







极大似然估计(Maximum Likelihood Estimation)
极大似然估计(MLE),就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值. MLE提供了一种给定观察数据来评估模型参数的方法。也就是似然函数的直观意义是刻画参数 与样本数据的匹配程度。
极大似然估计公式(离散型统计模型)
极大似然估计公式(连续性统计模式)
这个公式表示的是**似然函数(Likelihood Function)** \( L(\theta) \),它在统计学中用于描述在给定参数 \(\theta\) 下,观察到当前样本数据 \( \{x_1, x_2, \dots, x_n\} \) 的概率。具体来说:
- 符号解释:
- \( \prod_{i=1}^{n} \) 表示从第 1 个样本到第 \( n \) 个样本的连乘。
- \( P_{\theta}(X_i = x_i) \) 表示在参数 \(\theta\) 下,随机变量 \( X_i \) 取值为 \( x_i \) 的概率(或概率密度,如果 \( X_i \) 是连续变量)。
- \( \theta \) 是模型的未知参数(可以是标量、向量或其他形式)。
- 意义:
- 似然函数衡量的是:对于不同的参数值 \(\theta\),当前观测数据出现的可能性有多大。
- 它是参数 \(\theta\) 的函数,而数据 \( \{x_i\} \) 是固定的。
- 用途:
- 最大似然估计(MLE):通过最大化 \( L(\theta) \) 来估计参数 \(\theta\),即找到使当前数据最“可能”出现的参数值。
- 通常会对似然函数取对数(对数似然函数),将连乘转化为求和,简化计算。
- 示例:
- 假设 \( X_i \) 服从伯努利分布(如抛硬币),\( P_{\theta}(X_i=1) = \theta \),\( P_{\theta}(X_i=0) = 1-\theta \)。
- 若观测数据为 \( \{1, 0, 1\} \),则似然函数为:
\[
L(\theta) = \theta \cdot (1-\theta) \cdot \theta = \theta^2 (1-\theta).
\]
- 通过最大化 \( L(\theta) \) 可估计出 \(\theta\) 的最可能值。
最大似然估计公式是统计学中参数估计的核心工具,通过量化数据对参数的支持程度,帮助我们从数据中推断最优参数。
上面提到的最大似然估计公式通常取对数进行计算,主要有以下几个原因:
- 简化计算:连乘 → 求和
- 原始似然函数是概率的连乘形式:
\[
L(\theta) = \prod_{i=1}^n P_\theta(X_i = x_i).
\]
当样本量 \( n \) 较大时,直接计算连乘会导致数值溢出(结果过大或过小,超出计算机浮点数范围)。
- 取对数后,连乘变为求和,避免数值问题:
\[
\ln L(\theta) = \sum_{i=1}^n \ln P_\theta(X_i = x_i).
\]
求和运算更稳定,且对数函数单调递增,最大化 \(\ln L(\theta)\) 等价于最大化 \( L(\theta) \)。
- 数学性质更优
- 导数计算更方便:
连乘的导数需要用到乘法法则,而对数似然的导数是求和形式,更容易求解:
\frac{d}{d\theta} \ln L(\theta) = \sum_{i=1}^n \frac{d}{d\theta} \ln P_\theta(X_i = x_i).
这在求解最大似然估计的方程(令导数为零)时更简洁。
- 凸函数优化:
许多概率分布的对数似然函数是凸函数(如指数族分布),便于使用梯度下降等优化算法找到全局最大值。
- 避免数值下溢(Underflow)
- 概率值通常非常小(尤其在连续分布或高维数据中),连乘会导致结果趋近于零(例如 \(0.01^{100}\)),造成计算机浮点数精度丢失。
- 对数将小数值映射到负无穷附近(如 \(\ln(0.01) = -4.605\)),保留有效数字。
- 统计理论的一致性
- 对数似然函数在统计推断中更常用。例如:
- 信息矩阵(Fisher Information)的定义基于对数似然的二阶导数。
- 似然比检验(Likelihood Ratio Test)直接使用对数似然值的差异。
- 示例说明
假设观测数据为 \( \{1, 0, 1\} \),服从伯努利分布 \( P_\theta(X_i=1) = \theta \):
- 原始似然函数:
\[
L(\theta) = \theta \cdot (1-\theta) \cdot \theta = \theta^2 (1-\theta).
\]
- 对数似然函数:
\[
\ln L(\theta) = 2 \ln \theta + \ln(1-\theta).
\]
-求导并令导数为零:
\[
\frac{d}{d\theta} \ln L(\theta) = \frac{2}{\theta} - \frac{1}{1-\theta} = 0 \implies \hat{\theta} = \frac{2}{3}.
\]
显然,对数形式更易求导和解方程。取对数的本质是通过数学变换简化问题,同时保持优化目标的一致性。它解决了数值计算的稳定性问题,并保留了似然函数的极值点(因为 \(\ln\) 是单调递增函数)。这是统计学和机器学习中广泛使用的技巧。
最小二乘估计(Least Squares Method)
最小二乘法(Least Squares Method) 是一种用于拟合数据的经典回归分析方法,广泛应用于线性回归、非线性回归和统计学中。其核心思想是通过最小化观测数据与模型预测值之间的误差平方和,找到最优的模型参数。
最小二乘法的目标是找到一组模型参数,使得模型预测值与实际观测值之间的误差平方和最小。对于线性模型,最小二乘法可以用于估计回归系数。
最小二乘法公式是一个数学的公式,在数学上称为曲线拟合,不仅仅包括线性回归方程,还包括矩阵的最小二乘法,最小二乘估计的公式推导如下:
设第i 个测量量的残差为:
那么所有测量量的误差和:
其中,带入上式将J改写为:
对J求x的一阶偏导,偏导等于0便找到使J最小的值
MLE和LSE的区别和联系
1.区别
区别1:基本原理不同
最大似然估计(MLE) :它是基于概率密度函数(pdf)的观点来估计参数的。假设有一个概率分布模型,其概率密度函数形式已知,但参数未知。比如说,我们知道数据服从正态分布,但是正态分布的均值 μ 和方差 σ² 不知道。MLE 的目标是找到一组参数值(如 μ 和 σ²),使得观测到的数据出现的概率最大。例如,对于一组独立同分布的数据样本x₁, x₂,…,xₙ,来自正态分布 N(μ,σ²),其联合概率密度函数为:
MLE 就是通过最大化这个联合概率密度函数来估计 μ 和 σ²。
最小二乘估计(LSE) :主要是基于最小化观测值与模型预测值之间的误差平方和来进行参数估计。假设我们有一个线性模型 y = Xβ + ε,其中 y 是观测值向量,X 是设计矩阵,β 是未知参数向量,ε 是误差向量。LSE 的目标是找到 β 的估计值,使得残差平方和 最小。例如,在一元线性回归中,我们有一组数据点(x₁, y₁),(x₂, y₂),…,(xₙ, yₙ),假设模型为 y = β₀ + β₁x + ε,LSE 就是要找到 β₀ 和 β₁,使得
最小。
区别2:假设条件不同
MLE 要求对数据的分布有一定的假设,例如,数据可能服从正态分布、伯努利分布等,然后在这个分布模型的基础上进行参数估计。而 LSE 主要是用于线性回归模型,并且其在经典线性回归模型中,假设误差项具有零均值、同方差且相互独立等性质,但对误差项的分布没有明确的要求,不过在一些情况下,如高斯 - 马尔可夫定理中,当误差项满足一定的条件(零均值、同方差、无序列相关等),LSE 才具有最优线性无偏估计(BLUE)的性质。
2. 联系
在某些情况下,两者是等价的。例如,当模型误差项服从正态分布,并且我们使用最小二乘估计来估计线性回归模型的参数时,二最小乘估计可以看作是最大似然估计的一个特例。因为在正态分布假设下,最大化似然函数就等价于最小化误差平方和。这是因为正态分布的概率密度函数包含误差项平方的形式,当最大化似然函数时,实际上是在最大化误差项平方的负数相关的部分,也就是相当于最小化误差平方和。
3. 使用场景
最大似然估计(MLE): 当我们对数据的生成过程有一定的先验知识,并且能够假设数据服从某种概率分布时,MLE 是一个很好的选择。例如,在分类问题中,如伯努利分布可能被用来描述二分类的数据生成过程,通过 MLE 可以估计出类别出现的概率。在构建复杂的概率模型,如混合模型(如高斯混合模型)、指数族分布模型等场景中,MLE 能够有效地估计模型的参数。例如,在自然语言处理中的隐马尔可夫模型(HMM),通过 MLE 来估计状态转移概率和观测概率等参数。
最小二乘估计(LSE): LSE 最典型的使用场景是在线性回归分析中,当我们要拟合一个线性模型来描述变量之间的关系时,如在经济学中分析消费与收入之间的线性关系,在工程学中研究材料的应力应变关系等。在时间序列分析中,对于一些简单的趋势模型(如线性趋势模型),也可以使用 LSE 来估计趋势参数,以预测未来的时间序列值。
MLE和LSE实例
1.使用scipy.optimize.minimize完成MLE
最大似然估计的目标是找到某种概率密度分布的参数值,使得似然函数最大。由于最大化似然函数等价于最小化负对数似然函数。下面的代码是用optimize.minimize估计正态分布数据集的均值和方差。minimize函数中method参数表示MLE采用的方法,每种方法的适用场景和优缺点参考附录表格1.
import numpy as np
from scipy.stats import norm
import scipy.optimize as opt
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
np.random.seed(0)
true_mu = 2
true_sigma = 3
data = np.random.normal(loc=true_mu,scale=true_sigma,size=5000)
#定义opt.minimize可以调度的负对数似然函数
def negative_log_likehood(params):
mu,sigma = params
if sigma <0:
return np.inf
return -np.sum(norm.logpdf(data,loc=mu,scale=sigma))
initial_guess = [1,2]
#method='L-BFGS-B' 是MLE和MAP常用的算法
result = opt.minimize(negative_log_likehood,initial_guess,method='L-BFGS-B')
if result.success:
mu_mle,sigma_mle = result.x
print("最大似然估计:mu={:.3f},sigma = {:.3f} ".format(mu_mle,sigma_mle))
else:
print("优化失败")
x = np.linspace(min(data)-2, max(data)+2, 5000)
plt.hist(data, bins=30, density=True, alpha=0.7, label='观测数据')
plt.plot(x, norm.pdf(x, mu_mle, sigma_mle),
'r-', label='MLE拟合')
plt.plot(x, norm.pdf(x, true_mu, true_sigma),
'b--', label='真实分布')
plt.legend()
plt.title('正态分布MLE估计结果')
plt.xlabel('x')
plt.ylabel('密度')
plt.grid()
plt.show()计算结果:
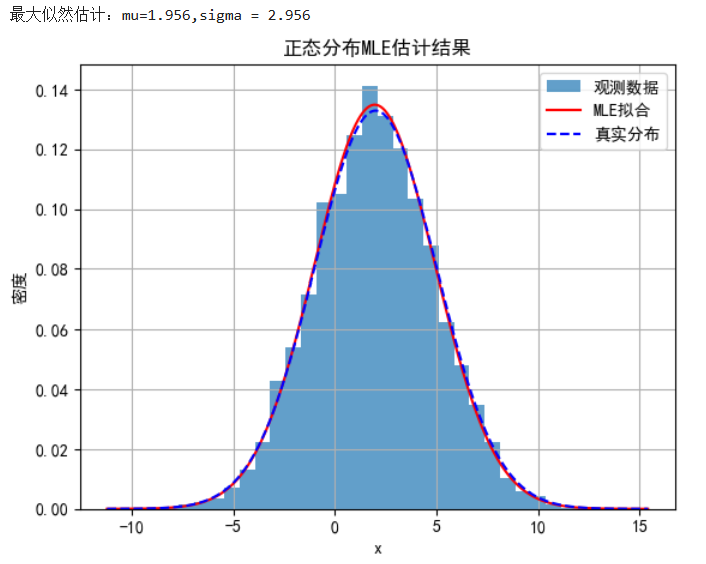
2. 使用scipy.optimize.curve_fit完成LSE
用于曲线拟合,它是基于least_squares实现的,适用于拟合函数参数使得函数与数据点之间的平方差之和最小,下面是对MLE估计的同一个正态分布数据集,使用scipy.optimize.curve_fit的LSE算法进行估计。
from scipy.optimize import curve_fit
# 定义正态分布概率密度函数
def normal_distribution(x, mu, sigma):
return (1 / (sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma)**2)
initial_guess = [1,2]
params, covariance = curve_fit(normal_distribution, x, np.histogram(data, bins=5000, density=True)[0],initial_guess)
mu_fit, sigma_fit = params
print("最小二乘估计:mu={:.3f},sigma = {:.3f} ".format(mu_fit,sigma_fit))
plt.hist(data, bins=50, density=True, alpha=0.6, color='g', label='原始数据')
plt.plot(x, normal_distribution(x, *params), 'r-', label='LSE拟合曲线')
plt.plot(x, norm.pdf(x, mu_mle, sigma_mle), 'b-', label='MLE拟合')
plt.legend()
plt.title('正态分布LSE估计结果')
plt.grid()
plt.show()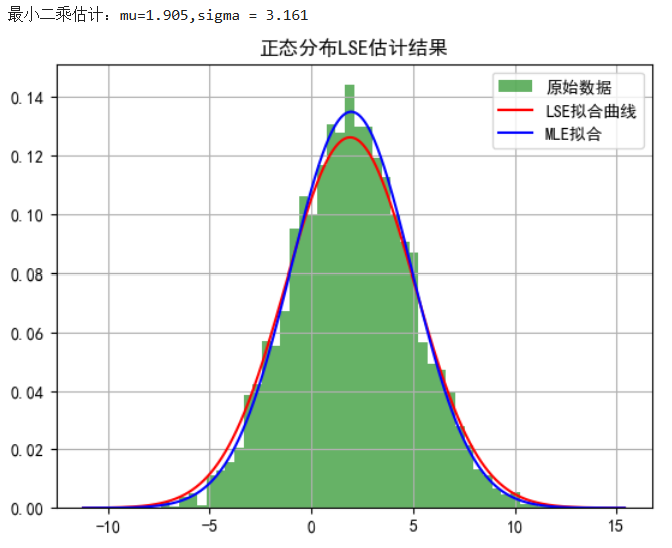
使用LSE算法完成y=xβ+b 多元线性回归,其中x是100*3的矩阵,β是3*1的系数向量,估计β和b(截距项)的值。
import numpy as np
from scipy.optimize import curve_fit
# 定义多元线性回归模型
def multilinear_model(x, *params):
# x 是一个二维数组,每一列代表一个输入变量
# params 是回归系数,包括截距项 beta0 和各变量的系数 beta1, beta2, ...
return params[0] + np.sum(params[1:] * x, axis=1)
# 生成模拟数据
np.random.seed(42)
n_samples = 100
n_features = 3 # 3 个输入变量
# 生成随机输入数据
X = np.random.rand(n_samples, n_features)
# 生成目标变量,基于多元线性模型加上噪声
beta_true = np.array([2.0, 3.0, -1.5, 0.5]) # 真实参数,包括截距项
y = beta_true[0] + np.dot(X, beta_true[1:]) + np.random.normal(0, 0.1, n_samples)
# 使用 curve_fit 进行拟合
initial_guess = np.ones(n_features + 1) # 初始猜测值,包括截距项
params, covariance = curve_fit(multilinear_model, X, y, p0=initial_guess)
# 输出拟合参数
beta0_fit = params[0]
beta_fit = params[1:]
print(f"截距项估计值: {beta0_fit}")
print(f"回归系数估计值: {beta_fit}")
# 可以进一步计算拟合优度等指标
y_pred = multilinear_model(X, *params)
mse = np.mean((y - y_pred)**2)
print(f"均方误差 (MSE): {mse}")
#图形化显示实际值与估计值的对比图 y vs y_pred
#绘制实际值与预测值的散点图,并在图中添加一条对角线(理想情况下,所有点都应该在这条线上)
plt.figure(figsize=(10, 6))
plt.scatter(y, y_pred, alpha=0.6)
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--')
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Actual vs Predicted Values')
plt.grid()
plt.show()估计结果如下:
截距项估计值: 1.9735014570832 回归系数估计值: [ 3.02780041 -1.51577622 0.55704057] 均方误差 (MSE): 0.009203988206421482
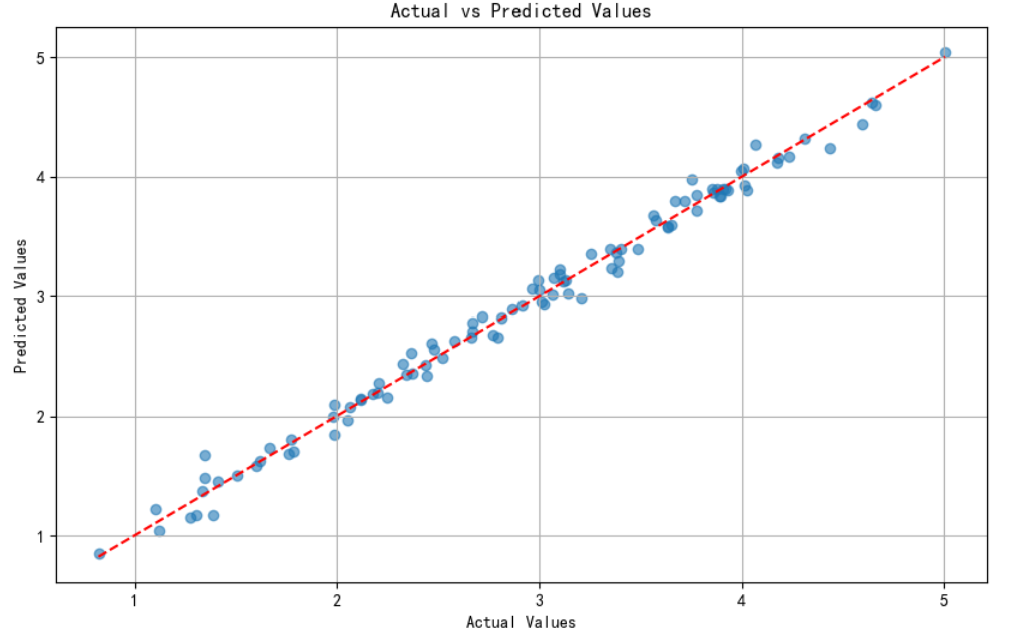
附录
表格1
| 方法名称 | 适用场景 | 优点 | 缺点 |
| Nelder-Mead | 目标函数不可导、非光滑或复杂,需要简单易用的优化方法 | 不需要梯度信息,适用于不可导或非光滑函数;实现简单,易于使用 | 收敛速度较慢,对于高维问题效果不佳;容易陷入局部最优 |
| Powell | 目标函数不可导或导数难以计算,且无约束优化问题 | 不需要梯度信息;对于某些高维问题表现较好 | 对初始点敏感,可能需要较多迭代次数;对于有约束问题不适用 |
| CG | 大规模无约束优化问题,目标函数可导且具有连续的一阶导数 | 利用梯度信息,收敛速度快;内存占用低,适用于大规模问题 | 需要目标函数可导,对初始点和参数选择敏感 |
| BFGS | 中等规模无约束优化问题,目标函数可导且具有连续的二阶导数 | 收敛速度快,利用二阶导数信息(通过拟牛顿法近似);适用于光滑函数 | 需要目标函数可导,内存占用相对较高 |
| Newton-CG | 中小规模无约束优化问题,目标函数可导且海森矩阵易计算或近似 | 收敛速度快,利用精确的二阶导数信息;适用于凸优化问题 | 需要计算或近似海森矩阵,计算成本较高 |
| L-BFGS-B | 变量具有边界约束的大规模优化问题,目标函数可导 | 处理边界约束有效;内存效率高,适用于大规模问题;收敛速度快 | 需要目标函数可导,对初始点选择敏感 |
| TNC | 变量具有边界约束的优化问题,目标函数可导 | 处理边界约束有效;允许目标函数不连续;适用于中小规模问题 | 需要目标函数可导,可能对某些复杂函数表现不佳 |
| COBYLA | 变量具有约束(包括边界和一般约束)的优化问题,目标函数可能不可导 | 可处理一般约束;不需要梯度信息;适用于中小规模问题 | 收敛速度较慢,对初始点敏感 |
| COBYQA | 无约束优化问题,目标函数可能不可导,需要简单易用的优化方法 | 不需要梯度信息;适用于不可导函数;实现简单 | 对高维问题效果不佳,容易陷入局部最优 |
| SLSQP | 变量具有边界约束和一般约束的优化问题,目标函数可导 | 可处理复杂约束(包括等式和不等式约束);适用于中小规模问题 | 需要目标函数可导,可能对某些复杂约束处理较慢 |
| trust-constr | 一般约束优化问题(包括边界、等式和不等式约束),目标函数可导 | 处理复杂约束有效;适用于大规模问题;提供精确的约束处理 | 需要目标函数可导,可能对某些非光滑函数效果不佳 |
| dogleg | 无约束优化问题,目标函数可导且具有连续的二阶导数 | 利用二阶导数信息,收敛速度快;适用于精确模型 | 需要计算或近似海森矩阵,计算成本较高 |
| trust-ncg | 无约束优化问题,目标函数可导且具有连续的二阶导数 | 利用二阶导数信息,收敛速度快;适用于大规模问题 | 需要计算或近似海森矩阵,计算成本较高 |
| trust-exact | 无约束优化问题,目标函数可导且海森矩阵精确已知 | 利用精确的二阶导数信息,收敛速度快;适用于小规模问题 | 仅适用于海森矩阵精确已知的情况,实际应用较少 |
| trust-krylov | 无约束优化问题,目标函数可导且需要高效处理大规模问题 | 利用迭代方法处理大规模问题;内存效率高;收敛速度快 | 需要目标函数可导,可能对某些非光滑函数效果不佳 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









