







12 分钟阅读
本文链接: https://blog.openacid.com/algo/slimarray/

场景和问题
在时序数据库, 或列存储为基础的系统中, 很常见的形式就是存储一个整数数组, 例如 slim 这个项目按天统计的 star 数:
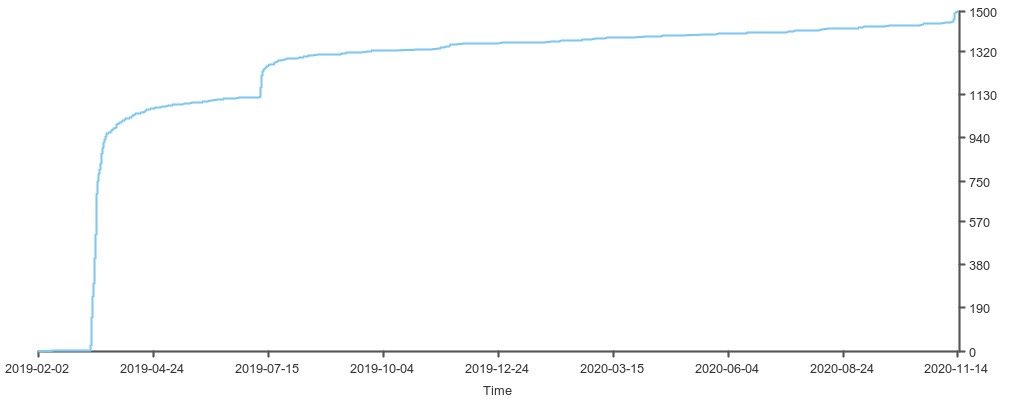
这类数据有有很明显的统一的变化趋势, 对这类数据的存储, 我们可以利用数据分布的特点, 将整体数据的大小压缩到几分之一. 这就是 slimarray 要做的事情.
使用 slimarray, 可以将数据容量减小到gzip差不多的大小, 同时还能允许直接访问这些数据! 测试中我们选择了2组随机数, 以及现实中的2份数据, 一个ipv4的数据库, 一个 slim 的star变化数据, 服用 slimarray 后效果如下:
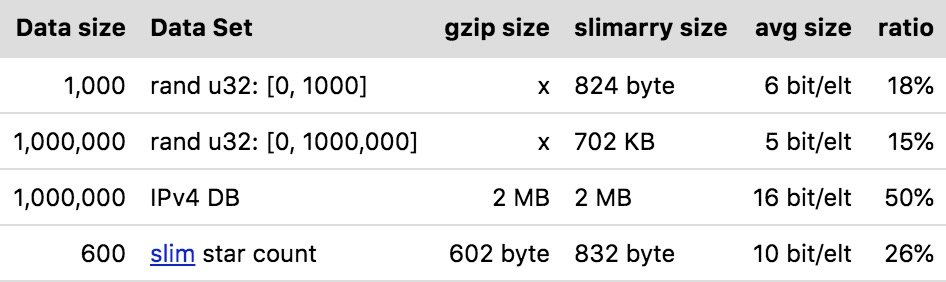
在达到gzip同等压缩率的前提下, 构建 slimarray 和 访问的性能也非常高:
- 构建 slimarray 时, 平均每秒可压缩 6百万 个数组元素;
- 读取一个数组元素平均花费 7 ns/op.
本文手把手的介绍 slimarray 的原理, 实现:
初步想法: 前缀压缩
假设我们有一个包含4个元素的uint32
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2683
2683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









