- first() 返回数据集中的第一个元素
- take(n) 以数组的形式返回数据集中的前n个元素
- reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
- foreach(func) 将数据集中的每个元素传递到函数func中运行
5 transformation跟action算子的区别
所有的transformation都是采用的懒策略,就是如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。
- Transformation 变换/转换:这种变换并不触发提交作业,完成作业中间过程处理。Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
- Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。
Action 算子会触发 Spark 提交作业(Job)。
transformation操作:
- map(func):对调用map的RDD数据集中的每个element都使用func,然后返回一个新的RDD,这个返回的数据集是分布式的数据集
- filter(func): 对调用filter的RDD数据集中的每个元素都使用func,然后返回一个包含使func为true的元素构成的RDD
- flatMap(func):和map差不多,但是flatMap生成的是多个结果
- mapPartitions(func):和map很像,但是map是每个element,而mapPartitions是每个partition
- mapPartitionsWithSplit(func):和mapPartitions很像,但是func作用的是其中一个split上,所以func中应该有index
- sample(withReplacement,faction,seed):抽样
- union(otherDataset):返回一个新的dataset,包含源dataset和给定dataset的元素的集合
- distinct([numTasks]):返回一个新的dataset,这个dataset含有的是源dataset中的distinct的element
- groupByKey(numTasks):返回(K,Seq[V]),也就是hadoop中reduce函数接受的key-valuelist
- reduceByKey(func,[numTasks]):就是用一个给定的reducefunc再作用在groupByKey产生的(K,Seq[V]),比如求和,求平均数
- sortByKey([ascending],[numTasks]):按照key来进行排序,是升序还是降序,ascending是boolean类型
- join(otherDataset,[numTasks]):当有两个KV的dataset(K,V)和(K,W),返回的是(K,(V,W))的dataset,numTasks为并发的任务数
- cogroup(otherDataset,[numTasks]):当有两个KV的dataset(K,V)和(K,W),返回的是(K,Seq[V],Seq[W])的dataset,numTasks为并发的任务数
- cartesian(otherDataset):笛卡尔积就是m*n,大家懂的
action操作:
- reduce(func):说白了就是聚集,但是传入的函数是两个参数输入返回一个值,这个函数必须是满足交换律和结合律的
- collect():一般在filter或者足够小的结果的时候,再用collect封装返回一个数组
- count():返回的是dataset中的element的个数
- first():返回的是dataset中的第一个元素
- take(n):返回前n个elements,这个士driverprogram返回的
- takeSample(withReplacement,num,seed):抽样返回一个dataset中的num个元素,随机种子seed
- saveAsTextFile(path):把dataset写到一个textfile中,或者hdfs,或者hdfs支持的文件系统中,spark把每条记录都转换为一行记录,然后写到file中
- saveAsSequenceFile(path):只能用在key-value对上,然后生成SequenceFile写到本地或者hadoop文件系统
- countByKey():返回的是key对应的个数的一个map,作用于一个RDD
- foreach(func):对dataset中的每个元素都使用func
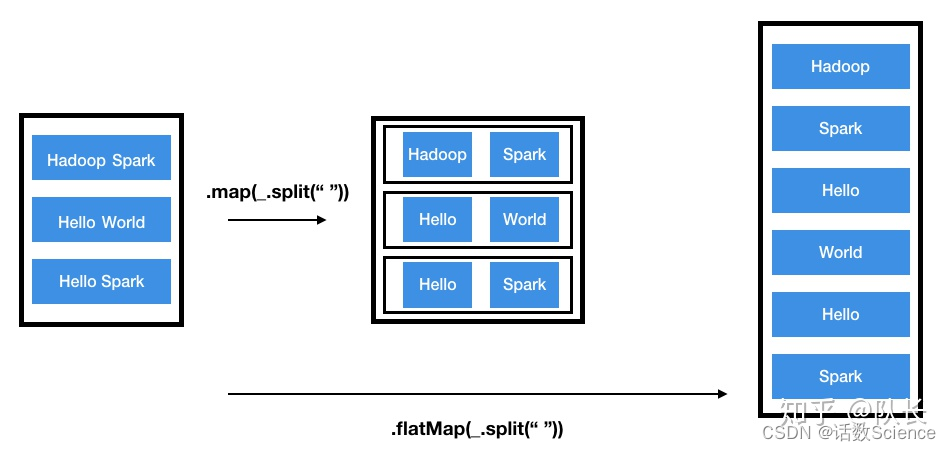
6 map和flatMap算子的区别
- map:执行完map后会得到一个新的分布式数据集,数据集中每个元素是之前的RDD映射得来的,与之前RDD每个元素存在一一对应的关系。
- flatmap:而flatmap有一点不同,每个输入的元素可以被映射为0个或者多个输出的元素,原RDD与新RDD的元素是一对多的关系。当然光看定义比较抽象,下面用一个图说明,
7 自定义udf,udtf,udaf讲一下这几个函数的区别,编写的时候要继承什么类,实现什么方法
区别:
- UDF:输入一行,输出一行
UDF:用户定义(普通)函数,只对单行数值产生作用; - UDTF:输入一行,输出多行,类似explode函数
UDTF:User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行; - UDAF:输入多行,输出一行,类似聚合函数
UDAF:User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数;
Hive实现:
| 类型 | 类 | 方法 |
| UDF | 类: GenericUDF
| initialize:类型检查,返回结果类型 evaluate:功能逻辑实现 入参:DeferredObject[] 出参:Object 出参:String close:关闭函数,释放资源等 出参:void |
| UDTF | 类: 包路径: | initialize:类型检查,返回结果类型 process:功能逻辑实现 入参:Object[] 出参:void 出参:void |
| UDAF | 类: 类:
AbstractAggregationBuffer | -----AbstractGenericUDAFResolver----- getEvaluator:获取计算器 ---------GenericUDAFEvaluator---------- init: getNewAggregationBuffer: 入参:无 出参:AggregationBuffer reset: 入参:AggregationBuffer 出参:void 入参:AggregationBuffer,Object[] 出参:void merge: 入参:AggregationBuffer,Object 出参:void
入参:AggregationBuffer 出参:Object 入参:AggregationBuffer 出参:Object --------AbstractAggregationBuffer------- 入参:无 出参:int |
UDAF说明
- 一个Buffer作为中间处理数据的缓冲:获取getNewAggregationBuffer、重置reset
- 四个阶段(Mode):
- PARTIAL1(Map阶段):
from original data to partial aggregation data:
iterate() and terminatePartial() will be called. - PARTIAL2(Map的Combiner阶段):
from partial aggregation data to partial aggregation data:
merge() and terminatePartial() will be called. - FINAL(Reduce 阶段):
from partial aggregation to full aggregation:
merge() and terminate() will be called. - COMPLETE(Map Only阶段):
from original data directly to full aggregation:
iterate() and terminate() will be called.
- PARTIAL1(Map阶段):
- 五个方法:
- 初始化init
- 遍历iterate:PARTIAL1和COMPLETE阶段
- 合并merge:PARTIAL2和FINAL阶段
- 终止terminatePartial:PARTIAL1和PARTIAL2阶段
- terminate:COMPLETE和FINAL阶段
Spark实现:
8 hive创建一个临时表有哪些方法
WITH创建临时表
如果这个临时表并不需要保存,并且下文只需要用有限的几次,我们可以采用下面的方法。
with as 也叫做子查询部分,首先定义一个sql片段,该sql片段会被整个sql语句所用到,为了让sql语句的可读性更高些,作为提供数据的部分,也常常用在union等集合操作中。
with as就类似于一个视图或临时表,可以用来存储一部分的sql语句作为别名,不同的是with as 属于一次性的,而且必须要和其他sql一起使用才可以!
其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL;更重要的是:一次分析,多次使用,这也是为什么会提供性能的地方,达到了“少读”的目标。
WITH t1 AS (
SELECT *
FROM a
),
t2 AS (
SELECT *
FROM b
)
SELECT *
FROM t1
JOIN t2
;注意:
- 这里必须要整体作为一条sql查询,即with as语句后不能加分号,不然会报错。
- with子句必须在引用的select语句之前定义,同级with关键字只能使用一次,多个只能用逗号分割
- 如果定义了with子句,但其后没有跟select查询,则会报错!
- 前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句!
Temporary创建临时表
create temporary table 临时表表名 as
select * from 表名- 创建的临时表仅仅在当前会话可见,数据会被暂存到hdfs上,退出当前会话表和数据将会被删除。数据将存储在用户的scratch目录中,并在会话结束时删除。
-
从Hive1.1开始临时表可以存储在内存或SSD,使用hive.exec.temporary.table.storage参数进行配置,该参数有三种取值:memory、ssd、default。
如果内存足够大,将中间数据一直存储在内存,可以大大提升计算性能。 - 如果临时表的命名的表名和hive的表名一样,当前会话则会查询临时表的数据,用户在这个会话内将不能使用原表,除非删除或者重命名临时表
- 临时表不支持分区字段,不支持创建索引。
9 讲一下三范式,三范式解决了什么问题,有什么优缺点
三范式:
- 第一范式:列的原子性,字段值不可再分,比如某个字段的取值是姓名+手机号,那就要把姓名和手机号分成两个字段
- 第二范式:第一范式的基础上,非主键列不能依赖主键的一部分,例如字段a和字段b组成的主键,某个字段只依赖a,就需要把这个字段剥离到a对应的表
- 第三范式:第二范式的基础上,非主键列不能传递依赖主键,例如字段c依赖字段b,字段b依赖主键字段a,那么就可以把这个字段c剥离到字段b为主键的表
三范式是要解决字段冗余,节省存储空间,数据维护更方便,不需要多处更新同样的字段;
缺点是不方便查询,要进行多表join效率低,不适合分析类的查询。
范式化设计的优点:可以减少数据冗余,数据表体积小更新快,范式化的更新操作比 反范式化更快,范式化的表通常比反范式化更小。
缺点:对于查询需要对多个表,会关联多个表,在应用中,进行表关联的成本是很高
更难进行索引优化
反范式化设计的优点:可以减少表的关联,可以对查询更好的进行索引优化,
缺点:表结构存在数据冗余和数据维护异常,对数据的修改需要更多资源。因此在设计数据库结构的时候要将反范式化和范式化结合起来
参考:你了解数据库三大范式吗?用来解决什么问题?_数据库三范式解决了什么问题_我是等闲之辈的博客-CSDN博客mysql--数据库优化的目的、数据库设计的步骤以及什么是三范式、三范式的优缺点-CSDN博客
10 讲一下维度建模的过程
四个步骤:①选择业务过程 ②确定粒度 ③确定维度 ④确定事实表
维度模型是数据仓库领域的 Ralph Kimball 大师所倡导的,他的The Data Warehouse Toolkit-The Complete Guide to Dimensional Modeling 是数据仓库工程领域最流行的数据仓库建模的经典。
维度建模从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下使用的雪花模型。其设计分为以下几个步骤。
第一步:选择业务过程
选择需要进行分析决策的业务过程。业务过程可以是单个业务事 件,比如交易的支付、退款等;也可以是某个事件的状态,比如 当前的账户余额等;还可以是一系列相关业务事件组成的业务流 程,具体需要看我们分析的是某些事件发生情况,还是当前状态, 或是事件流转效率。
第二步:确定粒度
选择粒度。在事件分析中,我们要预判所有分析需要细分的程度,从而决定选择的粒度。粒度是维度的一个组合。
第三步:确定维度
识别维表。选择好粒度之后,就需要基于此粒度设计维表,包括维度属性,用于分析时进行分组和筛选。
第四步:确定事实
选择事实。确定分析需要衡量的指标 。
11 维度表有哪几种
- 按是否规范化设计划分,分符合三范式的维表,和反规范化的维表,对应雪花模型和星型模型
- 按是否包含属性层次结构分,分包含层次结构的维表,和不包含层次结构的维表,如行业维表就是包含层次结构的维表,递归层次一般采用①扁平化、②层次桥接表两种方式设计
- 按水平拆分(基于业务类型)可以划分为,主维表(存放公共属性),子维度表(包含公共属性和特有属性)
- 按垂直拆分(基于性能)可以划分为:主维表(存放使用频率高的属性),扩展维表(存放使用频率低的属性)
- 按是否归档处理分为:历史维度表,普通表
- 按缓慢变化维划分:一种是使用代理键的就是Kimball中的8种类型的缓慢变化维度,如果不使用代理键则划分快照维表、采用极限存储的维度表
- 一些特殊维度类型:支架维度、杂项维度、行为维度(事实衍生维度,如买家常用地址)、多值维度
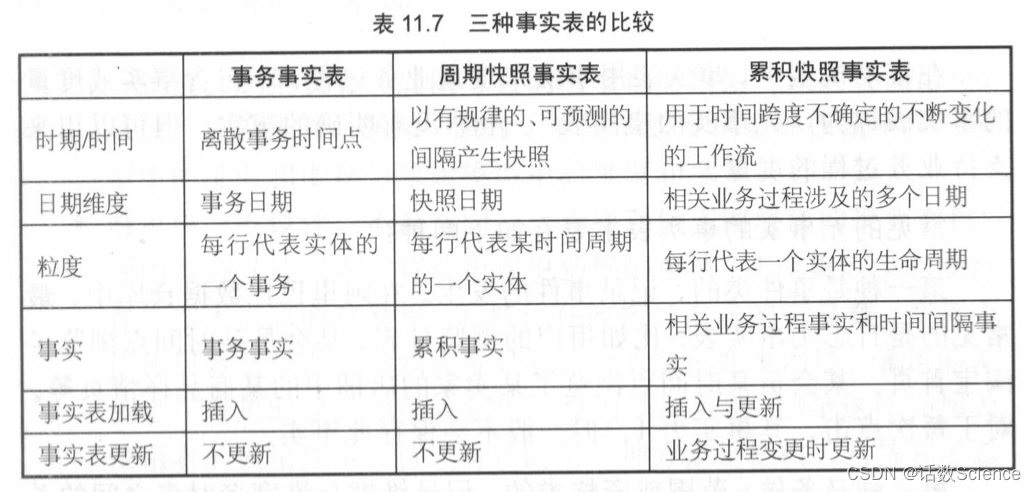
12 事实表有几种
- 事务性事实表:又分为单事务事实表,多事务事实表
- 周期快照事实表:又分为单维度的每天快照事实表,混合维度的每天快照事实表,全量快照事实表
- 累计快照事实表
13 什么是维度一致性,总线架构,事实一致性
维度建模的数据仓库中,有一个概念叫Conformed Dimension,中文一般翻译为“一致性维度”。一致性维度是Kimball的多维体系结构中的三个关键性概念之一,另两个是总线架构(Bus Architecture)和一致性事实(Conformed Fact)。
总线架构:初期进行需求沟通和整体设计的产物,汇总一致性维度和业务过程的表格
一致性维度:维度定义和维表实现的同一性
一致性事实:指标定义(包括单位)和实现的一致性
总线矩阵:业务过程和维度的交点;
一致性维度:同一集市的维度表,内容相同或包含;
一致性事实:不同集市的同一事实,需保证口径一致,单位统一。
14 什么是缓慢变化维,有哪几种?
缓慢变化维,SCD(Slowly Changing Dimensions),数仓的特点之一就是反映历史变化,与增长较快的事实表相比,维度变化相对缓慢。Kimball整理的处理方法一共有8种,但往往只有3种比较常用(类型1、类型2、类型3)。
- 类型0:属性值不可能变,保留原样。
- 类型1:重写,覆盖原值,类型1不能反映历史。
- 类型2:新增一行,并生成新的代理键,事实表旧的记录使用旧的代理键,新的记录使用新的代理键,同时维表增加创建时间和截止时间来标识最新有效的记录和历史记录,新的记录有效期可以设置一个极大值,如9999.12.31,类型2的缺点是旧的记录只能用旧的维度分析,新的记录只能用新的维度进行分析。
- 类型3:类型1只能满足新维度分析的需求,类型2既不能满足新维度分析的需求,也不能满足旧维度分析的需求,如果要同时满足新旧两种维度分析的需求,可以考虑使用类型3。类型3是通过两个字段分别存储新旧值来满足这种两种同时都要的需求的,但是类型3的问题在,如果只变化一次还行,但如果变化第2次、第3次,就需要增加新的字段,会比较麻烦。
- 类型4:微型维度。解决的是高频变更导致的记录过多的问题,剥离高频变化的维度,如果是数值可以用范围值来减少数量,有多个高频变化的维度,就用这些维度的笛卡尔积来组合成维表,可以用组合缩写来生成代理键(注意微型维度没有自然键)。另外如果需要记录精确值,可以考虑无事实的事实表。需要注意的是,类型4只能在事实表中出现,如果维度表和微型维度发生的关联,那就是类型5。
- 类型5:类型1+微型维度。主维表通过类型1关联微信维度,反映最新值,微型维度与事实表进行关联,通过事实表来反映历史变化。
- 类型6:类型1+类型2+类型3。通过类型3构建新旧两列,同一个自然键的通过类型1更新为最新值,通过类型2处理历史变化。类型6的缺点是如果这种列很多,150个列,那就要翻倍来存300个列,这是可以考虑类型7。
- 类型7:双类型1+类型2。用类型2生成主维表,同时生成一个最新值的视图(取9999.12.31),事实表中存放两个外键或者单个外键连关联这两张维表。代理键可以反映当时的变化,自然键(超自然键)可以反映当前最新值。双重外键一个键存放主维表的代理键反映当时的情况,一个键存放最新视图的自然键(最好是超自然键)反映最新情况。单外键存的是主维表的代理键,视图里存当时的代理键和最新的代理键。
15 什么是拉链表,如何实现?
拉链表
- 主要是为了记录历史变化,并节省存储空间。适合大数据量场景下,变化频率又不高的情况。如果每天存储全量表,很多都是重复的记录,造成浪费。
- 可以应用在维表也可以应用在事实表。比如某个员工维表为了反映部门历史变动,订单事实表为了反映订单状态的历史变化(未支付、已支付、已发货、已完成)。
实现过程
有些业务系统的表,不保存变更流水记录的,只保存最新的值,比如订单表,只保留订单的最新状态。如果要反映历史变化,需要跟进binlog日志或者定时采集来记录变化。具体实现步骤:
- 第一步:创建并初始化拉链表(执行一次)
- 第二步:合并当日新增和修改的数据到临时表(每天执行一次)
每日变更的记录uion all拉链表的记录,注意要修改历史记录的有效日期。 - 第三步:把临时表覆盖写入拉链表(每天执行一次)
进阶问题
拉链表如何回滚?参考:https://www.cnblogs.com/lxbmaomao/p/9821128.html
极限存储怎么实现?参考:拉链表-极限存储-CSDN博客
参考:
16 什么是微型维度、支架表,什么时候会用到
- 微型维度:缓慢变化维度类型4,参考第14题
- 支架表:
- 是一种受限的雪花维度,是星型模型和雪花模型之间的一种折中,如日期维度表、地址维度表
- 使用场景:当一个属性集合(例如日期、地点)在某个维度或多个维度表中反复出现时,就可以考虑使用支架表。
- 使用条件:
①在单个维度表中反复出现该支架属性时
②被调用的属性值较多时
③被多个维度、事实表调用,且被调用时的属性值定义完全相同
④基本不需要修改或修改频次极小
参考:
17 讲几个你工作中常用的spark 或者hive 的参数,以及这些参数做什么用的
hive参数
----------------------小文件合并----------------------
----------map输入端合并-----------
## Map端输入、合并文件之后按照block的大小分割(默认)
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
## Map端输入,不合并
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
------------输出端合并------------
## 是否合并Map输出文件, 默认值为true
set hive.merge.mapfiles=true;
## 是否合并Reduce端输出文件,默认值为false
set hive.merge.mapredfiles=true;
## 合并文件的大小,默认值为256000000 256M
set hive.merge.size.per.task=256000000;
## 每个Map 最大分割大小
set mapred.max.split.size=256000000;
## 一个节点上split的最少值
set mapred.min.split.size.per.node=1; // 服务器节点
## 一个机架上split的最少值
set mapred.min.split.size.per.rack=1; // 服务器机架
hive.merge.size.per.task 和 mapred.min.split.size.per.node 联合起来:
##1、默认情况先把这个节点上的所有数据进行合并,如果合并的那个文件的大小超过了256M就开启另外一个文件继续合并
##2、如果当前这个节点上的数据不足256M,那么就都合并成一个逻辑切片。
----------------------Map Task并行度----------------------
## 切片大小计算公式: long splitSize = Math.max(minSize, Math.min(maxSize, blockSize))
## dfs.blocksize:128MB split.minsize:1 split.maxsize:256MB
set mapreduce.input.fileinputformat.split.minsize=1
set mapreduce.input.fileinputformat.split.maxsize=256000000
## 输入文件总大小:total_size
## HDFS 设置的数据块大小:dfs_block_size
## default_mapper_num = total_size / dfs_block_size
## mapred.map.tasks这个参数设置只有在大于 default_mapper_num 的时候,才会生效
set mapred.map.tasks=10; ## 默认值是2
## map task计算公式:
## split_size = max(mapred.min.split.size, dfs_block_size)
## split_num = total_size / split_size
## compute_map_num = Math.min(split_num, Math.max(default_mapper_num,
## mapred.map.tasks))
## 总结:
## 1、如果想增加 MapTask 个数,可以设置 mapred.map.tasks 为一个较大的值
## 2、如果想减少 MapTask 个数,可以设置 maperd.min.split.size 为一个较大的值
## 3、如果输入是大量小文件,想减少 mapper 个数,可以通过设置 hive.input.format 合并小文
----------------------Reduce Task并行度----------------------
## 参数1:hive.exec.reducers.bytes.per.reducer (默认256M)
## 参数2:hive.exec.reducers.max (默认为1009)
## 参数3:mapreduce.job.reduces (默认值为-1,表示没有设置,那么就按照以上两个参数进行设置)
## ReduceTask 的计算公式为:
## N = Math.min(参数2,总输入数据大小 / 参数1)
----------------------Join 优化----------------------
----------开启map join-----------
## 是否根据输入小表的大小,自动将reduce端的common join 转化为map join,将小表刷入内存中。
## 对应逻辑优化器是MapJoinProcessor
set hive.auto.convert.join = true;
## 刷入内存表的大小(字节)
set hive.mapjoin.smalltable.filesize = 25000000;
## hive会基于表的size自动的将普通join转换成mapjoin
set hive.auto.convert.join.noconditionaltask=true;
## 多大的表可以自动触发放到内层LocalTask中,默认大小10M
set hive.auto.convert.join.noconditionaltask.size=10000000;
----------开启bucket map join & SMB map join-----------
## 当用户执行bucket map join的时候,发现不能执行时,禁止查询
set hive.enforce.sortmergebucketmapjoin=false;
## 如果join的表通过sort merge join的条件,join是否会自动转换为sort merge join
set hive.auto.convert.sortmerge.join=true;
## 当两个分桶表 join 时,如果 join on的是分桶字段,小表的分桶数是大表的倍数时,可以启用
mapjoin 来提高效率。
# bucket map join优化,默认值是 false
set hive.optimize.bucketmapjoin=false;
## bucket map join 优化,默认值是 false
set hive.optimize.bucketmapjoin.sortedmerge=false;
------------------数据倾斜优化-------------------
---------Map端聚合----------
## 开启Map端聚合参数设置
set hive.map.aggr=true;
# 设置map端预聚合的行数阈值,超过该值就会分拆job,默认值100000
set hive.groupby.mapaggr.checkinterval=100000
# 自动优化,有数据倾斜的时候进行负载均衡(默认是false) 如果开启设置为true
set hive.groupby.skewindata=false;
## 1、在第一个 MapReduce 任务中,map 的输出结果会随机分布到 reduce 中,每个 reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的`group by key`有可能分发到不同的 reduce 中,从而达到负载均衡的目的;
## 2、第二个 MapReduce 任务再根据预处理的数据结果按照 group by key 分布到各个 reduce 中,最后完成最终的聚合操作。
---------join优化----------
# join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=100000;
# 如果是join过程出现倾斜应该设置为true
set hive.optimize.skewjoin=false;
------------------使用 vectorization 矢量查询技术-------------------
set hive.vectorized.execution.enabled=true ;
set hive.vectorized.execution.reduce.enabled=true;
---------------本地执行优化------------------
## 打开hive自动判断是否启动本地模式的开关
set hive.exec.mode.local.auto=true;
## map任务数最大值,不启用本地模式的task最大个数
set hive.exec.mode.local.auto.input.files.max=4;
## map输入文件最大大小,不启动本地模式的最大输入文件大小
set hive.exec.mode.local.auto.inputbytes.max=134217728;
---------------并行执行---------------
## 可以开启并行执行。
set hive.exec.parallel=true;
## 同一个sql允许最大并行度,默认为8。
set hive.exec.parallel.thread.number=16;
---------------严格模式---------------
## 设置Hive的严格模式
set hive.mapred.mode=strict;
set hive.exec.dynamic.partition.mode=nostrict;
Spark参数
Spark提交任务参数设置
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-
executors 3 --executor-cores 2 --executor-memory 4g --class
com.abc.sparktuning.utils.InitUtil spark-tuning-1.0-SNAPSHOT-jar-
with-dependencies.jar指定集群模式和部署模式:
spark-submit中通过--master参数指定集群的资源管理器(也可以在代码中硬编码指定master),通过--deploy-mode参数指定以client模式运行还是以cluster模式运行。
master常用参数有local(Driver和Executor运行在同一个节点的同一个JVM中)、Spark Standalone集群(Spark自带的简易资源管理器,分Master节点和Worker节点)、mesos、yarn、k8s。
部署模式,client和cluster两种,client模式是Driver进程在提交任务的节点运行,cluster模式是Driver进程在Woker节点中运行Driver进程。
资源参数设置举例:
Executor内存设置:以单台服务器 128G 内存,32 核为例,考虑到系统基础服务和 HDFS 等组件的余量,yarn.nodemanager.resource.cpu-vcores 配置为:28核,每个 executor 的最大核数。根据经验实践,设定在 3~6 之间比较合理。这里设置为4,那么每个Yarn节点,可以同时跑28 / 4 = 7个executor。假设集群节点为 10,那么 num-executors = 7 * 10 = 70,所以num-executors是70,executor-cores是4
如果 yarn-nodemanager.resource.memory-mb=100G,那么每个 Executor 大概就是 100G/7≈14G,同时加上堆外内存要不大于 yarn.scheduler.maxinum-allocation-mb 容器最大内存设置,因为executor-memory指定的是堆内内存,除了堆内内存,还有堆外内存。
Driver内存设置:Yarn Client 和 Cluster 两种方式提交,Executor和Driver的内存分配情况也是不同的。Yarn中的ApplicationMaster都启用一个Container来运行;
Client模式下的Container默认有1G内存,1个cpu核,Cluster模式的配置则由driver-memory和driver-cpu来指定,也就是说Client模式下的driver是默认的内存值;Cluster模式下的dirver则是自定义的配置。
设置Kryo序列化降低RDD缓存磁盘占用
new SparkConf()
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
...
result.persist(StorageLevel.MEMORY_ONLY_SER)并行度参数设置
SparkConf conf = new SparkConf()
conf.set("spark.default.parallelism", "500")注意:
spark.default.parallelism只有在处理RDD时才会起作用,对Spark SQL的无效。
spark.sql.shuffle.partitions则是对Spark SQL专用的设置
我们也可以在提交作业的通过 --conf 来修改这两个设置的值,方法如下:
spark-submit --conf spark.sql.shuffle.partitions=500 --conf spark.default.parallelism=500
spark.default.parallelism:用户配置同一的并行度(统一性)
reduceByKey(1000)类shuffle算子:具体任务中可以特定配置的并行度。(特定性)
两者优先级:算子类传入的并行度 > 同一设置的并行度。
spark.sql.shuffle.partitions对sparksql中的joins和aggregations有效,但其他的无效,针对这种情况可以采用repartition算子对dataframe进行重分区
如果想要让任务运行的最快当然是一个 task 对应一个 vcore,但 是一般不会这样设置,为了合理利用资源,一般会将并行度(task 数)设置成并发度 (vcore数)的2倍到3倍。
设置2~3倍的具体原因参考如下:
因为实际情况,与理想情况不同的,有些task会运行的快一点,比如50s就完了,有些task,可能会慢一点,要1分半才运行完,所以如果你的task数量,刚好设置的跟cpu core数量相同,可能还是会导致资源的浪费,因为,比如150个task,10个先运行完了,剩余140个还在运行,但是这个时候,有10个cpu core就空闲出来了,就导致了浪费。那如果task数量设置成cpu core总数的2~3倍,那么一个task运行完了以后,另一个task马上可以补上来,就尽量让cpu core不要空闲,同时也是尽量提升spark作业运行的效率和速度,提升性能。
CBO优化
通过 "spark.sql.cbo.enabled" 来开启,默认是 false。配置开启 CBO 后,CBO 优化器可以基于表和列的统计信息,进行一系列的估算,最终选择出最优的查询计划。比如:Build侧选择、优化Join 类型、优化多表Join顺序等。
| 参数 | 描述 | 默认值 |
| spark.sql.cbo.enabled | CBO 总开关。 要使用该功能,需确保相关表和列的统计信息已经生成。 | false |
| spark.sql.cbo.joinReorder.enabled | 使用CBO来自动调整连续的inner join的顺序。 需确保相关表和列的统计信息已经生成,且CBO总开关打开。 | false |
| spark.sql.cbo.joinReorder.dp.threshold | 使用 CBO 来自动调整连续 inner join 的表的个数阈值。 12 如果超出该阈值,则不会调整 join 顺序。 | 12 |
广播JOIN
广播 join 默认值为 10MB,由 spark.sql.autoBroadcastJoinThreshold 参数控制。
new SparkConf()
.set("spark.sql.autoBroadcastJoinThreshold","10m") // 默认10m
new SparkConf()
.set("spark.sql.autoBroadcastJoinThreshold","-1") // 关闭自动广播读取小文件优化
spark.sql.files.maxPartitionBytes=128MB 默认128m
spark.files.openCostInBytes=4194304 默认4m读取的数据源有很多小文件,会造成查询性能的损耗,大量的数据分片信息以及对应产生的 Task 元信息也会给 Spark Driver 的内存造成压力,带来单点问题。
- 参数(单位都是 bytes)
- maxPartitionBytes:一个分区最大字节数。
- openCostInBytes:打开一个文件的开销。
- 源码:DataSourceScanExec.createNonBucketedReadRDD()
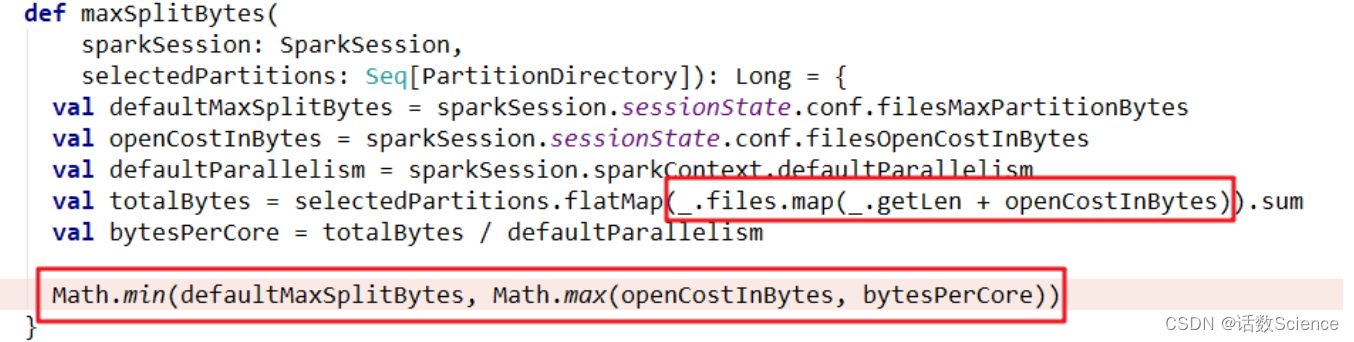
-
FilePartition. getFilePartitions():
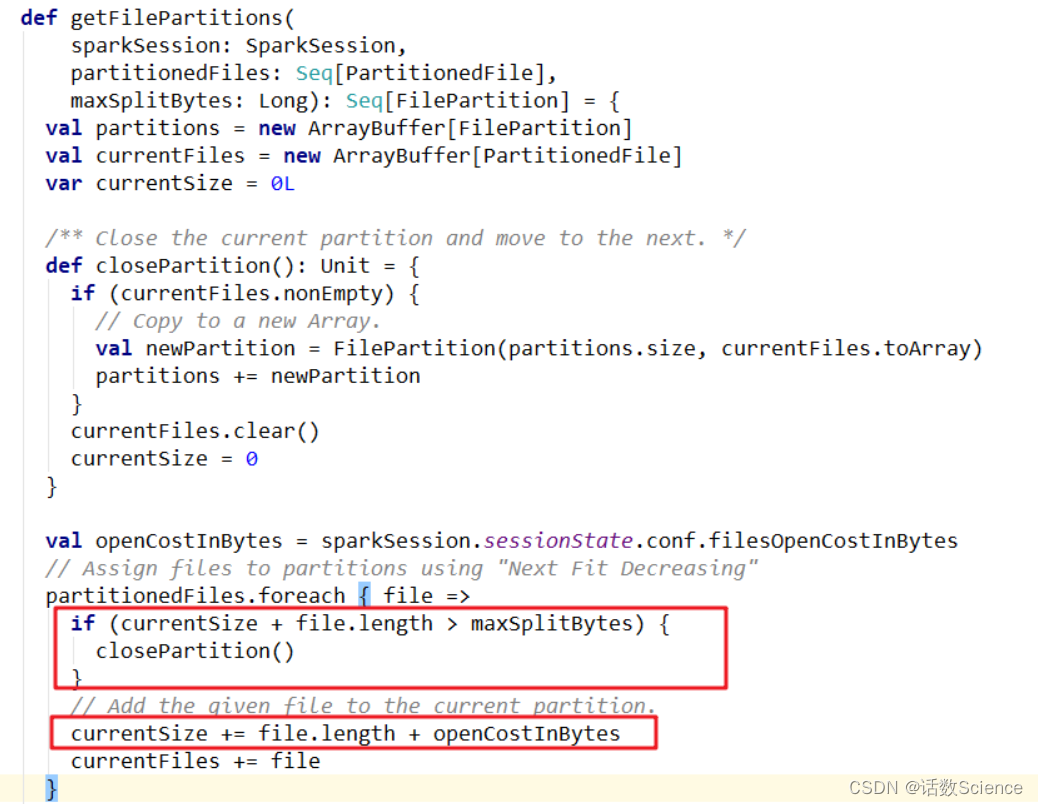
- 切片大小= Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore)) 计算 totalBytes 的时候,每个文件都要加上一个 open 开销,defaultParallelism 就是 RDD 的并行度
- 当(文件1大小+ openCostInBytes)+(文件2大小+ openCostInBytes)+...+(文件n-1大小+ openCostInBytes)+文件n <= maxPartitionBytes时,n个文件可以读入同一个分区,即满足: N个小文件总大小+(N-1)*openCostInBytes<= maxPartitionBytes 的话。
Map端溢写时输出流buffer设置
溢写时使用输出流缓冲区默认 32k,这些缓冲区减少了磁盘搜索和系统调用次数, 适当提高可以提升溢写效率。
new SparkConf().
.set("spark.shuffle.file.buffer", "64")增大 reduce 缓冲区,减少拉取次数
Spark Shuffle过程中,shuffle reduce task的buffer缓冲区大小决定了reduce task每次能够缓冲的数据量,也就是每次能够拉取的数据量,如果内存资源较为充足,适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提 升性能。
reduce 端数据拉取缓冲区的大小可以通过spark.reducer.maxSizeInFlight参数进行设置, 默认为 48MB。
调节 reduce 端拉取数据重试次数
Spark Shuffle 过程中,reduce task 拉取属于自己的数据时,如果因为网络异常等原因导 致失败会自动进行重试。对于那些包含了特别耗时的 shuffle 操作的作业,建议增加重试最 大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失 败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的 shuffle 过程,调节该参数可以大幅度提升稳定性。
Reduce 端拉取数据重试次数可以通过spark.shuffle.io.maxRetries参数进行设置,该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败,默认为 3。
调节 reduce 端拉取数据等待间隔
Spark Shuffle 过程中,reduce task 拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试,在一次失败后,会等待一定的时间间隔再进行重试,可以通过加大间隔时长(比如 60s),以增加 shuffle 操作的稳定性。
reduce 端拉取数据等待间隔可以通过spark.shuffle.io.retryWait参数进行设置,默认值 为 5s。
bypass阈值设置
spark.shuffle.sort.bypassMergeThreshold 默认200
当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200)且不需要map端进行合并操作,则shuffle write过程中不会进行排序操作,使用 BypassMergeSortShuffleWriter 去写数据,但是最后会将每个 task 产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
当你使用 SortShuffleManager 时,如果确实不需要排序操作,那么建议将这个参数调大一些,大于 shuffle read task 的数量。那么此时就会自动启用 bypass 机制,map-side 就不 会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件, 因此 shuffle write 性能有待提高。
调节数据本地化等待时长
下面几个参数,默认都是 3s,可以改成如下:
- spark.locality.wait //建议 6s、10s
- spark.locality.wait.process //建议 60s
- spark.locality.wait.node //建议 30s
- spark.locality.wait.rack //建议 20s
在 Spark 项目开发阶段,可以使用 client 模式对程序进行测试,此时,可以在本地看到比较全的日志信息,日志信息中有明确的 Task 数据本地化的级别,如果大部分都是PROCESS_LOCAL、NODE_LOCAL,那么就无需进行调节,但是如果发现很多的级别都是 RACK_LOCAL、ANY,那么需要对本地化的等待时长进行调节,应该是反复调节,每次调节 完以后,再来运行观察日志,看看大部分的 task 的本地化级别有没有提升;看看,整个 spark 作业的运行时间有没有缩短。
注意过犹不及,不要将本地化等待时长延长地过长,导致因为大量的等待时长,使得 Spark 作业的运行时间反而增加了。
堆外内存参数
讲到堆外内存,就必须去提一个东西,那就是去 yarn 申请资源的单位,容器。Spark on yarn 模式,一个容器到底申请多少内存资源。
一个容器最多可以申请多大资源,是由 yarn 参数 yarn.scheduler.maximum-allocation- mb 决定, 需要满足:
spark.executor.memoryOverhead + spark.executor.memory + spark.memory.offHeap.size ≤ yarn.scheduler.maximum-allocation-mb
参数解释:
- spark.executor.memory:提交任务时指定的堆内内存。
- spark.executor.memoryOverhead:堆外内存参数,内存额外开销。 默认开启,默认值为 spark.executor.memory*0.1 并且会与最小值 384mb 做对比, 取最大值。所以spark on yarn任务堆内内存申请1个g,而实际去yarn申请的内 存大于1个g的原因。
- spark.memory.offHeap.size:堆外内存参数,spark 中默认关闭,需要将 spark.memory.enable.offheap.enable 参数设置为 true。
注意:很多网上资料说 spark.executor.memoryOverhead 包含 spark.memory.offHeap.size,这是由版本区别的,仅限于 spark3.0 之前的版本。3.0 之后就发生改变,实际去 yarn 申请的内存资源由上面三个参数相加。
使用堆外内存可以减轻垃圾回收的工作,也加快了复制的速度。
当需要缓存非常大的数据量时,虚拟机将承受非常大的 GC 压力,因为虚拟机必须检查每个对象是否可以收集并必须访问所有内存页。本地缓存是最快的,但会给虚拟机带来 GC 压力,所以,当你需要处理非常多 GB 的数据量时可以考虑使用堆外内存来进行优化, 因为这不会给 Java 垃圾收集器带来任何压力。让 JAVA GC 为应用程序完成工作,缓存操作 交给堆外。
调节连接等待时长
--conf spark.core.connection.ack.wait.timeout=300s
在 Spark 作业运行过程中,Executor 优先从自己本地关联的 BlockManager 中获取某份 数据,如果本地 BlockManager 没有的话,会通过 TransferService 远程连接其他节点上 Executor 的 BlockManager 来获取数据。
如果 task 在运行过程中创建大量对象或者创建的对象较大,会占用大量的内存,这回 导致频繁的垃圾回收,但是垃圾回收会导致工作现场全部停止,也就是说,垃圾回收一旦 执行,Spark 的 Executor 进程就会停止工作,无法提供相应,此时,由于没有响应,无法 建立网络连接,会导致网络连接超时。
在生产环境下,有时会遇到file not found、file lost这类错误,在这种情况下,很有可 能是 Executor 的 BlockManager 在拉取数据的时候,无法建立连接,然后超过默认的连接等 待时长 120s 后,宣告数据拉取失败,如果反复尝试都拉取不到数据,可能会导致 Spark 作 业的崩溃。这种情况也可能会导致 DAGScheduler 反复提交几次 stage,TaskScheduler 反复 提交几次 task,大大延长了我们的 Spark 作业的运行时间。
为了避免长时间暂停(如 GC)导致的超时,可以考虑调节连接的超时时长,连接等待时 长需要在 spark-submit 脚本中进行设置,设置方式可以在提交时指定。
Spark3.0 AQE
Spark 在 3.0 版本推出了 AQE(Adaptive Query Execution),即自适应查询执行。AQE 是Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计 划,来完成对原始查询语句的运行时优化。
动态合并分区
new SparkConf().setAppName("AQEPartitionTunning")
.set("spark.sql.autoBroadcastJoinThreshold", "-1") //为了演示效果,禁用广播join
.set("spark.sql.adaptive.enabled", "true")
.set("spark.sql.adaptive.coalescePartitions.enabled", "true") // 合并分区的开关
.set("spark.sql.adaptive.coalescePartitions.initialPartitionNum","1000") // 初始的并行度
.set("spark.sql.adaptive.coalescePartitions.minPartitionNum","10") // 合并后的最小分区数
.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "20mb") // 合并后的分区,期望有多大动态申请资源
new SparkConf().setAppName("DynamicAllocationTunning")
.set("spark.sql.autoBroadcastJoinThreshold", "-1")
.set("spark.sql.adaptive.enabled", "true")
.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
.set("spark.sql.adaptive.coalescePartitions.initialPartitionNum","1000")
.set("spark.sql.adaptive.coalescePartitions.minPartitionNum","10")
.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "20mb")
.set("spark.dynamicAllocation.enabled","true") // 动态申请资源
.set("spark.dynamicAllocation.shuffleTracking.enabled","true") // shuffle动态跟踪动态切换 Join 策略
new SparkConf().setAppName("AqeDynamicSwitchJoin")
.set("spark.sql.adaptive.enabled", "true")
.set("spark.sql.adaptive.localShuffleReader.enabled", "true") //在不需要进行shuffle重分区时,尝试使用本地shuffle读取器。将sort-meger join 转换为广播join动态优化 Join 倾斜
new SparkConf().setAppName("AqeOptimizingSkewJoin")
.set("spark.sql.autoBroadcastJoinThreshold", "-1") //为了演示效果,禁用广播join
.set("spark.sql.adaptive.coalescePartitions.enabled", "true") // 为了演示效果,关闭自动缩小分区
.set("spark.sql.adaptive.enabled", "true")
.set("spark.sql.adaptive.skewJoin.enable","true")
.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor","2")
.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes","20mb")
.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "8mb")Spark3.0 DPP
Spark3.0 支持动态分区裁剪 Dynamic Partition Pruning,简称 DPP,核心思路就是先将 join 一侧作为子查询计算出来,再将其所有分区用到 join 另一侧作为表过滤条件,从而实现对分区的动态修剪。
参数 spark.sql.optimizer.dynamicPartitionPruning.enabled 默认开启。
new SparkConf().setAppName("DPPTest")
.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true")Spark3.0 Hint 增强
在spark2.4的时候就有了hint功能,不过只有broadcasthash join的hint,这次3.0又增 加了 sort merge join,shuffle_hash join,shuffle_replicate nested loop join。
broadcasthast join
sparkSession.sql("select /*+ BROADCAST(school) */ * from test_student
student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ BROADCASTJOIN(school) */ * from
test_student student left join test_school school on
student.id=school.id").show()
sparkSession.sql("select /*+ MAPJOIN(school) */ * from test_student
student left join test_school school on student.id=school.id").show()sort merge join
sparkSession.sql("select /*+ SHUFFLE_MERGE(school) */ * from
test_student student left join test_school school on
student.id=school.id").show()
sparkSession.sql("select /*+ MERGEJOIN(school) */ * from test_student
student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ MERGE(school) */ * from test_student
student left join test_school school on student.id=school.id").show()shuffle_hash join
sparkSession.sql("select /*+ SHUFFLE_HASH(school) */ * from test_student
student left join test_school school on student.id=school.id").show()shuffle_replicate_nl join
sparkSession.sql("select /*+ SHUFFLE_REPLICATE_NL(school) */ * from test_student student inner join test_school school on
student.id=school.id").show()
18 工作中遇到数据倾斜处理过吗?是怎么处理的,针对你刚刚提的方案讲一下具体怎么实现。用代码实现,以及用sql实现。
- 过滤无效的导致倾斜的key【适用场景不多】:比如过滤null、空字符串、非整数字符串等
方案一:剥离null不参与shuffle;方案二:对null加随机数打散shuffle - reduce join转为map join【适合小表join大表】:spark可以通过broadcast来广播小表
- 增加shuffle并行度【缓解】:shuffle算子入reduceByKey(1000)传入并行度数值,或者SparkSQL设置spark.sql.shuffle.partitions参数(默认200),都能提高shuffle read task的并行度
- 两阶段聚合(局部聚合+整体聚合)【适用于聚合类倾斜】
第一步,给每个key都打上一个随机前缀。
第二步,对打上随机前缀的key进行局部聚合。
第三步,去除每个key的随机前缀。
第四步,全局聚合。 - 采样倾斜key并分开join【适合大表join大表,一个大表有少数几个key倾斜,另一个比较均匀】:
通过sample采样出倾斜的key,然后包这些key从两张表里剥离出来,一张加随机数打散成n份,一张扩充n倍进行Join,剥离出key剩下的数据进行普通join即可,最后把结果合并在一起 - 全部数据加随机数打散N份+扩容N倍【大表Join大表,扩容导致内存消耗大】:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
加随机数group by
with tmp1 as (
select 1 as id, 'a' as label, 1 as value
union all
select 1 as id, 'a' as label, 2 as value
union all
select 1 as id, 'a' as label, 3 as value
union all
select 2 as id, 'b' as label, 4 as value
)
select label, sum(cnt) as all from
(
select rd, label, sum(1) as cnt from
(
select id, round(rand(),2) as rd, label, value from tmp1
) as tmp
group by rd, label
) as tmp
group by label;
--udf版本
select
courseid,
sum(course_sell) totalSell
from
(
select
remove_random_prefix(random_courseid) courseid,
course_sell
from
(
select
random_courseid,
sum(sellmoney) course_sell
from
(
select
random_prefix(courseid, 6) random_courseid,
sellmoney
from
sparktuning.course_shopping_cart
) t1
group by random_courseid
) t2
) t3
group by
courseid;
--如果想要取的0-9或者1-10之间的随机数,x10后向下向上取整即可
select cast(floor(rand() * 10) as int)
select cast(ceiling(rand() * 10) as int)加随机数join
with t1 as (
select 1 as id, 'a' as label, 1 as value
union all
select 1 as id, 'a' as label, 2 as value
union all
select 1 as id, 'a' as label, 3 as value
union all
select 2 as id, 'b' as label, 4 as value
), t2 as (
select 1 as id, 'a' as label, 10 as value
union all
select 1 as id, 'a' as label, 20 as value
union all
select 1 as id, 'a' as label, 30 as value
union all
select 2 as id, 'b' as label, 40 as value
), tmp1 as (
select id,round(rand(),1) as rd,label,value from t1
), tmp2 as (
select id, rd, label, value from t2
lateral view
explode(split('0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0',',')) mytable as rd
), tmp3 as (
select tmp1.rd as rd, tmp1.label as label, tmp1.value*tmp2.value as value
from
tmp1
join
tmp2
on tmp1.rd = tmp2.rd and tmp1.label = tmp2.label
), tmp4 as (
select rd, label, sum(value) as value from
tmp3
group by rd,label
)
select label,sum(value) as all from
tmp4
group by label;null处理
方案一:不参与shuffle
SELECT *
FROM log a
LEFT JOIN users b
ON a.user_id IS NOT NULL
AND a.user_id = b.user_id
UNION ALL
SELECT *
FROM log a
WHERE a.user_id IS NULL;方案二:加随机数shfffle
SELECT *
FROM log a
LEFT JOIN users b
ON if(a.user_id is null,concat('hive',rand()),a.user_id)= b.user_id;参考:
19 讲一下kafka对接flume 有几种方式
三种:source、channel、sink
source和sink对接方式:Flume对接Kafka详细过程_flume kafka_杨哥学编程的博客-CSDN博客
channel对接方式:flume--KafkaChannel的使用_kafka channel为什么没有sink-CSDN博客
20 讲一下spark是如何将一个sql翻译成代码执行的,里面的原理介绍一下?
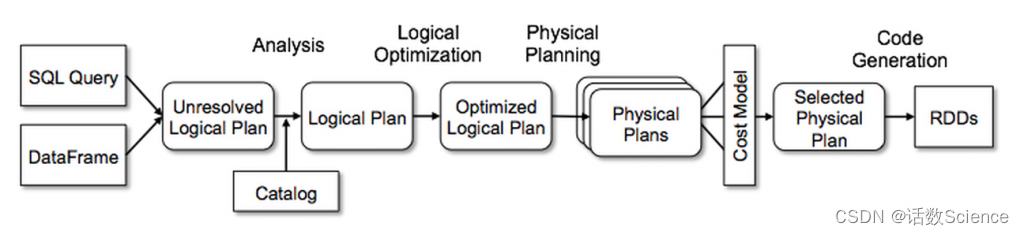
SparkSQL主要是通过Catalyst优化器,将SQL翻译成最终的RDD算子的
| 阶段 | 产物 | 执行主体 |
| 解析 | Unresolved Logical Plan(未解析的逻辑计划) | sqlParser |
| 分析 | Resolved Logical Plan(解析的逻辑计划) | Analyzer |
| 优化 | Optimized Logical Plan(优化后的逻辑计划) | Optimizer |
| 转换 | Physical Plan(物理计划) | Query Planner |
无论是使用 SQL语句还是直接使用 DataFrame 或者 DataSet 算子,都会经过Catalyst一系列的分析和优化,最终转换成高效的RDD的操作,主要流程如下:
1. sqlParser 解析 SQL,生成 Unresolved Logical Plan(未解析的逻辑计划)
2. 由 Analyzer 结合 Catalog 信息生成 Resolved Logical Plan(解析的逻辑计划)
3. Optimizer根据预先定义好的规则(RBO),对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan(优化后的逻辑计划)
4. Query Planner 将 Optimized Logical Plan 转换成多个 Physical Plan(物理计划)。然后由CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan(最终执行的物理计划)
5. Spark运行物理计划,先是对物理计划再进行进一步的优化,最终映射到RDD的操作上,和Spark Core一样,以DAG图的方式执行SQL语句。 在最新的Spark3.0版本中,还增加了Adaptive Query Execution功能,会根据运行时信息动态调整执行计划从而得到更高的执行效率
整体的流程图如下所示:
21 spark 程序里面的count distinct 具体是如何执行的
-
一般对count distinct优化就是先group by然后再count,变成两个mapreduce过程,先去重再count。
-
spark类似,会发生两次shuffle,产生3个stage,经过4个步骤:①先map端去重,②然后再shuffle到reduce端去重,③然后通过map做一次partial_count,④最后shuffle到一个reduce加总。
-
spark中多维count distinct,会发生数据膨胀问题,会把所有需要 count distinct 的N个key组合成List,行数就翻了N倍,这时最好分开来降低单个任务的数据量。
22 不想用spark的默认分区,怎么办?(自定义Partitioner 实现里面要求的方法 )具体是哪几个方法?
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
}
23 有这样一个需求,统计一个用户的已经曝光了某一个页面,想追根溯是从哪几个页面过来的,然后求出在这几个来源所占的比例。你要怎么建模处理?
(面试官的意思是将所有埋点按时间顺序存在一个List 里,然后可能需要自定义udf函数,更主要的是考虑一些异常情况,比如点击流中间是断开的,或者点击流不全,怎么应对)
23 说一下你对元数据的理解,哪些数据算是元数据
技术元数据、业务元数据、操作元数据、管理元数据
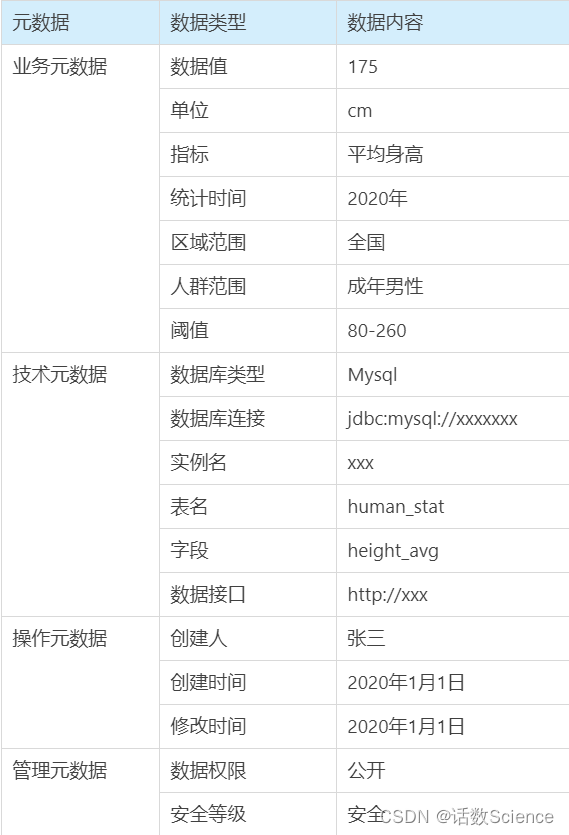
元数据管理技术架构
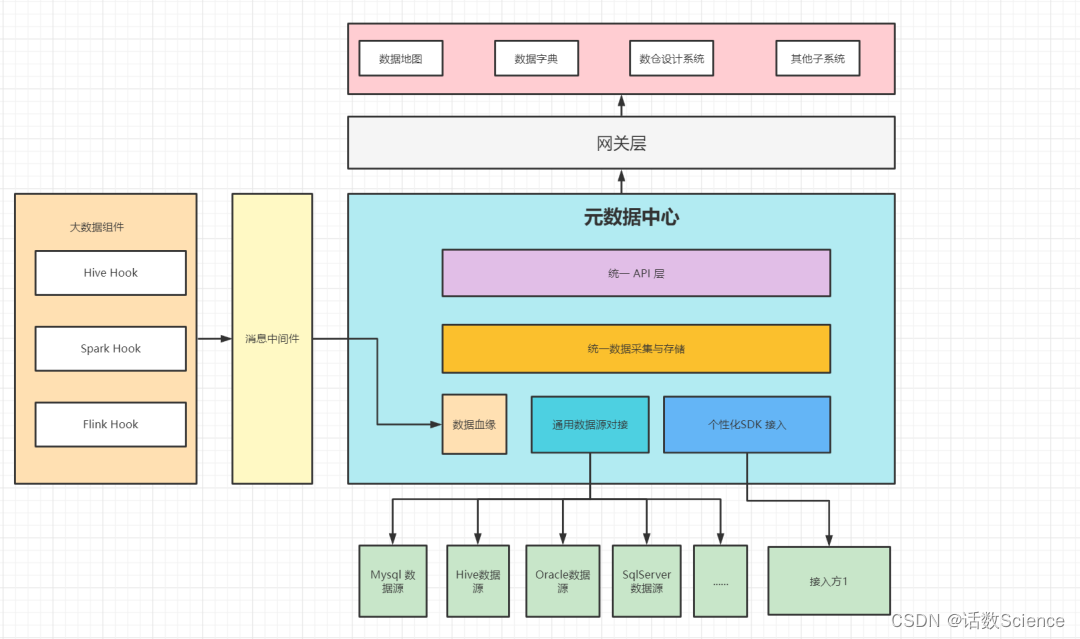
参考:元数据:数据治理的基石-腾讯云开发者社区-腾讯云
一文彻底了解元数据管理与架构设计-腾讯云开发者社区-腾讯云
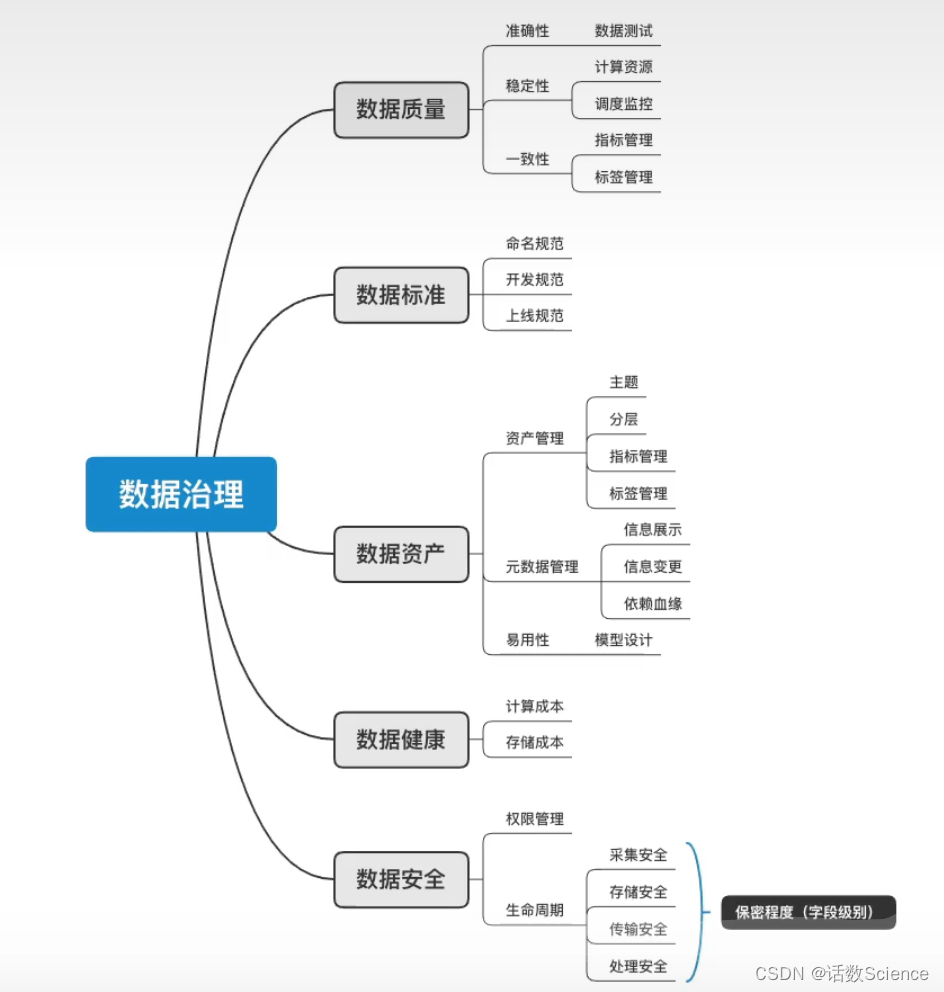
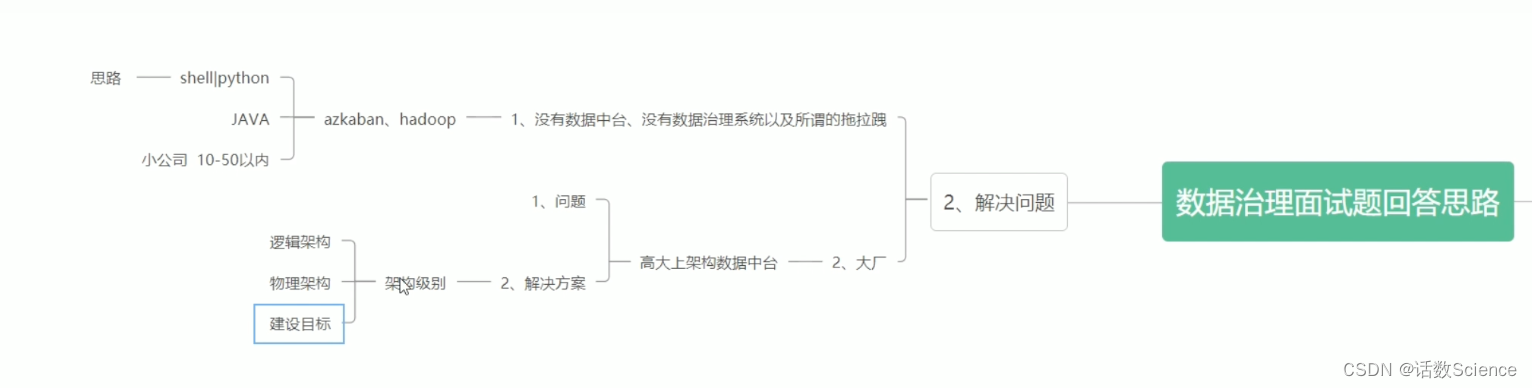
24 有过数据治理的经验吗?
数据治理涉及的方面
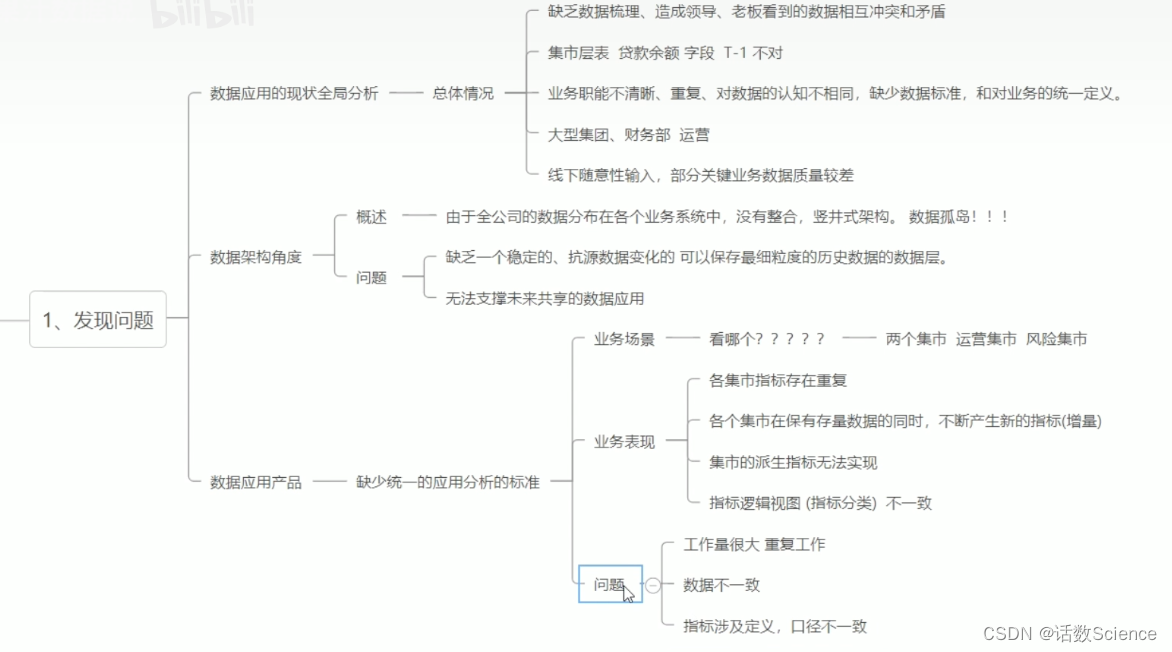
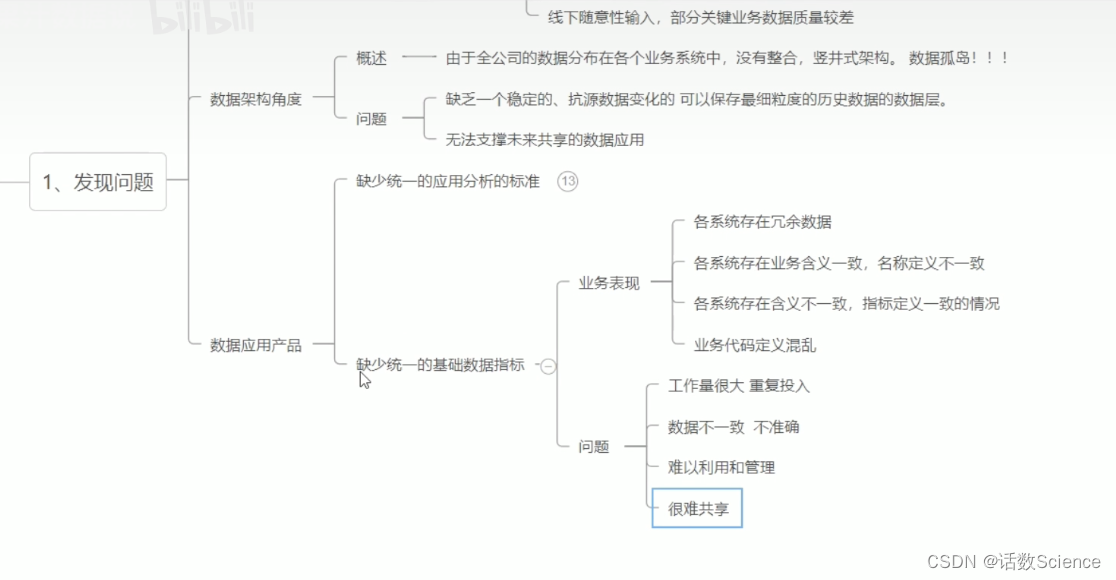
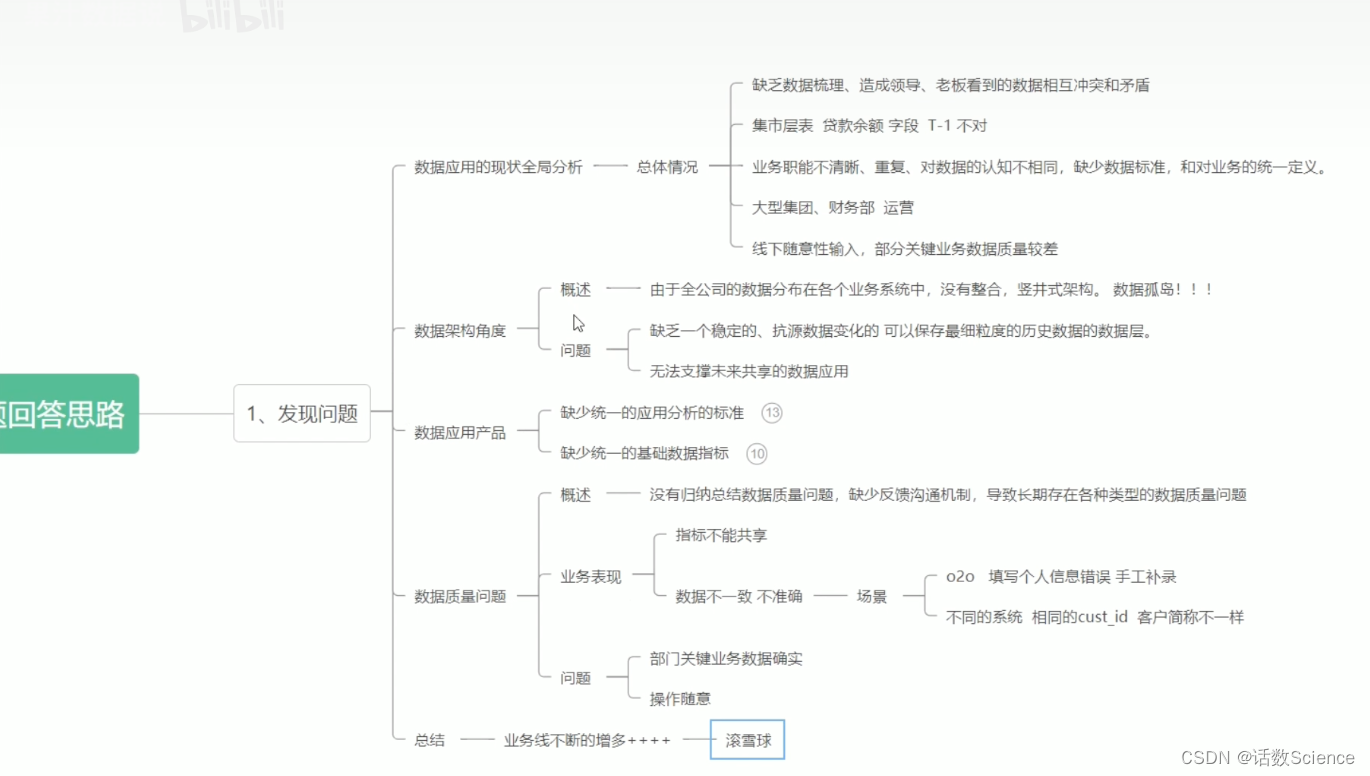
基于业务现状,面临的问题和挑战来讲。
25 说一下你门公司的数据是怎么分层处理的,每一层都解决了什么问题
阿里

- 数据引入层(ODS,Operational Data Store,又称数据基础层)
- 数据公共层(CDM,Common Dimensions Model)
- 维度层(DIM,Dimension)
- 明细数据层(DWD,Data Warehouse Detail)
- 汇总数据层(DWS,Data Warehouse Summary)
- 数据应用层(ADS,Application Data Store)
美团

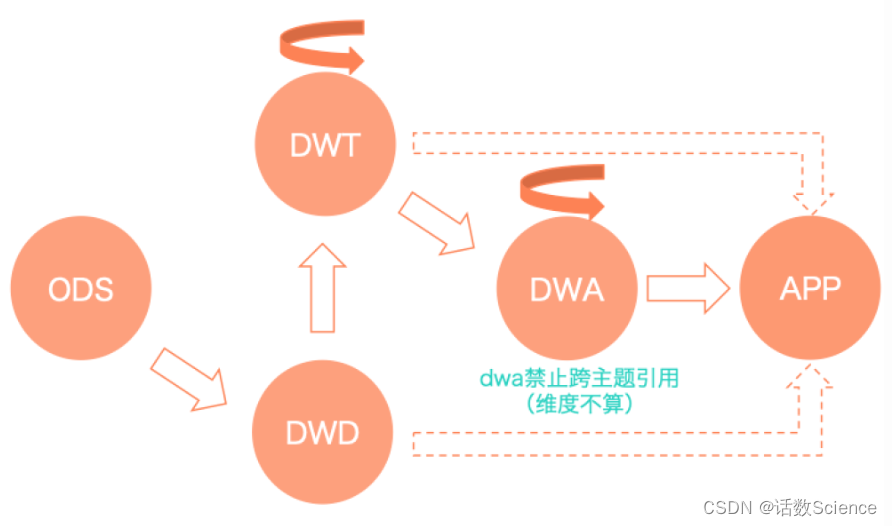

26 讲一下星型模型和雪花模型的区别,以及应用场景
- 雪花模型去除了冗余,设计复杂,可读性差,关联的维度表多,查询效率低,但是可扩展性好,适合OLAP
- 星型模型冗余度高,设计简单,可读性高,关联的维度表少,查询效率高,可扩展性低,适合OLTP
区别
星型模型和雪花模型最根本的区别就是,维度表是直接连接到事实表还是其他的维度表。
1)星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花模型要高。
2)星型模型不用考虑很多正规化的因素,设计和实现都比较简单。
3)雪花模型由于去除了冗余,有些统计就需要通过表的连接才能产生,所以效率不一定有星型模型高。
4)正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
数据仓库更适合使用星型模型来构建底层数据 hive 表,通过数据冗余来减少查询次数以提高查询效率。雪花模型在关系型数据库中(MySQL/Oracle)更加常见。在具体规划设计时,应结合具体场景及两者的优缺点来进行设计,找到一个平衡点去开展工作。
| 属性 | 星型模型 | 雪花模型 |
|---|---|---|
| 维表 | 一级维表 | 多层级维表 |
| 数据总量 | 多 | 少 |
| 数据冗余度 | 高 | 低 |
| 可读性 | 高 | 低 |
| 表个数 | 少 | 多 |
| 表宽度 | 宽 | 窄 |
| 查询逻辑 | 简单 | 复杂 |
| 查询性能 | 高 | 低 |
| 扩展性 | 差 | 好 |
参考:
一文搞清楚数据仓库模型:星型模型和雪花模型的区别 - 简书




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











