







1. 官方文档
本文主要涉及Python标准库以下三个模块(并发执行部分):
threading --- 基于线程的并行 — Python 3.12.2 文档
concurrent.futures --- 启动并行任务 — Python 3.12.2 文档
queue --- 一个同步的队列类 — Python 3.12.2 文档
2. 准备知识
2.1 原子性操作 atomicity operation\executed atomically
“executed atomically” 是指一个操作在执行时是不可分割的,在执行过程中不会被其他线程或进程干扰或修改,要么全部执行成功,要么全部失败,不会出现部分执行成功,部分执行失败的情况。 这个概念通常用于并发编程中,因为在多线程或分布式环境下,多个线程或进程可能同时访问同一个资源,如果没有执行原子操作,就会导致数据不一致或者竞态条件等问题。
常见的原子操作包括加锁、解锁、读取、写入等。原子操作的实现需要考虑多线程或分布式环境下的并发访问和竞争问题,因此需要采用高效的算法和数据结构来实现。
2.2 上下文管理器 context manager
2.2.1 介绍
上下文管理器(Context Manager)是一种用于管理资源的机制。
在Python中,经常需要处理资源(Resources),这些资源可以是文件、网络连接、锁、数据库连接等。管理资源通常需要“设置阶段”和“拆卸阶段”(Setup Phase and Teardown Phase),拆卸阶段需要执行一些清理操作,例如关闭文件、关闭网络连接、释放锁等,如果忘记执行这些清理操作,使程序一直保留这些资源,在不关闭现有资源的情况下,创建和打开给定资源的新实例,有可能损害宝贵的系统资源(compromise valuable system resources),如内存和网络带宽。
不当的资源管理可能带来糟糕的后果,以向文件写入文本为例,写入文本的操作通常是缓存操作(Buffered Operation),调用 write() 写入的数据通常先被写入临时缓冲区,直到 close() 方法被调用时,才会被真正写入物理文件。如果没有调用 close() 方法,缓存区的数据可能会丢失。另外,还有一种可能的场景:程序遇到错误或异常,导致绕过负责释放资源的代码。比如,下述代码中,如果 write() 语句发生异常,文件将无法被关闭,程序可能会因此泄漏一个文件描述符(File Descriptor)。
file = open("hello.txt", "w")
file.write("Hello, World!")
file.close()Python中,有两种常见的资源管理方法:
- A try ... finally construct
- A with construct
第一种方法非常通用,需要主动提供设置和拆除操作的代码来管理任何类型的资源。这种方式可能有点啰嗦,并且需要保证没有遗漏任何清理操作。第二种方式相当于直接地提供了设置和拆卸代码,但这种方式是有限制的:with语句只适用于上下文管理器。
<try ... finally>
在下面的代码示例中,finally子句能保证文件被正确关闭;except子句能处理try语句块中可能发生的异常。
# Safely open the file
file = open("hello.txt", "w")
try:
file.write("Hello, World!")
except Exception as e:
print(f"An error occurred while writing to the file: {e}")
finally:
# Make sure to close the file after using it
file.close()<with>
上下文管理器可以保证在使用完资源后,及时地释放它们,避免资源泄漏(Resource Leak)和其他问题。上下文管理器中定义了运行时上下文(Runtime Context)这一概念(可以理解为进入with语句块前需要执行的代码,以及退出with语句块时需要执行的代码),通过调用__enter__()和__exit__()方法,在语句体被执行前进入该上下文,并在语句执行完毕时退出该上下文,从而完成初始化和清理资源,处理异常等操作。
with语句利用现有的上下文管理器,创建一个运行时上下文(Runtime Context),在上下文管理器的控制下运行一组语句。相比于传统的try…finally结构,with语句能够使代码更清晰、更安全、可重用,而且Python标准库中的许多类都支持with语句。
(1)with语句的语法如下:
with expression as target_var:
do_something(target_var)
上下文管理器对象是通过with之后的表达式而产生的。换句话说,表达式必须返回一个实现上下文管理协议的对象,上下文管理协议由两种方法组成:
| contextmanager.__enter__() | 由with语句调用,用以进入运行时上下文。 |
| contextmanager.__exit__() | 在执行离开with代码块时被调用。 |
(2)as 是可选的。如果使用 as 提供 target_var,那么在上下文管理器对象上调用 .__enter__() 的返回值将绑定到该变量。一些上下文管理器从 .__enter__() 返回 None(没有有用的对象可以返回给调用者),在这些情况下,指定 target_var 没有意义。
(3)with语句的执行过程如下:

应用with语句,将文本写入文件的代码如下:
with open("hello.txt", mode="w") as file:
file.write("Hello, World!")(4)with语句支持多个上下文管理器,支持以逗号分隔的任意数量的的上下文管理器。
with A() as a, B() as b:
pass
比如需要一次打开两个文件,第一个用于读取,第二个用于写入时,可能这样写:
with open("input.txt") as in_file, open("output.txt", "w") as out_file:
# Read content from input.txt
# Transform the content
# Write the transformed content to output.txt
pass2.2.2 上下文管理器 在 threading 中的应用

2.3 标准库 queue
2.3.1 介绍
queue 模块实现了多生产者、多消费者队列,用于在多线程之间进行数据共享和通信。在多线程编程中,使用 queue 库可以避免线程之间的竞争和死锁问题,提高程序的性能和稳定性。

queue 有三种类型的队列对象(它们的区别仅仅是“条目”的提取顺序):queue.Queue(First In, First Out),queue.LifoQueue(Last In, First Out),queue.PriorityQueue(基于优先级)。
- 在 FIFO 队列中,先添加的任务会先被提取
- 在 LIFO 队列中,最近添加的条目会先被提取 (类似于一个栈)
- 在优先级队列中,条目将保持已排序状态 (使用 heapq 模块) ,值最小的条目会先被提取

2.3.2 类方法
队列对象 (queue.Queue,queue.LifoQueue, queue.PriorityQueue) 提供以下公共方法。
| 方法 | 描述 |
| Queue.qsize() | 返回队列的大致大小。 |
| Queue.empty() | 如果队列为空,返回 True,否则返回 False。 |
| Queue.full() | 如果队列是满的,返回 True,否则返回 False。 |
| Queue.put(item, block=True, timeout=None) | 将 item 加入队列。 如果可选参数 block 为 True:(1)timeout 为 None (默认值) 时,会在必要时阻塞,直到有空闲槽位可用;(2)timeout 为正数时,将阻塞最多 timeout 秒,如果等待期间内始终没有可用的空闲槽位,引发 Full 异常。 如果可选参数 block 为 False:如果空闲槽位立即可用,则将条目加入队列;否则将引发 Full 异常(这种情况下timeout 将被忽略)。 |
| Queue.put_nowait(item) | 同 put(item, block=False) |
| Queue.get(block=True, timeout=None) | 从队列中移除并返回一个项目。 如果可选参数 block 为 True:(1)timeout 为 None (默认值) 时,会在必要时阻塞,直到项目可得到;(2)timeout 为正数时,将阻塞最多 timeout 秒,如果在这段时间内项目始终不能得到,将引发 Empty 异常。 如果可选参数 block 为 False:如果一个项目立即可得到,则返回一个项目;否则将引发 Empty 异常(这种情况下timeout 将被忽略)。 |
| Queue.get_nowait() | 同 get(block=False) |
| Queue.task_done() | 表示前面排队的任务已经被完成,已被队列的消费者线程使用。 使用 get() 方法获取队列中的任务,当获取到一个任务时,需要在任务完成后调用 task_done() 方法,使队列知道任务已经完成。 如果 join() 当前正在阻塞,在所有条目都被处理后,将解除阻塞(意味着每个 put() 进队列的条目的 task_done() 都被收到)。 |
| Queue.join() | 阻塞至队列中所有的元素都被接收和处理完毕。 当一个条目被添加到队列的时候,未完成任务的计数将会增加; 每当一个消费者线程调用 task_done() 来表明该条目已被提取且其上的所有工作已完成时,未完成计数将会减少。 当未完成计数降为零时, join() 将解除阻塞。 |
2.3.3 异常类

2.3.4 代码示例:queue.Queue
下面是一个应用 queue.Queue 的例子,可以尝试将代码中的 task_down 行注释掉,对比运行结果。
import queue
import threading
import time
import logging
def worker(q):
while True:
cur_item = q.get()
logging.info("Processing %s", cur_item)
time.sleep(1)
q.task_done() # 忘记调用 task_done() 导致异常
if __name__ == '__main__':
logging_format = "%(asctime)s.%(msecs)03d: %(message)s"
logging.basicConfig(format=logging_format, level=logging.INFO, datefmt="%H:%M:%S")
q = queue.Queue()
# 启动5个线程
for i in range(5):
t = threading.Thread(target=worker, args=(q,))
t.daemon = True
t.start()
# 向队列中添加10个任务
for item in range(10):
q.put(item)
# 等待所有任务完成
q.join()
print("All tasks are done.")返回结果:

如果注释掉 task_down 行,从队列中取走一个条目后,未调用 task_done() 方法,这个条目会一直被视为“未完成”的任务,队列中的未完成任务数量一直保持,从而导致程序一直等待,无法正常退出。返回结果如下:

2.4 标准库 concurrent.futures
待补充
3. Thread
3.1 创建
![]()
参数说明:

细节说明:
(1)对于 Thread 的 args 参数,列表或元组效果相同。

(2)参数daemon是布尔值,表示这个线程是否是守护线程。守护线程的含义是:程序终止前:对守护线程,会直接终止该线程;对非守护线程,会等待其运行结束。

如果一个程序正在运行守护线程,在程序退出时,该线程也会被杀死;如果运行的是非守护线程,那么该程序将在终止之前,会等待线程运行结束。当没有存活的非守护线程时,整个Python程序才会退出。
守护线程可视为在后台运行的线程,将其突然关闭不会造成问题。突然关闭一个线程时,它的资源(例如已经打开的文档,数据库事务等等)可能没有被正确释放,如果想让线程正常停止,需要将其设置为非守护模式并且使用合适的信号机制。
主线程不是一个守护线程,因此所有在主线程中创建的线程默认为 daemon = False。
关于daemon的更多细节,请参考下文代码示例 <3.3 代码示例:关于daemon、join()>。
3.2 类方法
| 方法 | 已弃用 | 描述 |
| start() | -- | 开始线程。 |
| run() | -- | 运行线程。 标准的 run() 方法会将 target 参数传递给该对象构造器的可调用对象发起调用,并附带从 args 和 kwargs 参数分别获取的位置和关键字参数。 |
| join(timeout=None) | -- | 等待,直到线程终结。 |
| name | getName() setName() | 直接以属性方式使用 |
| daemon | isDaemon() setDaemon() | 直接以属性方式使用 |
| is_alive() | -- | 从 run() 方法刚开始直到 run() 方法刚结束,这个方法返回 True 。模块函数 enumerate() 返回包含所有存活线程的列表。 |
| ident | -- | 线程的 “线程标识符”,如果线程尚未开始则为 None ,是个非零整数。 当一个线程退出而另外一个线程被创建,线程标识符会被复用。 |
| native_id | -- | 此线程的线程 ID,由 OS(内核)分配,是一个非负整数,或者如果线程还未启动则为 None。这个值可被用来在全系统范围内唯一地标识这个特定线程(直到线程终结,之后该值可能会被 OS 回收再利用)。 |
3.3 代码示例:关于daemon、join()
import logging
import threading
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
logging.info("Main : before creating thread")
x = threading.Thread(target=thread_function, args=(1,))
# x = threading.Thread(target=thread_function, args=(1,), daemon=True)
logging.info("Main : before running thread")
x.start()
logging.info("Main : wait for the thread to finish")
# x.join()
logging.info("Main : all done")上述代码涉及两个线程:主线程,通过 threading.Thread 定义的线程 x。
x采用默认设置(非守护线程)
运行结果:

将x设置为守护线程
x = threading.Thread(target=thread_function, args=(1,), daemon=True)对代码做一点小修改,定义 x 时,增加 deamon=True。运行结果:
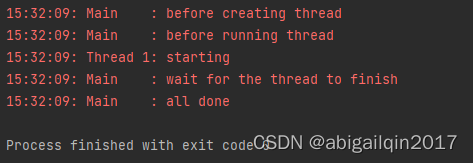
增加x.join()
保持守护线程的设置(deamon=True),并将 x.join() 行去掉注释。通过调用 .join(),使得主线程等待线程 x 运行结束。
如果使用 .join() 方法处理一个线程,无论该线程是守护线程还是非守护线程,该语句都将一直等待到线程运行结束。运行结果:

3.4 代码示例:线程池
(1)初级写法(略冗长)
import logging
import threading
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
threads = list()
for index in range(3):
logging.info("Main : create and start thread %d.", index)
x = threading.Thread(target=thread_function, args=(index,))
threads.append(x)
x.start()
for index, thread in enumerate(threads):
logging.info("Main : before joining thread %d.", index)
thread.join()
logging.info("Main : thread %d done", index)
(2)优化版(线程池)
from concurrent.futures import ThreadPoolExecutor
import logging
import threading
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
with ThreadPoolExecutor(max_workers=3) as executor:
executor.map(thread_function, range(3))
运行结果:

3.5 代码示例:返回线程运行结果
import logging
from concurrent.futures import ThreadPoolExecutor
import time
def func1(a, b):
for i in range(5):
logging.info('func1: No-%s', i)
time.sleep(0.5)
return a*b
def func2():
for i in range(5):
logging.info('func2: No-%s', i)
time.sleep(0.7)
if __name__ == '__main__':
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S")
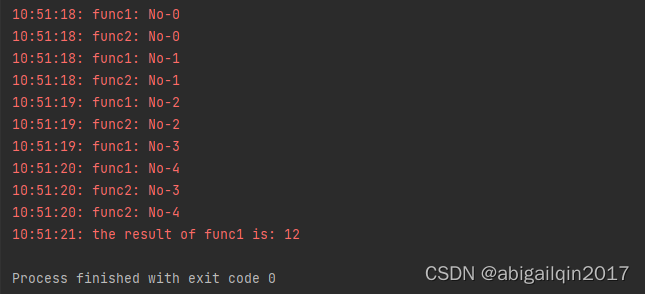
with ThreadPoolExecutor(max_workers=3) as executor:
f1 = executor.submit(func1, 3, 4)
executor.submit(func2)
logging.info('the result of func1 is: %s', f1.result())
运行结果:
4. Lock:一旦一个线程获得一个锁,随后尝试获得这个锁的线程会阻塞,直到锁被释放(任何线程都可以释放它)。
4.1 创建

- 锁对象处于 "锁定" 或者 "非锁定" 两种状态之一,默认为非锁定状态。
- 它有两个基本方法, acquire() 和 release()。
- 锁支持上下文管理器,在实际应用时,应尽量应用上下文管理器,以避免跳过 release()(锁定后一直没有没有释放锁)的异常情况。
4.2 类方法
| 方法 | 描述 |
| acquire(blocking=True, timeout=-1) | (1)参数 blocking 默认为True。 (2)在 blocking 为True的情况下,调用acquire()时:如果当前状态为“非锁定”,acquire 将状态改为锁定并立即返回;如果当前状态为“锁定”,acquire 将阻塞,直至任一线程调用 release 方法将其改为非锁定状态,状态转变为非锁定后,acquire 将状态重置为锁定并返回。 (3)在blocking 为False的情况下,调用 acquire() 将不会发生阻塞。 (4)blocking 为False时,不能指定timeout值;如果 blocking 为True,且参数 timeout 为正值的浮点数,只要不能获取到锁,最多阻塞timeout 指定的秒数。如果能获取锁,返回 True,如果超时已过,返回False;timeout 为-1时,表示无限等待。 |
| release() | (1)release() 只在锁定状态下调用,它将状态改为非锁定并立即返回。如果在未锁定的锁上发起调用,会引发 RunTimeError。 (2)该方法可以在任何线程中调用,不只是获得锁的线程。 |
| locked() | 当锁已被获取时,返回 True。 |
4.3 代码示例:关于竞争状态 race condition、Lock
锁Lock,以及下文的重入锁RLock,用于控制多个线程对共享资源的访问,解决数据竞争问题。先通过一个例子了解一下什么是数据竞争(或称为竞争状态 race condition)。
(1)竞争状态
在这个例子中,有两个线程在同时运行,它们的功能都是:从数据库中获取一个值,对其进行修改(在原来的基础上加1)并保存。最终期望的结果是,数据库的这个值在原来的基础上加2,但实际运行时发现,这个值最后仅增加1。
from concurrent.futures import ThreadPoolExecutor
import logging
import time
class FakeDatabase:
def __init__(self):
self.value = 0
def update(self, name):
logging.info("Thread %s: starting update", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.info("Thread %s: finishing update", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.update, index)
logging.info("Testing update. Ending value is %d.", database.value)
实际运行结果:增加1(期望当两个操作同时进行时,每个操作都发挥作用,即增加2)

运行过程说明



总结:竞争状态指的是在多线程或多进程编程中,多个线程或进程同时访问共享资源(例如内存、文件等)时可能出现的一种状态。当多个线程或进程同时尝试修改同一个共享资源时,由于它们之间的执行顺序是不确定的,可能会导致结果出现不一致或错误的情况。这种情况下,我们称这些线程或进程之间出现了竞争状态。为了避免竞争状态,我们需要使用同步机制,例如互斥锁、信号量等来控制对共享资源的访问。
(2)解决后(应用Lock)
import threading
from concurrent.futures import ThreadPoolExecutor
import logging
import time
class FakeDatabase:
def __init__(self):
self.value = 0
self._lock = threading.Lock() # 定义锁
def locked_update(self, name):
logging.info("Thread %s: starting update", name)
logging.debug("Thread %s about to lock", name)
with self._lock: # 上下文管理器,结束时自动释放锁
logging.debug("Thread %s has lock", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.debug("Thread %s about to release lock", name)
logging.debug("Thread %s after release", name)
logging.info("Thread %s: finishing update", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.DEBUG,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.locked_update, index)
logging.info("Testing update. Ending value is %d.", database.value)

5. RLock:可以被同一个线程多次获取。

细节说明:
- 在内部,重入锁的锁定/非锁定状态上附加了 "所属线程" 和 "递归等级" 的概念。一旦线程获得了重入锁,同一个线程再次获取它时,将不阻塞。
- acquire()/release() 对可以嵌套;只有最终 release()(最外面一对的release())将锁解开,才能让其他线程继续处理 acquire() 阻塞。
| 方法 | 描述 |
| acquire(blocking=True, timeout=-1) | 可以阻塞或非阻塞地获得锁。 |
| release() | 释放锁。这个方法可以在任何线程中调用,不单指获得锁的线程。 |
| locked() | 当锁被获取时,返回 True。 |
代码示例:RLock应用场景
RLock有什么使用场景呢,Stack Overflow有一个很棒的回答,提供了如下两种典型场景:
(1)某个类内部存在“方法嵌套”,期望在多线程环境下,从外部访问这个类时线程安全。
import concurrent.futures
import threading
import time
import logging
import random
class X1:
def __init__(self):
self.a = 1
self.b = 2
self.lock = threading.RLock() # 可以尝试更改为threading.Lock, 对比一下运行效果
def changeA(self):
with self.lock:
logging.info('{} acquire lock'.format(threading.current_thread().name))
self.a = self.a + 1
time.sleep(random.randint(0, 2))
self.a = self.a + 1
logging.info('{} release lock'.format(threading.current_thread().name))
def changeB(self):
with self.lock:
logging.info('{} acquire lock'.format(threading.current_thread().name))
self.b = self.b + self.a
logging.info('{} release lock'.format(threading.current_thread().name))
def changeAandB(self):
# you can use chanceA and changeB thread-safe!
with self.lock:
logging.info('{} acquire lock'.format(threading.current_thread().name))
self.a = self.a * 2
self.changeA() # a usual lock would block at here
self.changeB()
logging.info('{} release lock'.format(threading.current_thread().name))
class X2:
def __init__(self):
self.a = 1
self.b = 2
def changeA(self):
logging.info('{} start changeA'.format(threading.current_thread().name))
self.a = self.a + 1
time.sleep(random.randint(0, 2))
self.a = self.a + 1
logging.info('{} stop changeA'.format(threading.current_thread().name))
def changeB(self):
logging.info('{} start changeB'.format(threading.current_thread().name))
self.b = self.b + self.a
logging.info('{} stop changeB'.format(threading.current_thread().name))
def changeAandB(self):
logging.info('{} start changeAandB'.format(threading.current_thread().name))
self.a = self.a * 2
self.changeA()
self.changeB()
logging.info('{} stop changeAandB'.format(threading.current_thread().name))
if __name__ == '__main__':
logging_format = "%(asctime)s: %(message)s"
logging.basicConfig(format=logging_format, level=logging.INFO, datefmt="%H:%M:%S")
my_x = X1()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(my_x.changeA)
executor.submit(my_x.changeAandB)
logging.info('X1 instance a:{} b:{}'.format(my_x.a, my_x.b))
for i in range(3):
my_x = X2()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(my_x.changeA)
executor.submit(my_x.changeAandB)
logging.info('X2 instance NO{} a:{} b:{}'.format(i, my_x.a, my_x.b))
返回结果:
my_x为类X1()的实例:

my_x为类X2()的实例(运行两次,结果不同):
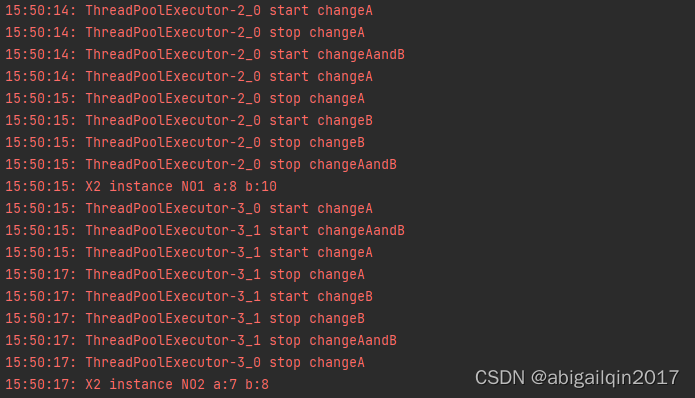
在上述例子中,定义了一个实例 my_x,并创建了两个线程,分别执行 changeA 和changeAandB。线程是共享进程内存的,这两个线程可能同时访问和修改 my_x,导致竞态条件或数据竞争(多个线程同时竞争同一资源,由于执行顺序不确定或者执行时间不同,导致访问冲突或数据最终结果不确定),存在线程不安全问题。因此,需要使用锁,当一个线程获得了锁,其他线程就不能再访问该锁保护的对象,直到该线程释放锁为止。从而保证多个线程对共享资源访问的互斥性。
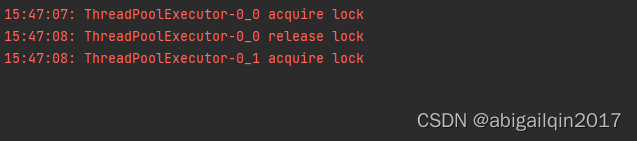
由于这个类存在方法嵌套,应用锁时,需要使用RLock,使用Lock会导致调用 changeAandB 时阻塞。如果将RLock改为Lock,返回结果如下(程序一直阻塞):
(2)递归场景
if __name__ == '__main__':
lock = threading.RLock()
def fibonacci(n):
with lock:
if n <= 1:
return n
else:
return (fibonacci(n - 1) + fibonacci(n - 2))
for i in range(10):
print(fibonacci(i))在上述递归函数,应当使用RLock而不能用Lock,上述代码将返回斐波那契数列前10个数:

其他:
(1)对于RLock,线程具有所有权,在给定的线程中,可以随时获得RLock,其他线程需要等待,直到该线程释放资源。对于Lock,函数调用具有所有权,其他函数调用必须等待,直到最后一个阻塞函数释放资源。
(2)在Python 3.2及更高版本中,RLock和Lock一样是用C语言实现的,RLock的性能成本几乎为零;在之前的版本,RLock是通过大量的Python代码来包装Lock实现的,会很慢。
(3)Lock可以从任何线程释放(不一定是获取它的线程),而RLock必须由获得它的同一个线程释放。
python - Is RLock a sensible default over Lock? - Stack Overflow
When and how to use Python's RLock - Stack Overflow
6. Event:一个线程发出事件信号,其他线程等待该信号。事件对象管理一个内部标识(初始时为 false),set() 方法可将其设置为true,clear() 方法可将其设置为 false,wait() 方法将进入阻塞直到此标识变为 true 。
6.1 创建

6.2 类方法
| 方法 | 描述 |
| set() | 将内部标识设置为 true 。 所有正在等待这个事件的线程将被唤醒,调用 wait() 方法的线程不会被被阻塞。 |
| is_set() | 当且仅当内部标识为 true 时返回 True。 |
| clear() | 将内部标识设置为 false 。 之后调用 wait() 方法的线程将会被阻塞,直到调用 set() 方法,将内部标识再次设置为 true 。 |
| wait(timeout=None) | 阻塞线程直到内部变量为 true 。如果调用时内部标识为 true,将立即返回。否则将阻塞线程,直到调用 set() 方法将标识设置为 true 或者发生超时(可选参数)。 timeout 参数值默认为None,可以是一个浮点数,代表操作的超时时间,以秒为单位(可以为小数)。 |
6.3 代码示例
下文 <11.3> 提供了一个应用 Event 对象的例子。
7. Condition:使一些线程暂停执行,直到某个条件变为真;同时使另外一些线程在条件变为真时,唤醒等待中的线程。
7.1 创建

说明:
- 条件变量总是与某锁对象相关联,锁对象可以通过传入获得,或者在缺省的情况下自动创建。
- 应用conditon的典型场景:有一些线程对某个状态的变化感兴趣,它们重复调用 wait() 方法,直到看到所期望的改变发生(或者使用 wait_for() 方法,条件检查自动化)。还有一些线程能够修改状态,它们将当前状态改变为等待者所期待的新状态后,调用 notify() 方法或者 notify_all() 方法通知等待的线程。
- 选择 notify() 还是 notify_all() ,取决于一次状态改变是只能被一个还是能被多个等待线程所用。
7.2 类方法
| 方法 | 描述 |
| acquire(*args) | 请求底层锁。此方法将调用底层锁的 acquire 方法, |
| release() | 释放底层锁。此方法将调用底层锁的 release 方法。 |
| 以下方法必须在持有锁的情况下才能调用。 | |
| wait(timeout=None) | 等待,直到收到通知,或发生超时。 (1)如果线程在没获得锁的情况下调用此方法,会引发 RuntimeError 异常。 (2)可以提供 timeout 参数(浮点数),代表操作的超时时间,以秒为单位,可以为小数。 (3)wait() 方法释放锁,然后阻塞,直到被其它线程通过调用 notify() 或 notify_all() 方法唤醒,但被唤醒的线程不会立即从它们的 wait() 方法调用中返回,而是在调用了 notify() 或 notify_all() 方法的线程最终放弃了锁的所有权后,wait() 方法重新获取锁,然后返回。 |
| wait_for(predicate, timeout=None) | 等待,直到条件计算为真。 (1)predicate 应该是一个可调用对象而且它的返回值可被解释为一个布尔值。 (2)可以提供 timeout 参数给出最大等待时间。 |
| notify(n=1) | 默认唤醒一个等待这个条件的线程。 (1)如果线程在没获得锁的情况下调用此方法,会引发 RuntimeError 异常。 (2)这个方法唤醒最多参数 n 个正在等待这个条件变量的线程,如果没有线程在等待,这是一个空操作。 (3)notify() 不释放锁,需要其调用者(调用它的线程)释放锁。被唤醒的线程重新获得锁后,才能恢复到它调用的wait()。 |
| notify_all() | 唤醒所有正在等待这个条件的线程。 (1)如果线程在没获得锁的情况下调用此方法,会引发 RuntimeError 异常 (2)这个方法行为与 notify() 相似,但并不只唤醒单一线程,而是唤醒所有等待线程。 |
7.3 代码示例
待补充
8. Semaphore:信号量是一个计数器,用于控制同时访问共享资源的线程数量。当一个线程想要访问共享资源时,它必须先获得信号量,如果信号量的计数器大于0,那么线程就可以继续执行访问共享资源的代码,同时信号量的计数器会减1;如果信号量的计数器为0,那么线程就必须等待,直到有其他线程释放了信号量。
8.1 创建

The counting is atomic. This means that there is a guarantee that the operating system will not swap out the thread in the middle of incrementing or decrementing the counter.
8.2 类方法
| 方法 | 描述 |
| acquire(blocking=True, timeout=None) | 获取一个信号量。 细节说明: (1)默认情况下调用时(blocking=True, timeout=None): 如果内部计数器的值大于零,则将其减 1 并立即返回 True。 如果内部计数器的值为零,则将会阻塞,直到被对 release() 的调用唤醒。 一旦被唤醒(并且计数器的值大于 0),将计数器减 1 并返回 True。 每次调用 release() 默认唤醒一个线程,线程被唤醒的次序是不可确定的。 (2)当 blocking 设置为 False 时调用,不会阻塞。 (3)如果参数 timeout 不为 None,发起调用后最多阻塞 timeout 秒,如果在此时段内未能成功获取请求,返回 False,否则返回 True。 |
| release(n=1) | 释放一个信号量,将内部计数器的值增加 n(可一次性释放多个等待线程),唤醒等待中的 n 个线程。 |
信号量对象支持 context management protocol。
8.3 代码示例
在下面这个例子中,限制能同时访问资源的数量为 3。
import logging
import threading
from random import random
from concurrent.futures import ThreadPoolExecutor
import time
sema = threading.Semaphore(3)
def foo(tid):
with sema:
logging.info('{} {} acquire sema'.format(tid, threading.current_thread().name))
wait_time = random() * 3
time.sleep(wait_time)
logging.info('**{}** {} release sema **'.format(tid, threading.current_thread().name))
if __name__ == '__main__':
logging_format = "%(asctime)s: %(message)s"
logging.basicConfig(format=logging_format, level=logging.INFO, datefmt="%H:%M:%S")
with ThreadPoolExecutor(max_workers=3) as executor:
for i in range(5):
executor.submit(foo, i)
返回结果:

9. Timer:定时器对象用于在指定的时间后执行某个函数。
9.1 创建、类方法

9.2 代码示例
import threading
import logging
if __name__ == '__main__':
logging_format = "%(asctime)s.%(msecs)03d: %(message)s"
logging.basicConfig(format=logging_format, level=logging.INFO, datefmt="%H:%M:%S")
def func():
logging.info("Hello, World!")
logging.info('Start...')
timer = threading.Timer(5.0, func)
timer.start()
返回结果:

10. Barrier:让多个线程在某个点上等待,直到所有线程都到达这个点后再继续执行。
10.1 创建

上述定义将创建一个需要 parties 个线程的栅栏对象。如果 action 参数可调用,在所有线程被释放时,会在其中一个线程中自动调用。 timeout 是默认的超时时间。
10.2 类方法
| 方法 | 描述 |
| wait(timeout=None) | 当栅栏中所有线程都已经调用了这个函数,它们将同时被释放。 如果提供了 timeout 参数,这里的 timeout 参数优先于创建栅栏对象时提供的 timeout 参数。 函数返回值是一个整数,取值范围在0到 parties - 1,在每个线程中的返回值不相同。可用于从所有线程中选择唯一的一个线程执行一些特别的工作。 如果发生了超时,栅栏对象将进入破损态。 |
| reset() | 重置栅栏为默认的初始态。 重置栅栏时仍有线程等待释放,这些线程将会收到 BrokenBarrierError 异常。 |
| abort() | 使栅栏处于损坏状态。 任何现有以及未来对 wait() 的调用均失败,并引发 BrokenBarrierError 异常。 |
| parties | 冲出栅栏所需要的线程数量。 |
| n_waiting | 当前时刻正在栅栏中阻塞的线程数量。 |
| broken | 布尔值,值为 True 表示栅栏为破损态。 |
10.3 异常类

10.4 代码示例
import threading
import logging
import time
from concurrent.futures import ThreadPoolExecutor
def func(barrier, worker_id):
wait_time = 2*int(worker_id)
logging.info("{} {} wait_time: {}".format(worker_id, threading.current_thread().name, wait_time))
time.sleep(wait_time)
try:
logging.info("worker{} in barrier".format(worker_id))
b_id = barrier.wait()
logging.info("worker{} barrier id: {}".format(worker_id, b_id))
except threading.BrokenBarrierError:
logging.info("worker{}; barrier is broken: {} {} {}".format(
worker_id, barrier.broken, barrier.n_waiting, barrier.parties))
barrier.reset()
logging.info("worker{} finished".format(worker_id))
if __name__ == '__main__':
logging_format = "%(asctime)s.%(msecs)03d: %(message)s"
logging.basicConfig(format=logging_format, level=logging.INFO, datefmt="%H:%M:%S")
barrier = threading.Barrier(3, action=lambda: logging.info('ALL Release'), timeout=30)
with ThreadPoolExecutor(max_workers=6) as executor:
for i in range(6):
executor.submit(func, barrier, i)
返回结果:
可以注意到,barrier 是可以反复使用的:0/1/2进入 -> 释放 -> 3/4/5进入 -> 释放。

如果把 barrier 定义中的 timeout 参数改小一点,比如设置为3,返回结果为:

下文 <11.4> 提供了一个应用 Barrier 对象的例子。
11. 应用:生产者消费者问题
生产者消费者问题(Producer-consumer problem),也称有限缓冲问题,是一个经典的并发问题。在软件开发的过程中,经常碰到这样的场景:某些模块负责生产数据并放到缓冲区,另外一些模块从缓冲区读取并处理这些数据。产生数据的模块称为生产者,而处理数据的模块称为消费者。
假设生产者和消费者分别是两个线程,如果生产者生产数据过快,消费者消耗数据的速度很慢,就会出现供大于求的现象;若消费者消耗数据的速度过快,而生产者跟不上消耗的速度,就会出现供不应求的现象。为了保证生产者和消费者之间的正确协作和同步,避免了数据竞争和死锁等并发问题,生产者线程和消费者线程需要遵守以下规则:1. 如果缓冲区已满,则生产者线程必须等待,直到有空闲位置(供大于求时,生产者应等待消费者消耗数据再继续生产);2. 如果缓冲区为空,则消费者线程必须等待,直到有数据可用(供不应求时,消费者需要等待生产者);3. 生产者线程将数据放入缓冲区后,必须通知消费者线程;4. 消费者线程从缓冲区中取出数据后,必须通知生产者线程。
11.1 问题描述(一个生产者和一个消费者)
假设有一个程序,用于从网络侧(Network)读取消息并将其写入数据库(Database)。这个程序可视为由生产者和消费者两部分组成,生产者负责监听并接收由网络侧传入的消息,这些信息可能以爆发性的方式发送;消费者负责将数据写入数据库,通常情况下,数据库访问速度足以跟上消息的平均速度,但当大量信息传入时,这个写入速度是不够的。
在下述示例中,对这个程序中 Network 和 Database 部分做了简化处理:从 Network 读取数据的过程简化为获取一个(1~100] 的随机数,将数据存入 Database 过程简化为 Log 打印获取的数据。
11.2 初级(定义一个只能容纳1个数据的管道,生产者放入数据后,消费者取数据,依次进行)
思路:先定义一个管道 Pipeline,管道中含有一个数据 self.message(初始值为0);两个锁,self.producer_lock(指示生产者能否写入新数据,初始状态为非锁定)和 self.consumer_lock(指示消费者能否获取管道数据,初始状态为锁定状态,因为初始场景下管道中没有数据,不应读取其中数据);两个方法 get_message() (用于获取管道中的数据,即 self.message)和 set_message() (用于将外部的数据放入管道,即将函数参数message的值赋给self.message)。
为了保证存取数据的过程不发生竞争,对于 get_message() 方法,在获取数据前,需要获取锁self.consumer_lock,获取到数据后,释放锁 self.producer_lock,允许管道中数据改变;对于 set_message() 方法,在更新管道数据前,需获取 self.producer_lock,更新完成后,释放self.consumer_lock,相当于释放一个管道数据有变化的信号,允许消费者获取管道数据。
producer 线程:调用 set_message() 方法将外部数据放入管道。consumer 线程:调用get_message() 方法从管道中获取数据。
(1)代码
import random
import logging
import threading
from concurrent.futures import ThreadPoolExecutor
SENTINEL = object()
class Pipeline:
"""
Class to allow a single element pipeline between producer and consumer.
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
logging.debug("%s:about to acquire getlock", name)
self.consumer_lock.acquire()
logging.debug("%s:have getlock", name)
message = self.message
logging.debug("%s:about to release setlock", name)
self.producer_lock.release()
logging.debug("%s:setlock released", name)
return message
def set_message(self, message, name):
logging.debug("%s:about to acquire setlock", name)
self.producer_lock.acquire()
logging.debug("%s:have setlock", name)
self.message = message
logging.debug("%s:about to release getlock", name)
self.consumer_lock.release()
logging.debug("%s:getlock released", name)
def producer(pipeline):
"""Pretend we're getting a message from the network."""
for index in range(10):
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
pipeline.set_message(message, "Producer")
# Send a sentinel message to tell consumer we're done
pipeline.set_message(SENTINEL, "Producer")
def consumer(pipeline):
"""Pretend we're saving a number in the database."""
message = 0
while message is not SENTINEL:
message = pipeline.get_message("Consumer")
if message is not SENTINEL:
logging.info("Consumer storing message: %s", message)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.DEBUG,
datefmt="%H:%M:%S")
pipeline = Pipeline()
with ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline)
executor.submit(consumer, pipeline)
返回结果:
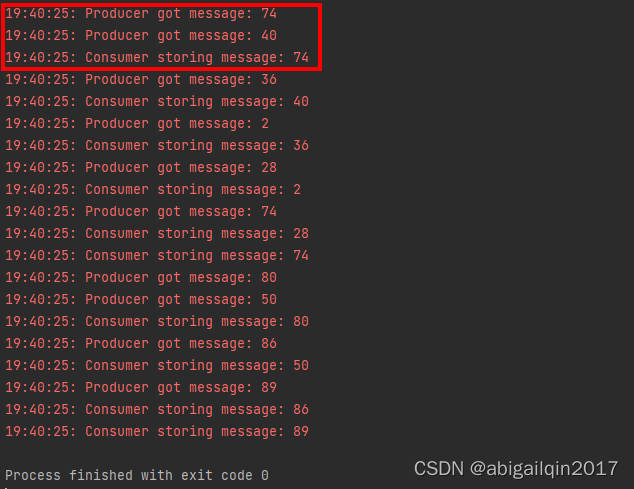
但是,当前这种方式,管道中只能有一个值。当 Producer 收到大量消息时,将无处安放这些信息。为了更好的解决这一问题,需要引入Queue。
11.3 进阶(应用Queue)
思路:Python 的标准库中有一个 queue 模块,实现了多生产者、多消费者队列。该模块有一个Queue 类,Queue 类适用于 threaded programming,其内部已经实现了所有所需的关于锁的语句,能够将消息安全地在多线程间交换。为此,考虑将管道数据的数据结构从原来的一个数值变量(受Lock保护的),改为 Queue,让管道中容纳更多的值,使得生产者和消费者都能处理更多数据。
关于 queue.Queue 的更多细节,请参考 <2.3 模块queue>。另外,下述代码应用了事件对象(参考<6. Event>),用于使程序停止运行(消费者和生产者都停止操作)。
(1)代码(基于Queue)
import random
import logging
import threading
import queue
import time
import concurrent.futures
class Pipeline(queue.Queue):
def __init__(self):
super().__init__(maxsize=10)
def get_message(self, name):
logging.debug("%s:about to get from queue", name)
value = self.get()
logging.debug("%s:got %d from queue", name, value)
return value
def set_message(self, value, name):
logging.debug("%s:about to add %d to queue", name, value)
self.put(value)
logging.debug("%s:added %d to queue", name, value)
def producer(pipeline, event):
"""Pretend we're getting a number from the network."""
while not event.is_set():
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
pipeline.set_message(message, "Producer")
logging.info("Producer received EXIT event. Exiting")
def consumer(pipeline, event):
"""Pretend we're saving a number in the database."""
while not event.is_set() or not pipeline.empty():
message = pipeline.get_message("Consumer")
logging.info(
"Consumer storing message: %s (queue size=%s)",
message,
pipeline.qsize(),
)
logging.info("Consumer received EXIT event. Exiting")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
# logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
time.sleep(0.1)
logging.info("Main: about to set event")
event.set()
(2)进一步简化后的代码
上述代码中,Pipline 的两个主要方法 get_message() 和 put_message() 等同于 Queue.get() 和Queue.put() ,因而可以直接将 Pipline 定义为 queue.Queue。
另外,这里还做了一点小小的改动,下述代码的含义是:生产者保持生产状态,直到收到一个信号后停止生产,向管道存入一个最后一个数据:None;消费者保持取数据,直到取到的数据是None,停止运行(将管道内的数据全部取出)。
import concurrent.futures
import logging
import queue
import random
import threading
import time
def producer(buffer_queue, stop_event):
"""Pretend we're getting a number from the network."""
while not stop_event.is_set():
message = random.randint(1, 101)
logging.info("Producer put message: %s", message)
buffer_queue.put(message)
buffer_queue.put(None)
logging.info("Producer received event. Exiting")
def consumer(buffer_queue):
"""Pretend we're saving a number in the database."""
while True:
message = buffer_queue.get()
if message is None:
break
logging.info(
"Consumer storing message: %s (size=%d)", message, buffer_queue.qsize()
)
logging.info("Consumer received event. Exiting")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
pipeline = queue.Queue(maxsize=10)
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline)
time.sleep(1)
logging.info("Main: about to set event")
event.set()
11.4 多个生产者和一个消费者
当有多个生产者和一个消费者时,一个关键的问题是:如何向消费者发出信号,表明不再需要继续执行任务。
如果每个生产者都在任务结束时,向队列发送一个终止信号,那么消费者在收到第一个信号时,就会停止运行,但是,生产者们通常不会在同一时刻全部完成任务,消费者线程过早停止,会导致队列中有条目被遗留,未能得到处理。
针对这个场景,可以考虑应用 threading.Barrier(参考<10. Barrier>),每个生产者在其任务结束后,到达一个“关卡”,进入等待,直到所有生产者都到达了这个“关卡”,然后统一将向消费者发送一个信号,表明生产任务已结束,后续将不再有内容加入到队列中。
import concurrent.futures
import logging
import queue
import random
import threading
import time
def producer(buffer_queue, stop_event, barrier, producer_id):
"""Pretend we're getting a number from the network."""
while not stop_event.is_set():
message = random.randint(1, 101)
logging.info("Producer ({}) put message: {}".format(producer_id, message))
buffer_queue.put(message)
barrier.wait()
logging.info("Producer received event. Exiting ({})".format(threading.current_thread().name))
def consumer(buffer_queue):
"""Pretend we're saving a number in the database."""
while True:
message = buffer_queue.get()
if message is None:
break
logging.info(
"Consumer storing message: %s (size=%d)", message, buffer_queue.qsize()
)
logging.info("Consumer received event. Exiting")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
n_producer = 3
pipeline = queue.Queue(maxsize=10)
barrier = threading.Barrier(parties=n_producer, action=lambda: pipeline.put(None))
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
for producer_id in range(3):
executor.submit(producer, pipeline, event, barrier, producer_id)
executor.submit(consumer, pipeline)
time.sleep(0.1)
logging.info("Main: about to set event")
event.set()
11.5 一个生产者和多个消费者
当有一个生产者和多个消费者时,一个关键的问题是:生产者如何通知每一个消费者,生产活动结束,队列中不会再添加新内容。如果仍采用一个生产者和一个消费者的处理方式,生产者在任务结束时,向队列添加一个终止信号None,将只能使一个消费者停止运行,后续的消费者将阻塞,等待队列添加新条目。
一种解决方法是:消费者在检查到终止信号 None 后,重新将这个信号放回队列,然后再退出,后续的消费者就依然能收到这个信号。在生产者和消费者线程都结束后,队列中还会留存一个 None,可以在程序最后去掉这个值。
import concurrent.futures
import logging
import queue
import random
import threading
import time
def producer(buffer_queue, event):
"""Pretend we're getting a number from the network."""
while not event.is_set():
message = random.randint(1, 101)
logging.info("Producer put message: %s", message)
buffer_queue.put(message)
buffer_queue.put(None)
logging.info("Producer received event. Exiting")
def consumer(buffer_queue):
"""Pretend we're saving a number in the database."""
while True:
message = buffer_queue.get()
if message is None:
buffer_queue.put(message)
break
logging.info(
"Consumer storing message: %s (size=%d)", message, buffer_queue.qsize()
)
logging.info("Consumer received event. Exiting")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
pipeline = queue.Queue(maxsize=10)
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
executor.submit(producer, pipeline, event)
for i in range(3):
executor.submit(consumer, pipeline)
time.sleep(0.01)
logging.info("Main: about to set event")
event.set()
logging.info(pipeline.qsize())
pipeline.get()
logging.info(pipeline.qsize())
返回结果:

还有一种解决方法是:使用事件 Event 对象。生产者在任务结束时设置事件,所有消费者在每次迭代时检查事件状态。不过存在一种可能:消费者在判断事件状态时,事件尚未发生,之后事件发生变化,队列为空,此消费者将一直阻塞,等待新项目。因此,消费者在调用 get() 时,需要配置 timeout 以便退出阻塞状态。
import concurrent.futures
import logging
import queue
import random
import threading
import time
producer_end_event = threading.Event()
def producer(buffer_queue, stop_event, producer_id):
"""Pretend we're getting a number from the network."""
while not stop_event.is_set():
message = random.randint(1, 101)
logging.info("Producer ({}) put message: {}".format(producer_id, message))
buffer_queue.put(message)
producer_end_event.set()
logging.info("Producer received event. Exiting ({})".format(threading.current_thread().name))
def consumer(buffer_queue, consumer_id):
"""Pretend we're saving a number in the database."""
while True:
if producer_end_event.is_set() and buffer_queue.qsize() == 0:
logging.info("Consumer ({}) find stop event".format(consumer_id))
break
else:
try:
message = buffer_queue.get(timeout=10)
logging.info("Consumer ({}) storing message: {} (qsize={})".format(
consumer_id, message, buffer_queue.qsize()))
except queue.Empty:
logging.info("Consumer ({}) timeout".format(consumer_id))
logging.info("Consumer received event. Exiting {}".format(threading.current_thread().name))
if __name__ == "__main__":
format = "%(asctime)s.%(msecs)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
pipeline = queue.Queue(maxsize=10)
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
for consumer_id in range(3):
executor.submit(consumer, pipeline, consumer_id)
executor.submit(producer, pipeline, event, 0)
time.sleep(0.01)
logging.info("Main: about to set event")
event.set()
返回结果:
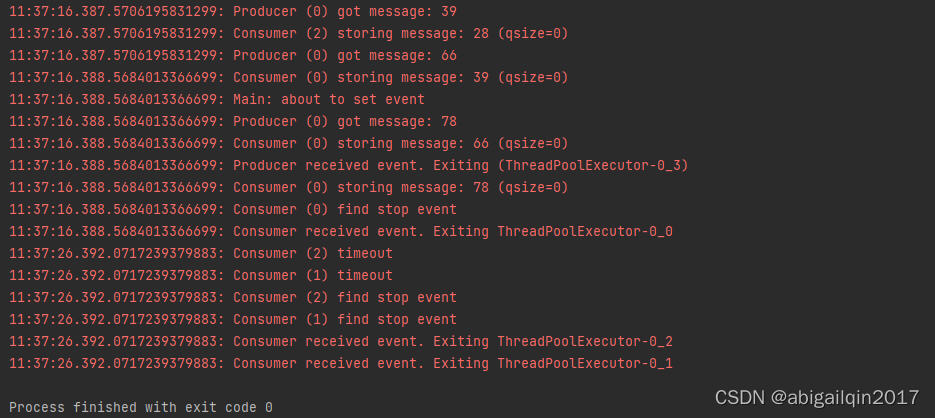
11.6 多个生产者和多个消费者
基于上述尝试,多个生产者和多个消费者场景的实现是容易的,代码如下:
import concurrent.futures
import logging
import queue
import random
import threading
import time
def producer(buffer_queue, stop_event, barrier, producer_id):
"""Pretend we're getting a number from the network."""
while not stop_event.is_set():
message = random.randint(1, 101)
logging.info("Producer ({}) put message: {}".format(producer_id, message))
buffer_queue.put(message)
barrier.wait()
logging.info("Producer received event. Exiting ({})".format(threading.current_thread().name))
def consumer(buffer_queue, consumer_id):
"""Pretend we're saving a number in the database."""
while True:
message = buffer_queue.get()
if message is None:
buffer_queue.put(message)
break
logging.info(
"Consumer ({}) storing message: {} (size={})".format(consumer_id, message, buffer_queue.qsize())
)
logging.info("Consumer received event. Exiting ({})".format(threading.current_thread().name))
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
n_producer = 3
pipeline = queue.Queue(maxsize=10)
barrier = threading.Barrier(parties=n_producer, action=lambda: pipeline.put(None))
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=6) as executor:
for producer_id in range(3):
executor.submit(producer, pipeline, event, barrier, producer_id)
for consumer_id in range(3):
executor.submit(consumer, pipeline, consumer_id)
time.sleep(0.1)
logging.info("Main: about to set event")
event.set()
logging.info(pipeline.qsize())
其他
python 中,如果队列已满,queue.Queue 的 put() 方法会保持等待,直到队列有空闲位置;如果队列为空,get()方法会保持等待,直到队列有内容。因此,使用 queue 可以方便地实现生产者消费者模型,而不必使用 Condition 进行判断。
12. 参考链接
一文搞明白Python多线程编程:threading库-CSDN博客
Thread Producer-Consumer Pattern in Python - Super Fast Python
















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









