







MySQL知识点整理已经进行到第四期了,间隔一段时间再看以前的题目,蓦然发现有些操作莫名其妙,可能是对表的操作还是没有透彻的理解。暑假可能要去实习了,做的就是SQL,希望归来是王者~
一、分组数据
1.创建分组
之前我们整理过聚集函数,总共有5个。我们使用聚集函数可以对行进行计数,计算平均值,求和,最大值和最小值。目前为止,所有的计算都是在表的所有数据或匹配特定的WHERE子句的数据上进行的。
比如,下面的例子返回的是供应商1003提供的产品数目:
SELECT COUNT(*) AS num_prods
FROM products
WHERE vend_id = '1003';
结果:
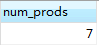
若要返回每个供应商提供的产品数目呢?提供10个以上的产品的供应商呢?
这里,我们将使用分组,将数据分为多个逻辑组,以便对每个分组进行聚集计算。
比如,我们返回每个供应商提供的产品数目,
SELECT vend_id,COUNT(*) AS num_prods
FROM products
GROUP BY vend_id;
结果:
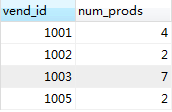
GROUP BY 按vend_id排序对每个供应商进行分组,然后对每个分组,分别计算num_prods,即提供的产品的个数。
使用GROUP BY 子句的一些规定:
- GROUP BY 子句可以包含任意数目的列,这使得能对分组进行嵌套,为数据分组进行更加精细的控制。
- 如果在GROUP BY 子句中嵌套了分组,那么所有的列将被一起计算,而不能从个别的列中提取数据。
- GROUP BY 子句列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY 子句中指定相同的表达式,不能使用别名。
- 除聚集语句外,SELECT子句的每个列都必须出现在GROUP BY 子句中出现。
- 如果分组列中含有NULL值,则NULL将会被作为一个分组返回。如果列中有多行NULL值,它们将会被分为一组。
2.过滤分组
在进行分组以后,我们需要排除一些分组,比如,列出至少有两个以上订单的顾客。为了得到这种数据,必须基于完整的分组而不是个别的行进行过滤,即where子句不能使用。而HAVING子句用来过滤分组。
比如,返回订单数不小于2的顾客,
SELECT cust_id,COUNT(*) AS orders
FROM orders
GROUP BY cust_id
HAVING COUNT(*) >=2;
结果:
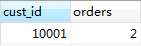
我们可以在一条语句中同时使用WHERE和HAVING子句,比如,要返回具有2个或2个以上、价格不小于10的产品的供应商。
SELECT vend_id,COUNT(*) AS num_prods
FROM products
WHERE prod_price >=10
GROUP BY vend_id
HAVING COUNT(*) >=2;
结果:
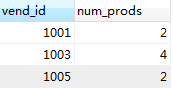
3.分组和排序

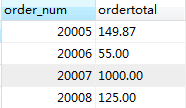
为了说明GROUP BY 和ORDER BY 语句的用法,我们举个栗子:检索总计订单价格不小于50的订单的订单号和总计订单价格:
我们先看只有GROUP BY 的情况:
SELECT order_num,SUM(quantity*item_price) AS ordertotal
FROM orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price) >=50;
结果:
我们再看GROUP BY和HAVING同时存在的情况:
SELECT order_num,SUM(quantity*item_price) AS ordertotal
FROM orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price) >=50
ORDER BY ordertotal;
结果:
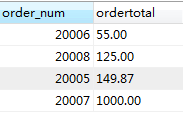
我们可以看到order_num没有变化,但是ordertotal按照从小到大的顺序进行了排序。一般而言,ORDER BY 子句默认是升序排列,如果想逆序排列,则在后面加 DESC即可。
4.SELECT子句顺序
书写顺序:
s e l e c t → f r o m → w h e r e → g r o u p b y → h a v i n g → o
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









