







链表
单链表
基础结构
单链表是一种最基础的链表结构,它由一个个链表节点构成,每个链表的节点分为两个部分data和link。如图所示

其中data保存着用户数据,而link保存这一个指针,用来指向下一个链表的节点。一个线性表如果用链表来存储的话,结构大概是这样的。

定义
private static class Node<E> {
E e;
Node<E> next;
Node(E e, Node<E> next) {
this.e = e;
this.next = next;
}
}
插入操作
单链表的插入可以分为三种情况讨论:
- 从头部插入

/**
* 向链表头部添加元素 O(1)
*
* @param e e
*/
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> newNode = new Node<>(e, first);
first = newNode;
if (null == last) {
last = newNode;
}
size++;
}
- 从中间插入

/**
* 向指定位置添加元素 O(N)
*
* @param index index
* @param e e
*/
public void add(int index, E e) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("index invalid");
}
if (index == 0) {
linkFirst(e);
} else if (index == size) {
linkLast(e);
} else {
linkAfter(index, e);
}
}
private void linkAfter(int index, E e) {
Node<E> helpNode = first;
for (int i = 0; i < index - 1; i++) {
helpNode = helpNode.next;
}
helpNode.next = new Node(e, helpNode.next);
}
- 从尾部插入

/**
* 向链表中添加元素,默认向尾部添加O(1)
*
* @param e e
*/
public void add(E e) {
linkLast(e);
}
private void linkLast(E e) {
final Node<E> currNode = last;
final Node<E> newNode = new Node<>(e, null);
last = newNode;
if (null == first) {
first = newNode;
} else {
currNode.next = newNode;
}
size++;
}
结合以上分析和代码可以看出单链表插入操作的时间复杂度也是与插入位置有关的。
- 如果是头插法,那么时间复杂度是O(1)
- 如果是尾插法,那么时间复杂度也是O(1)
- 如果想插入到指定位置,那么就需要遍历链表先找到插入点,整个时间复杂度就是O(N)了
删除操作
链表的删除操作也可以分为三种情况讨论
- 删除链表的中间节点

删除中间节点,只要找到待删除节点的前驱节点,然后暂时保存待删除节点,让前驱节点的指针指向待删除节点的后继节点,最后将待删除节点的指针指向NULL。方便垃圾回收。
- 删除链表的头结点
删除链表的头结点也是类似的,但是有一个问题,如果是中间节点尚且可以找到这个前驱节点,那如果是头结点怎么办呢?操作起来不太方便啊。所以大佬们给我们设立了一个虚拟头结点,也叫哑结点。这个节点不保存数据,只是用来做一个指向,指向链表的头部,这样链表真正保存数据的节点就是从第二个节点开始的,那么我们删除头结点的方式是不是就变成了上面删除中间节点的一般情形呢?

- 删除尾节点
在单链表中,因为只能根据当前节点找到后继节点,而不能找到前驱节点,因此删除尾结点的情况也可以看成删除中间节点的一般情况。时间复杂度就变成了最坏的情况O(N)。
下面我们用代码来实现。这里我们用了一个辅助的fisrt节点指向头,last节点指向尾,没有用虚拟头结点。
/**
* 删除第一个元素
*
* @return
*/
public E removeFirst() {
if (null == first) {
throw new NoSuchElementException("List is empty");
}
return unlinkFirst();
}
private E unlinkFirst() {
final Node<E> helpNode = first;
E e = helpNode.e;
first = helpNode.next;
if (null == first) {
last = null;
}
helpNode.next = null;
helpNode.e = null;
size--;
return e;
}
/**
* 删除最后一个元素
*
* @return
*/
public E removeLast() {
return unlink(size - 2);
}
/**
* 删除指定位置的元素
*
* @param index
* @return
*/
public E remove(int index) {
return unlink(index - 2);
}
private E unlink(int index) {
checkIndex(index);
Node<E> node = first;
for (int i = 0; i < index; i++) {
node = node.next;
}
Node<E> deleteNode = node.next;
E deleteElement = deleteNode.e;
node.next = deleteNode.next;
deleteNode.next = null;
deleteNode.e = null;
size--;
return deleteElement;
}
/**
* 删除指定元素
*
* @param e
* @return
*/
public boolean remove(E e) {
return removeElement(e);
}
public boolean removeElement(E e) {
if (first != null && first.e == e) {
removeFirst();
return true;
} else {
Node<E> helpNode = first;
while (helpNode != null && helpNode.next != null) {
if (e.equals(helpNode.next.e)) {
break;
}
helpNode = helpNode.next;
}
if (null != helpNode && null != helpNode.next) {
Node<E> deleteNode = helpNode.next;
if (deleteNode.e == last.e) {
last = helpNode;
}
helpNode.next = deleteNode.next;
deleteNode.next = null;
deleteNode.e = null;
size--;
return true;
}
return false;
}
}
结合上面图例分析和代码,我们可以看出单链表的删除时间复杂度也是与删除元素的位置有关的
- 如果是删除头结点,那么时间复杂度就是O(1)
- 如果是删除尾结点或者中间节点,总得先找到待删除的位置,那么时间复杂度就是O(N)
查找操作
查找元素
/**
* 查找元素
*
* @param index index
* @return E e
*/
public E get(int index) {
checkIndex(index);
Node<E> currNode = first;
for (int i = 0; i < index; i++) {
currNode = currNode.next;
}
return currNode.e;
}
/**
* 获取最后一个元素
*
* @return E e
*/
public E getLast() {
return null == last ? null : last.e;
}
/**
* 获取第一个元素
*
* @return E e
*/
public E getFirst() {
return null == first ? null : first.e;;
}
/**
* 判断链表是否包含指定元素
*
* @param e
* @return
*/
public boolean contains(E e) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.e == e) {
return true;
}
}
return false;
}
综上,查询的时间复杂度普遍情况也是O(N),最好情况是获取头结点和尾结点,时间复杂度是O(1)。
双向链表
如上所示,可以看出单向链表的可以根据当前节点直接找到它的后继节点,但是要是我们想找前驱节点可就麻烦了啊。。于是为了解决这个问题就有了双向链表这个概念。双向链表中每个节点不仅有数据、有指向下一个节点的指针,还维护了一个指向前一个节点的指针,这样就可以很方便的访问一个节点的前驱节点和后继节点。

c语言实现
双向链表的实现和单链表的实现基本一致,java.util.LinkedList就是采用这种实现,可以参考。代码可以简单参考下文LRU缓存淘汰算法。这里给大家提供一个C语言版本的实现(参考自redis源码中adlist的实现):
#ifndef __ADLIST_H__
#define __ADLIST_H__
/*
* 双端链表节点
*/
typedef struct listNode {
// 前驱节点
struct listNode* prev;
// 后继节点
struct listNode* next;
// 节点的值
void* value;
} listNode;
/*
* 双端链表迭代器
*/
typedef struct listIter {
// 当前迭代节点
listNode* next;
// 迭代方向
int direction;
} listIter;
typedef struct list {
listNode* head;
listNode* tail;
unsigned long len;
} list;
// 从表头向表尾进行迭代
#define AL_START_HEAD 0
// 从表尾到表头进行迭代
#define AL_START_TAIL 1
#endif
#include <stdio.h>
#include <stdlib.h>
#include "adlist.h"
/*
* 创建一个新的链表
*
* 创建成功返回链表,失败返回 NULL 。
*
* T = O(1)
*/
list* listCreate() {
struct list* list;
list = malloc(sizeof(struct list));
if (list == NULL) return NULL;
list->head = list->tail = NULL;
list->len = 0;
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list;
}
/*
* 头插法
*
* T = O(1)
*/
list* listAddNodeHead(list* list, void* value) {
listNode* node;
node = malloc(sizeof(struct listNode));
if (node == NULL) return NULL;
node->value = value;
if (list->len == 0) {
list->head = node;
list->tail = node;
node->prev = NULL;
node->next = NULL;
} else {
node->prev = NULL;
node->next = list->head;
list->head->prev = node;
list->head = node;
}
list->len++;
return list;
}
/*
* 尾插法
*
* T = O(1)
*/
list* listAddNodeTail(list* list, void* value) {
listNode* node;
node = malloc(sizeof(struct listNode));
if (node == NULL) return NULL;
node->value = value;
if (list->len == 0) {
list->head = node;
list->tail = node;
node->prev = NULL;
node->next = NULL;
} else {
node->prev = list->tail;
node->next = NULL;
list->tail->next = node;
list->tail = node;
}
list->len++;
return list;
}
/*
* 插入到 old_node 的之前或之后
*
* 如果 after 为 0 ,将新节点插入到 old_node 之前。
* 如果 after 为 1 ,将新节点插入到 old_node 之后。
*
* T = O(1)
*/
list* listInsertNode(list *list, listNode *old_node, void *value, int after) {
listNode* node;
node = malloc(sizeof(struct listNode));
if (node == NULL) return NULL;
node->value = value;
if (after) {
node->prev = old_node;
node->next = old_node->next;
old_node->next = node;
if (list->tail == old_node) {
list->tail = node;
}
} else {
node->next = old_node;
node->prev = old_node->prev;
if (list->head == old_node) {
list->head = node;
}
}
// 将old_node的prev指向node
if (node->prev != NULL) {
node->prev->next = node;
}
// 将old_node的next指向node
if (node->next !=NULL) {
node->next->prev = node;
}
list->len++;
return list;
}
/*
* 从链表 list 中删除给定节点 node
*
* 对节点私有值(private value of the node)的释放工作由调用者进行。
*
* T = O(1)
*/
void listDelNode(list *list, listNode *node) {
if (node->prev != NULL) {
node->prev->next = node->next;
} else {
list->head = node->next;
}
if (node->next != NULL) {
node->next->prev = node->prev;
} else {
list->tail = node->prev;
}
free(node);
list->len--;
}
/*
* 为给定链表创建一个迭代器
*
* T = O(1)
*/
listIter *listGetIterator(list *list, int direction) {
listIter* iter;
iter = malloc(sizeof(struct listIter));
if (iter == NULL) return NULL;
if (direction == AL_START_HEAD) {
iter->next = list->head;
} else {
iter->next = list->tail;
}
iter->direction = direction;
return iter;
}
/*
* 将迭代器的方向设置为 AL_START_HEAD ,
* 并将迭代指针重新指向表头节点。
*
* T = O(1)
*/
void listRewind(list *list, listIter *li) {
li->next = list->head;
li->direction = AL_START_HEAD;
}
/*
* 将迭代器的方向设置为 AL_START_TAIL ,
* 并将迭代指针重新指向表头节点。
*
* T = O(1)
*/
void listRewindTail(list *list, listIter *li) {
li->next = list->tail;
li->direction = AL_START_TAIL;
}
/**
* 释放迭代器
*/
void listReleaseIter(listIter *li) {
free(li);
}
/**
* 返回迭代器当前所指向的节点。
*/
listNode* listNext(listIter *iter) {
listNode* current = iter->next;
if (current != NULL) {
if (AL_START_HEAD == iter->direction) {
iter->next = current->next;
} else {
iter->next = current->prev;
}
}
return current;
}
int main() {
list* list = listCreate();
listAddNodeHead(list, "java");
listAddNodeTail(list, "c");
listInsertNode(list, list->head, "go", 0);
listIter* iter = listGetIterator(list, AL_START_HEAD);
listNode* node;
while ((node = listNext(iter))) {
printf("%s\t", (node->value));
}
return 0;
}
Go语言实现
下面代码是为实现 leetcode 707. 设计链表 写的,可以参考。
package main
type ListNode struct {
val int
prev *ListNode
next *ListNode
}
type MyLinkedList struct {
head *ListNode
tail *ListNode
len int
}
func Constructor() MyLinkedList {
list := MyLinkedList{nil, nil, 0}
return list
}
func (this *MyLinkedList) Get(index int) int {
if this.head == nil {
return -1
}
if index < 0 || index > this.len-1 {
return -1
}
if index == 0 {
return this.head.val
}
if index == this.len-1 {
return this.tail.val
}
iter := this.head
for i := 0; i < index; i++ {
iter = iter.next
}
return iter.val
}
func (this *MyLinkedList) AddAtHead(val int) {
node := &ListNode{val, nil, nil}
if this.len == 0 {
this.tail = node
} else {
node.next = this.head
node.prev = nil
this.head.prev = node
}
this.head = node
this.len++
}
func (this *MyLinkedList) AddAtTail(val int) {
node := &ListNode{val, nil, nil}
if this.len == 0 {
this.head = node
} else {
node.next = nil
node.prev = this.tail
this.tail.next = node
}
this.tail = node
this.len++
}
func (this *MyLinkedList) AddAtIndex(index int, val int) {
if index > this.len {
return
}
if index <= 0 {
this.AddAtHead(val)
} else if index == this.len {
this.AddAtTail(val)
} else {
iter := this.head
for i := 0; i < index; i++ {
iter = iter.next
}
node := &ListNode{val, nil, nil}
prev := iter.prev
prev.next = node
node.prev = prev
node.next = iter
iter.prev = node
this.len++
}
}
func (this *MyLinkedList) DeleteAtIndex(index int) {
if this.len == 0 || index < 0 || index > this.len-1 {
return
}
if this.len == 1 {
this.head = nil
this.tail = nil
this.len = 0
return
}
if index == 0 {
this.head = this.head.next
} else if index == this.len-1 {
this.tail = this.tail.prev
} else {
delteNode := this.head
for i := 0; i < index; i++ {
delteNode = delteNode.next
}
prev := delteNode.prev
next := delteNode.next
prev.next = next
next.prev = prev
}
this.len--
}
循环链表
除了双向链表,还有一种循环链表,他的尾结点不是只想NULL,而是一个指向头结点的指针,将整个链表形成一个环,他为我们解决通过链表中任何一个节点都可以找到链表中其他的任一节点这样一个问题。可参考下文约瑟夫问题理解。
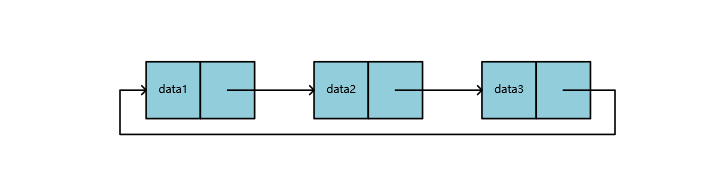
链表的应用
设计一个LRU缓存淘汰算法(LeetCode 146)
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
- 获取数据
get(key)- 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。 - 写入数据
put(key, value)- 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
需求分析:
这个算法主要核心几点需求是:
-
get方法,支持O(1)时间复杂度
- 没有找到数据,返回-1
- 找到数据,将原来的节点删除,放到链表头部
-
put方法,时间复杂度O(1)
- 如果已经存在,那么需要更新数据,将原来的节点删除,并将更新后的节点放到链表头
- 如果不存在,创建一个新节点,这时要考虑添加一个新节点后容量是否会超出
- 容量溢出:需要删除最后一个节点
- 容量没有溢出:将链表尾部节点删除,腾出一个空间,将新节点插入到链表头
这样我们就保证了最终将长久以来最少使用的那些数据放到了链表尾部
算法设计
这里问题难在选择什么数据结构,那么如果要查询时间复杂度可以达到O(1),那么肯定是哈希表了。但是哈希表又做不到插入时间复杂度为O(1),那么我们就想到是不是可以用链表啊,那么是用单链表呢还是双向链表呢,因为这个题目中有一点是:如果找到了元素,还要把该元素从原来的位置删除。可是单链表只能在删除头和尾部这种特殊节点的时候才可以做到O(1)的时间复杂度啊,因此必须得用双向链表了。用了双链表,如果我们把链表的每一个节点都保存到哈希表里,是不是当需要从链表中删除的时候,只要通过哈希表拿到这个节点,就可以很方便的进一步拿到他的前驱后继节点,然后进行删除,这个整个时间复杂度就是O(1)。
代码实现
public class LRUCache {
private static class Node {
int key;
int value;
Node prev;
Node next;
public Node() {}
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private int size;
private int capacity;
private Node head;
private Node tail;
private HashMap<Integer, Node> map;
public LRUCache(int capacity) {
this.capacity = capacity;
this.map = new HashMap<>(capacity);
this.head = new Node();
this.tail = new Node();
head.next = tail;
tail.prev = head;
}
/**
* 是否存在
* 否:值返回-1
* 是:将原来的节点删除,然后放到链表头,返回数据
*
* @param key
* @return
*/
public int get(int key) {
if (map.containsKey(key)) {
Node node = map.get(key);
remove(node);
addFirst(node);
return node.value;
} else {
return -1;
}
}
/**
* 是否存在:
* 否:创建新节点,并且判断是否超过容量
* 否:景新节点加到链表头
* 是:删除队尾节点,插入到链表头
* 是:更新数据,然后从原来的位置移除,放到头结点
*
* @param key
* @param value
*/
public void put(int key, int value) {
Node node = map.get(key);
if (null == node) {
Node newNode = new Node(key, value);
map.put(key, newNode);
addFirst(newNode);
size++;
if (capacity < size) {
map.remove(tail.prev.key);
removeLast();
size--;
}
} else {
node.value = value;
remove(node);
addFirst(node);
}
}
private void remove(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void addFirst(Node node) {
node.next = head.next;
head.next.prev = node;
node.prev = head;
head.next = node;
}
private void removeLast() {
Node lastNode = tail.prev;
tail.prev = lastNode.prev;
lastNode.prev.next =tail;
}
}
约瑟夫问题
约瑟夫问题大概是样的,是说有一天约瑟夫他们这个国家被敌人攻陷了,他们一群人,总数设为N,被迫逃到了一个山洞。他们的领导者决议宁死不降,所以想了一个自杀的游戏,就是大家坐成一圈,从第一个报数,每次数到M的人就要自杀,那么约瑟夫做到第几个位置不会死呢?假设N=6,M=4。那么我们看依次挂掉的是谁:
初始位置:1 2 3 4 5 6
第一次出局:4,剩余:1 2 3 5 6,从5开始报数
第二次出局:2,剩余:1 3 5 6,从3开始报数
第三次出局:1,剩余:3 5 6,从3开始报数
第四次出局:3,剩余:5 6。从5开始报数
第五次出局:6,5活了下来
这就是约瑟夫问题的整个过程,那么这个问题,如果用循环链表解决的一个经典问题。下面给出代码
public class JosephProblem {
private static class Node {
int item;
Node next;
public Node(int item) {
this.item = item;
}
}
private Node head;
private Node tail;
private int size;
public int size() {
return size;
}
public void add(int item) {
Node newNode = new Node(item);
if (head == null) {
head = newNode;
} else {
tail.next = newNode;
}
tail = newNode;
tail.next = head;
size++;
}
public int remove(int M) {
Node currNode = head;
for (int i = 1; i < M - 1; i++) {
currNode = currNode.next;
}
Node deleteNode = currNode.next;
currNode.next = deleteNode.next;
head = deleteNode.next;
size--;
return deleteNode.item;
}
public int get() {
return head.item;
}
public static void main(String[] args) {
JosephProblem jp = new JosephProblem();
jp.add(1);
jp.add(2);
jp.add(3);
jp.add(4);
jp.add(5);
jp.add(6);
while (jp.size() != 1) {
System.out.printf("the ID %d is killed \n", jp.remove(4));
if (jp.size == 1) {
break;
}
}
System.out.printf("the remainder number is %d and the survivor ID is %d", jp.get(), jp.get());
}
}
链表其他应用
链表这种经典的数据结构真的是用的太多了,LinkedList的实现基于链表,队列和栈也可以基于链表实现,AQS中也用到了双向链表实现同步队列,用单链表实现条件队列。。。具体的就参考各部分的笔记了。
详细代码参见Github地址

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











