






Java语言集合框架提供一系列集合接口类 (collection interface)和实现类,满足对集合中元素对象的各种集合抽象操作。
1. 集合接口类Collection/List/Set/Map
下图显示了在包java.util.*中主要的核心集合接口类,
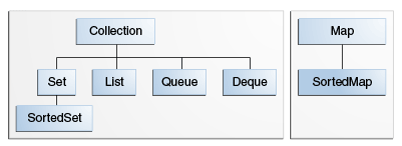
上图中的Collection/List/Set/Map等都是泛型接口,各自的定义和作用如下:
- Collection是集合的顶层接口定义,其它的集合类都继承于Collection(除Map),这个接口定义了对集合元素的增删改查,及其提供interator用于循环整个集合中的元素列表等等。
- Set是一个不能有重复元素的集合。
- List是一个有序元素集合,有序是指按照加入/插入数组位置的顺序,集合中可以有重复的元素,可以认为List就是一个数组,访问时可以通过位置index直接访问元素。
- Map是对键值对(key/value)元素的集合,集合中不能有重复的key。
- Queue/Deque是一个提供能够进行队列操作的集合,比如FIFO(先进先出)/ LIFO(后进先出)。
- SortedSet/SortedMap是一个按照元素进行升序排列的集合,集合中的元素排序取决于Comparator的实现。
2. 集合实现类和工具类
集合的实现类很多,JDK中提供的实现类都在java.util.*包中,其中List/Set/Map有如下几个实现类,
- List
- ArrayList/LinkedList/Vector
- Map
- HashMap/LinkedHashMap/TreeMap/WeakHashMap
- Hashtable/ConcurrentHashMap
- Set
- HashSet/LinkedHashSet/TreeSet
集合的工具类Collections/Arrays提供一些集合的复制、比较、排序和转换操作,
- Utilities
- Collections/Arrays
上述各个实现类和接口类的关系见下图,
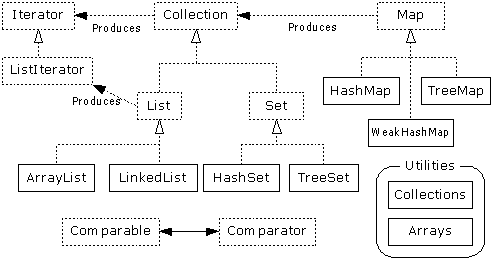
3. 集合实现类的特点和数据结构
下面以表格形式列出各个实现类的特点和区别,方便进行对比,其中不同的数据结构决定了各个集合实现类的不同性能特点,详细的数据结构描述见后面注解。
| 集合接口 | 集合实现类 | 是否按插入顺序存放 | 是否按有序存放(注1) | 是否可以存放重复元素 | 是否线程安全 | 数据结构特性描述 |
| List | ArrayList | Yes | No | Yes | No | 基于动态数组的数据结构,注2 |
| LinkedList | Yes | No | Yes | No | 基于双向链表的数据结构,查询慢,插入快,注3。 | |
| Vector | Yes | No | Yes | Yes* | Deprecated,注4。 | |
| Map | HashMap | No | No | Yes | No | 基于哈希表的元素数据离散分布,注5。 |
| LinkedHashMap | No | No | Yes | No | 基于哈希表的元素数据离散分布,除此之外集合元素数据之间有双向链表指针,注6。 | |
| TreeMap | No | Yes | Yes | No | 基于红黑树的数据结构,元素需要提供Comparator实现,用于有序存放,注7。 | |
| WeakHashMap | No | No | Yes | No | ||
| Hashtable | No | No | Yes | Yes | 基于哈希表的元素数据分散分布,通过对象锁实现线程安全 | |
| ConcurrentHashMap | No | No | Yes | Yes | 通过lock实现线程安全,在多线程环境中比Hashtable有更好的并发性能 | |
| Set | HashSet | No | No | No | No | 底层使用HashMap实现 |
| LinkedHashSet | Yes | No | No | No | 底层使用LinkedHashMap实现 | |
| TreeSet | No | Yes | No | No | 底层使用TreeMap实现,元素需要提供Comparator实现,用于有序存放 |
注1:元素是否按有序存放,是指集合中元素根据Comparator进行比较后升序排列。
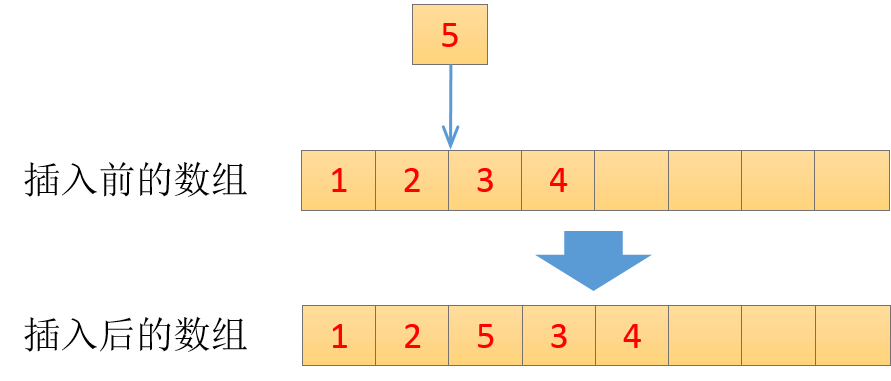
注2:ArrayList是基于动态数组的数据结构,数据插入时,会导致整个后端数据的往后移动一位,所以插入速度慢,但是根据位置索引可以直接访问元素数据,所以通过位置索引查询数据速度会很快。
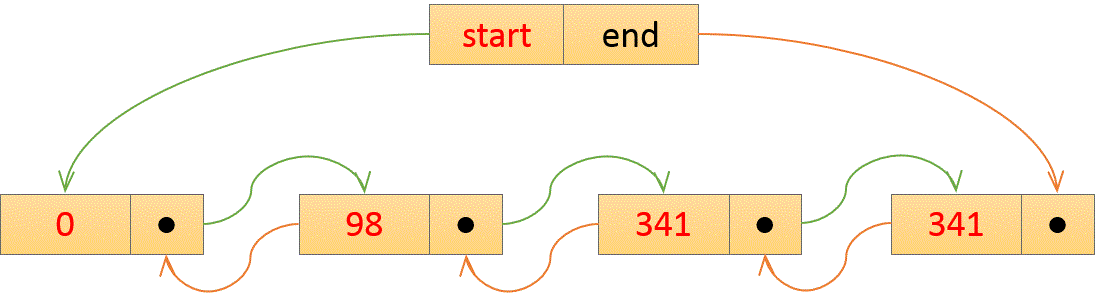
注3:LinkedList是基于双向链表的数据结构,插入快,但是查询会比较慢。另外LinkedList支持getFirst/getLast/removeFirst/removeLast/addFirst/addLast操作,可以方便实现FIFO/LIFO队列操作。双向链表的数据结构如下图所示,
注4:Vector由于其在所有的get/set上进行了synchronize,导致难于在并发编程发挥作用,在很多时候可以使用List list = Collections.synchronizedList(new ArrayList())方法取代,目前不建议使用Vector来用于线程安全的编程。
注5:HashMap基于哈希表的元素数据离散分布,是指数据按照一定规则进行离散,比如数值按16取模,各自落入不同的子集合,因此数据元素排列插入后无序,见下图所示,
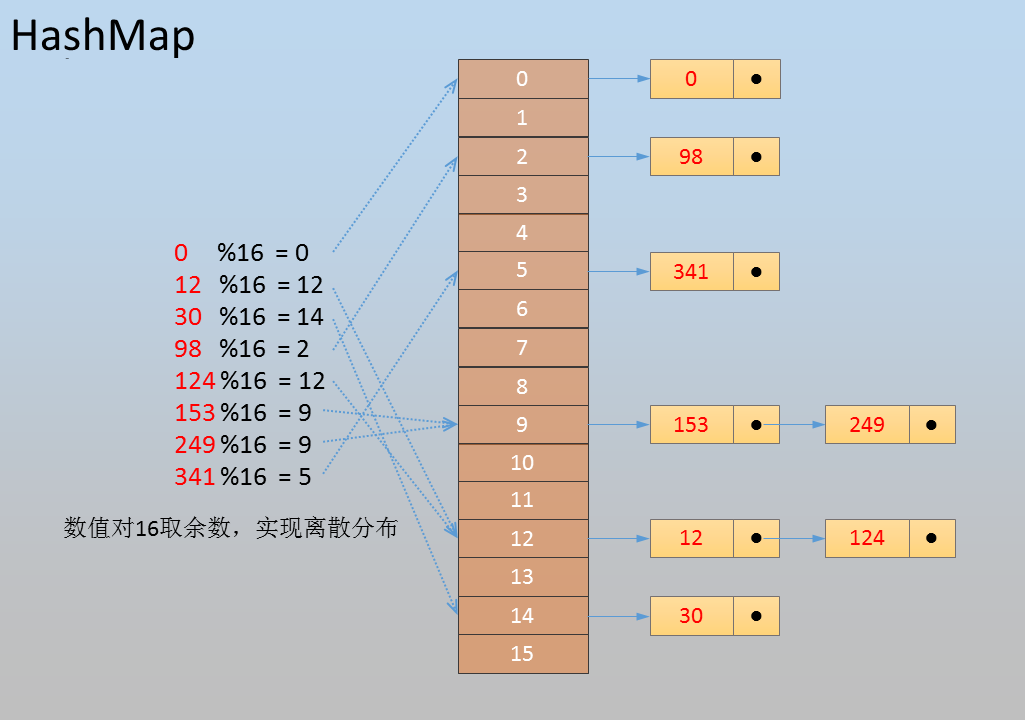
注6:LinkedHashMap在集合元素数据之间有双向链表指针,数据的删除和插入快,数据元素排列后无序,见下图所示,
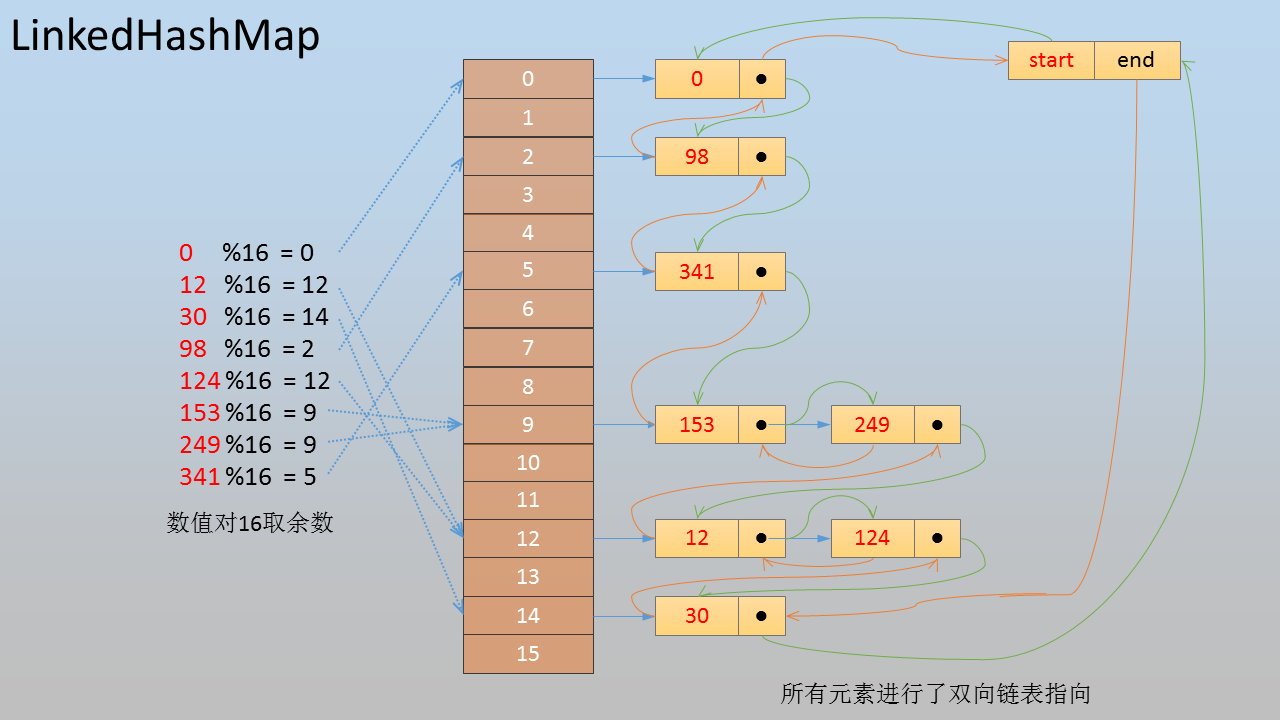
注7:TreeMap基于红黑树(近平衡二叉树)的数据结构,这个数据结构最大的特点是各个元素数据达到平衡分布,最远和最近叶子节点离根节点距离相差不超1,使得元素的查找和插入速度达到O(log N)级别。

4. 集合实现类的插入操作
我们可以尝试为各个集合实现类进行插入数据操作,然后查看数据元素在集合中的数据排列,下面主要观察数据排列是否有序,是否按照插入顺序排列。通过观察,可以更加深入地了解各个实现类的数据结构和特性。
List的数据插入
下面的代码新建了三个List实现类实例,然后依次插入10个随机数,最后打印出列表数据。
List<Integer> list1 = new ArrayList<>();
List<Integer> list2 = new LinkedList<>();
List<Integer> list3 = new Vector<>();
for (int i = 0; i < 10; i++) {
//产生一个随机数,并将其放入List中
int value = (int) (Math.random() * 100);
App.logMessage("第 " + i + " 次产生的随机数为:" + value);
list1.add(value);
list2.add(value);
list3.add(value);
}
App.logMessage("ArrayList:" + list1);
App.logMessage("LinkedList:" + list2);
App.logMessage("Vector:" + list3);
结果如下,请观察元素插入和排列顺序,
第 0 次产生的随机数为:41
第 1 次产生的随机数为:68
第 2 次产生的随机数为:62
第 3 次产生的随机数为:4
第 4 次产生的随机数为:18
第 5 次产生的随机数为:38
第 6 次产生的随机数为:97
第 7 次产生的随机数为:9
第 8 次产生的随机数为:19
第 9 次产生的随机数为:1
ArrayList:[41, 68, 62, 4, 18, 38, 97, 9, 19, 1]
LinkedList:[41, 68, 62, 4, 18, 38, 97, 9, 19, 1]
Vector:[41, 68, 62, 4, 18, 38, 97, 9, 19, 1]
可以看到,各个List的数据元素排列和插入顺序一致,这也是由于动态数组的数据结构带来的特性。
Set的数据插入
下面的代码新建了三个Set实现类实例,然后依次插入10个随机数,最后打印出列表数据。
Set<Integer> set1 = new HashSet<>();
Set<Integer> set2 = new LinkedHashSet<>();
Set<Integer> set3 = new TreeSet<>();
for (int i = 0; i < 10; i++) {
//产生一个随机数,并将其放入Set中
int value = (int) (Math.random() * 100);
App.logMessage("第 " + i + " 次产生的随机数为:" + value);
set1.add(value);
set2.add(value);
set3.add(value);
}
App.logMessage("HashSet:" + set1);
App.logMessage("LinkedHashSet:" + set2);
App.logMessage("TreeSet :" + set3);
结果如下,请观察元素插入和排列顺序,
第 0 次产生的随机数为:51
第 1 次产生的随机数为:86
第 2 次产生的随机数为:24
第 3 次产生的随机数为:66
第 4 次产生的随机数为:76
第 5 次产生的随机数为:59
第 6 次产生的随机数为:13
第 7 次产生的随机数为:34
第 8 次产生的随机数为:89
第 9 次产生的随机数为:21
HashSet:[66, 34, 51, 21, 86, 24, 89, 59, 76, 13]
LinkedHashSet:[51, 86, 24, 66, 76, 59, 13, 34, 89, 21]
TreeSet :[13, 21, 24, 34, 51, 59, 66, 76, 86, 89]
可以看到,HashSet/LinkedHashSet无序,TreeSet按大小依次排列。这是由于HashSet/LinkedHashSet/TreeSet底层实现用的是HashMap/LinkedHashMap/TreeMap,因此继承了各自的特点。
Map的数据插入
下面的代码新建了五个Map实现类实例,然后依次插入10个随机数(随机数为key),最后打印出列表数据。
Map map1 = new HashMap();
Map map2 = new TreeMap();
Map map3 = new LinkedHashMap();
Map map4 = new WeakHashMap();
Map map5 = new Hashtable();
Map map6 = new ConcurrentHashMap();
for (int i = 0; i < 10; i++) {
//产生一个随机数,并将其放入map中
int value = (int) (Math.random() * 100);
App.logMessage("第 " + i + " 次产生的随机数为:" + value);
if (!map1.containsKey(value)){
map1.put(value, i);
map2.put(value, i);
map3.put(value, i);
map4.put(value, i);
map5.put(value, i);
map6.put(value, i);
}
}
App.logMessage("产生的随机数为key,index为value");
App.logMessage("HashMap:" + map1);
App.logMessage("TreeMap:" + map2);
App.logMessage("LinkedHashMap:" + map3);
App.logMessage("WeakHashMap:" + map4);
App.logMessage("Hashtable:" + map5);
App.logMessage("ConcurrentHashMap:" + map5);
结果如下,请观察元素插入和排列顺序,
第 0 次产生的随机数为:48
第 1 次产生的随机数为:86
第 2 次产生的随机数为:81
第 3 次产生的随机数为:19
第 4 次产生的随机数为:90
第 5 次产生的随机数为:74
第 6 次产生的随机数为:55
第 7 次产生的随机数为:29
第 8 次产生的随机数为:89
第 9 次产生的随机数为:65
产生的随机数为key,index为value
HashMap:{48=0, 81=2, 65=9, 19=3, 86=1, 55=6, 89=8, 90=4, 74=5, 29=7}
TreeMap:{19=3, 29=7, 48=0, 55=6, 65=9, 74=5, 81=2, 86=1, 89=8, 90=4}
LinkedHashMap:{48=0, 86=1, 81=2, 19=3, 90=4, 74=5, 55=6, 29=7, 89=8, 65=9}
WeakHashMap:{90=4, 74=5, 89=8, 29=7, 65=9, 55=6, 81=2, 86=1, 48=0, 19=3}
Hashtable:{90=4, 89=8, 65=9, 19=3, 86=1, 81=2, 55=6, 29=7, 74=5, 48=0}
ConcurrentHashMap:{90=4, 89=8, 65=9, 19=3, 86=1, 81=2, 55=6, 29=7, 74=5, 48=0}
可以看到,TreeMap按key大小升序排列,LinkedHashMap按value大小升序排列,其它无序。
集合实现类的性能比较
为了比较各个集合实现类的性能,对各个集合实现类进行如下三个操作,
- 插入:在集合中插入0-N个数据元素,N为指定性能测试要达到的数组大小
- 查询:在集合中一一查询0-N个数据元素,N为指定性能测试的数组大小,换句话说轮询集合中所有元素
- 删除:在集合中一一删除0-N个数据元素,N为指定性能测试的数组大小,换句话说删除集合中所有元素
测试数组大小分别为1万、5万、10万、15万,线性倍增,然后观察各个集合实现类在不同数组大小下的性能表现。
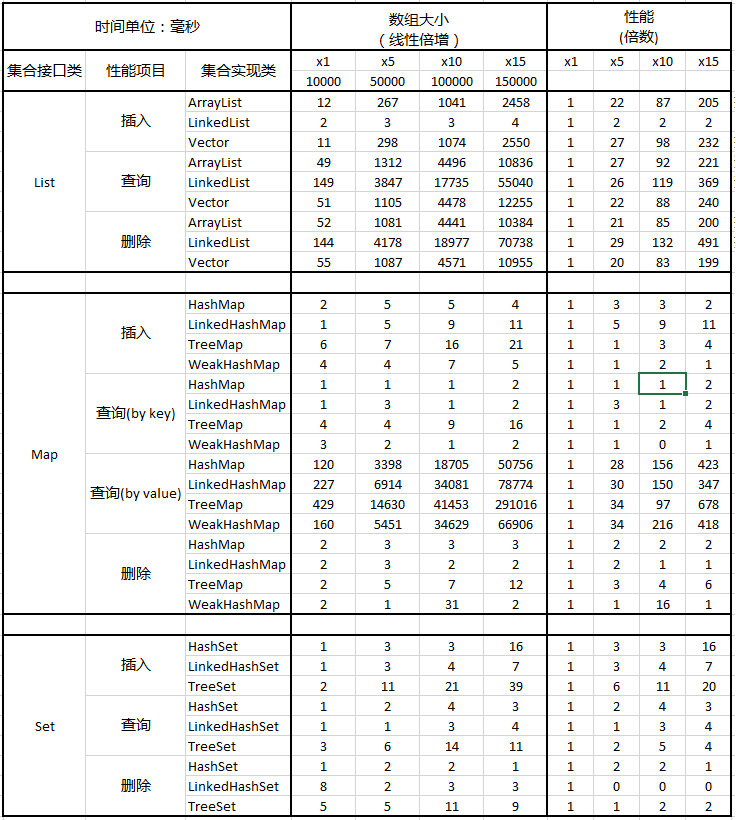
注:在Map中查询分别添加了通过key/value查询的测试。
测试环境:Java版本为1.8.0_111,主机环境:Win7 SP1 x64, intel i5-6600K 4 cores 3.5GHz CPU, 16G memory。
可以看到,
- List集合实现类在插入、查询、删除操作上,随着数组变大有明显的性能开销增加,性能开销的增加倍数超过数组大小的增加倍数。
- Map集合实现类在通过value查询性能开销很大,在实际编程中,尽量避免此类操作
- 表中有些操作时间开销都在10毫秒内,随着数组倍增,性能表现不错,这些操作可以在编程中多加利用。
测试程序代码
演示代码仓库地址:https://gitee.com/pphh/blog,可以通过如下git clone命令获取仓库代码,
git clone git@gitee.com:pphh/blog.git
上述测试程序代码样例在文件路径171117_java_collection\demo中。
参考资料
- Java Tutorials - Collection介绍
- Java Tutorials - Collection Interfaces介绍
- wiki - 红黑树















 4738
4738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









