







论文题目:Rigid Formats Controlled Text Generation
论文传送门: SongNet
论文团队:Piji Li, Haisong Zhang, Xiaojiang Liu, Shuming Shi - Tencent AI Lab, Shenzhen, China
Github:https://github.com/lipiji/SongNet
摘要
神经文本生成在各种任务中都取得了巨大的进步。大多数任务的一个共同特征是,生成文本时,文本不限于某些严格的格式。但是,我们可能会遇到一些特殊的文本范例,例如歌词 (假定有乐谱),十四行诗,宋词等。这些文本有三个方面的典型特征:(1) 它们必须完全符合严格的预定义格式; (2) 他们必须遵守一些押韵的规则; (3) 尽管它们仅限于某些格式,但必须确保句子的完整性。据我们所知,还没有很好的基于预定义刚性格式的文本生成的研究。因此,我们提出了一个名为 SongNet 的简单优雅的框架来解决此问题。该框架的骨干是基于 Transformer 的自回归语言模型。特殊设计的符号集可以改善建模性能,尤其是在格式,韵律和句子完整性方面。我们改进了注意机制,以促使模型捕获有关格式的未来信息。预训练和微调框架旨在进一步提高生成质量。在两个收集的语料库上进行的大量实验表明,我们提出的框架在自动和人工评估方面都产生了明显更好的结果。
引言
平时我们见到的文本生成任务如对话生成、故事生成、摘要生成等多以自由生成方式为主,给定固定模板严格限制格式进行填词的文本生成任务研究较少。在实践中,我们遇到的特殊文本范例,例如歌词(假定给出了乐谱),十四行诗,宋词等是比较独特的文体形式。这些文本有三个方面的典型特征:(1)文本的组合必须遵守完全符合预定义的严格格式。假设乐谱是由乐谱组成的,那么歌词作者必须严格按照表述中的方案填写歌词内容。在图1中,歌词的音节必须与符号的音调对齐;给定词牌,定义了内容每句的字数和语法结构。(2)内容的安排必须遵守规定的押韵规则。(3)即使格式是严格的,也必须始终确保句子的完整性。
本文提出了名为 SongNet 的基于 Transformer 的自动回归语言模型,旨在解决此类硬格式控制的文本生成问题。例如,给定一首歌的歌词,让模型能够将歌词全部改写,或者只改写部分歌词。在改写的同时保证文本的格式正确、韵律合理、句子完整等基本的质量需求。为了验证我们框架的性能,我们分别收集了中文和英文两个语料库 SongCi 和 Sonnet。我们设计了几种自动评估指标和人工评估指标来进行评估。大量实验表明,在任意格式下,包括冷启动格式,甚至是我们自己新定义的格式,我们提出的框架都能产生明显更好的结果。

任务定义
Input: 一个模板
C
∈
C
C \in \mathcal{C}
C∈C:
C
=
{
c
0
c
1
c
2
c
3
,
c
0
c
1
c
2
c
3
c
4
c
5
.
}
C = \{c_0\ c_1\ c_2\ c_3,\ c_0\ c_1\ c_2\ c_3\ c_4\ c_5.\}
C={c0 c1 c2 c3, c0 c1 c2 c3 c4 c5.}
其中
C
\mathcal{C}
C 表示包含十个字加上标点 “,” 和 “.”,
c
i
c_{i}
ci 表示模板
C
\mathcal{C}
C 中需要被最后转换为真实字符的占位字符。
Output: 符合模板格式的句子
Y
Y
Y
Y
=
l
o
v
e
i
s
n
o
t
l
o
v
e
,
b
e
n
d
s
w
i
t
h
t
h
e
r
e
m
o
v
e
r
t
o
r
e
m
o
v
e
.
\begin{aligned} Y =\ &love\ is\ not\ love, \\ &bends\ with\ the\ remover\ to\ remove. \end{aligned}
Y= love is not love,bends with the remover to remove.
除了字数,两个标点也完全正确,可见
Y
Y
Y 句是完全符合该模板的。进一步,我们可以重构另一个更符合音韵等限制的模板
C
′
=
{
c
0
c
1
c
2
l
o
v
e
,
c
0
c
1
c
2
c
3
c
4
r
e
m
o
v
e
.
}
C' = \{c_0\ c_1\ c_2\ \ love,\ c_0\ c_1\ c_2\ c_3\ c_4\ \ remove.\}
C′={c0 c1 c2 love, c0 c1 c2 c3 c4 remove.},由此来得到可能更好的输出结果。我们把这个操作叫做润色 (polishing)。
模型描述
概览
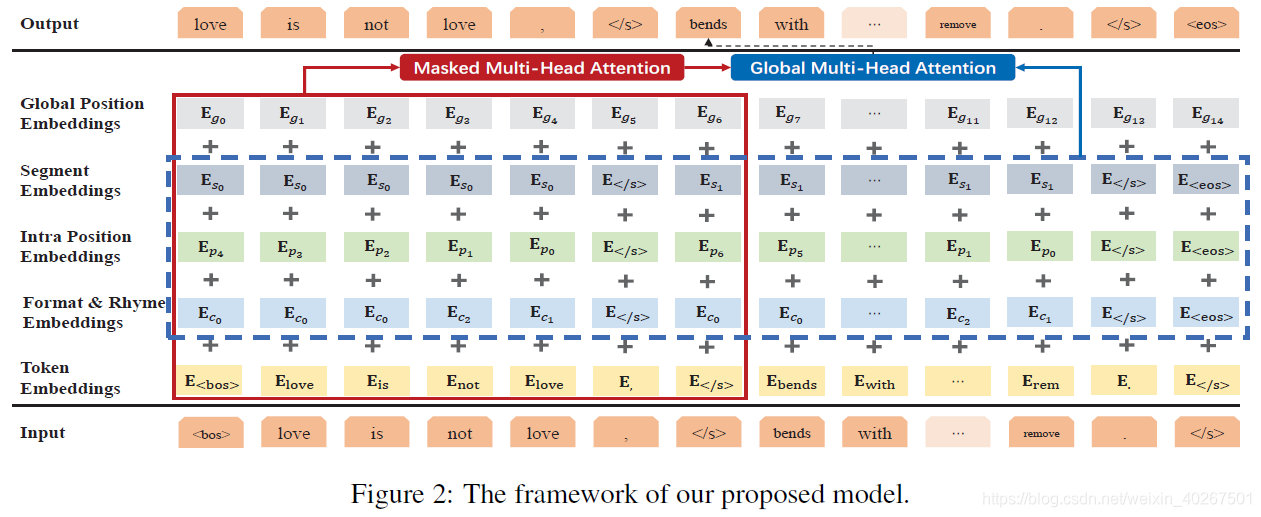
如图2,我们框架是基于 Transformer 的自回归语言模型。我们设计了一些指示符号表示来提高格式,韵律和句子完整性方面的效果。具体而言,
C
=
{
c
i
}
C = \{c_i\}
C={ci} 用于格式和韵律的建模;内部位置符号
P
=
{
p
i
}
P = \{p_i\}
P={pi} 用来表示为了提高句子韵律和完整性的局部位置。句子符号
S
=
{
s
i
}
S = \{s_i\}
S={si} 用来识别句子边界,以进一步提高句子质量。同时还改进了注意力机制,以促使模型捕获诸如句子结尾标记之类的未来格式信息。
细节
由于模型是基于 Transformer 的自回归架构,在训练中的输入是 "
⟨
b
o
s
⟩
\langle bos \rangle
⟨bos⟩ love is not love,
⟨
/
s
⟩
\langle /s \rangle
⟨/s⟩ …, bends with the remover to remove.
⟨
/
s
⟩
\langle /s \rangle
⟨/s⟩",而对应的输出是:
l
o
v
e
i
s
n
o
t
l
o
v
e
,
⟨
/
s
⟩
b
e
n
d
s
w
i
t
h
t
h
e
r
e
m
o
v
e
r
t
o
r
e
m
o
v
e
.
⟨
/
s
⟩
⟨
e
o
s
⟩
\small \begin{aligned} &love\ is\ not\ love\ ,\ \langle /s \rangle \\ &bends\ with\ the\ remover\ to\ remove\ .\ \langle /s \rangle\ \langle eos \rangle \end{aligned}
love is not love , ⟨/s⟩bends with the remover to remove . ⟨/s⟩ ⟨eos⟩
我们的目标是进行格式控制的文本生成,因此指示符号是针对目标输出序列设计的。
格式和韵律符号:
C
=
{
c
0
,
c
0
,
c
0
,
c
2
,
c
1
,
⟨
/
s
⟩
c
0
,
c
0
,
c
0
,
c
0
,
c
0
,
c
2
,
c
1
,
⟨
/
s
⟩
,
⟨
e
o
s
⟩
}
\begin{aligned} C = \{&c_0, c_0, c_0, c_2, c_1, \langle /s \rangle \\ &c_0, c_0, c_0, c_0, c_0, c_2, c_1, \langle /s \rangle, \langle eos \rangle \} \end{aligned}
C={c0,c0,c0,c2,c1,⟨/s⟩c0,c0,c0,c0,c0,c2,c1,⟨/s⟩,⟨eos⟩}
其中
{
c
0
}
\{c_0\}
{c0}代表普通文本符号,
{
c
1
}
\{c_1\}
{c1}代表标点符号,
{
c
2
}
\{c_2\}
{c2}代表该位置是韵脚 “love” 和 “remove”,
⟨
/
s
⟩
\langle /s \rangle
⟨/s⟩ 和
⟨
e
o
s
⟩
\langle eos \rangle
⟨eos⟩ 被保留。如此设计的目的是让模型在读模板的时候,碰到的时候能推测出该处是结尾词、韵脚词,遇到的时候能够知道该输出一个标点符号 (也可以保留模板中的标点符号不做改写)。
内部位置符号:
P
=
{
p
4
,
p
3
,
p
2
,
p
1
,
p
0
,
⟨
/
s
⟩
p
6
,
p
5
,
p
4
,
p
3
,
p
2
,
p
1
,
p
0
,
⟨
/
s
⟩
,
⟨
e
o
s
⟩
}
\begin{aligned} P = \{&p_4, p_3, p_2, p_1, p_0, \langle /s \rangle \\ &p_6, p_5, p_4, p_3, p_2, p_1, p_0, \langle /s \rangle, \langle eos \rangle \} \end{aligned}
P={p4,p3,p2,p1,p0,⟨/s⟩p6,p5,p4,p3,p2,p1,p0,⟨/s⟩,⟨eos⟩}
模板中的每个句子都会有一个内部位置序列,特别强调的一点是,我们这里将符号倒序排列,旨在让模型能够学习到句子的一个渐进结束的过程,当遇到的时候句子结束,那么当遇到
{
p
0
}
\{p_0\}
{p0}的时候模型能够意识到句子生成动态到了尾声。除此之外,句子内部位置信息还能捕捉诸如对联一类文本的前后句对仗位置特征。
句子符号:
S
=
{
s
0
,
s
0
,
s
0
,
s
0
,
s
0
,
⟨
/
s
⟩
s
1
,
s
1
,
s
1
,
s
1
,
s
1
,
s
1
,
s
1
,
⟨
/
s
⟩
,
⟨
e
o
s
⟩
}
\begin{aligned} S = \{&s_0, s_0, s_0, s_0, s_0, \langle /s \rangle \\ &s_1, s_1, s_1, s_1, s_1, s_1, s_1, \langle /s \rangle, \langle eos \rangle \} \end{aligned}
S={s0,s0,s0,s0,s0,⟨/s⟩s1,s1,s1,s1,s1,s1,s1,⟨/s⟩,⟨eos⟩}
对句子位置进行建模,每个符号代表句子在序列中的 ID,旨在让模型推测出目前在生成的句子位置,捕捉学习到押韵的句对。例如莎士比亚的十四行诗押韵格式为
"
A
B
A
B
C
D
C
D
E
F
E
F
G
G
"
"ABAB\ CDCD\ EFEF\ GG"
"ABAB CDCD EFEF GG",有了句子位置特征模型就会比较容易捕捉到1句和3句押韵,2和4押韵等。
在训练的时候,所有符号和输入 token 会被送进模型,同时为了适应我们的问题,我们对 Transformer,BERT 和 GPT2 中的注意力机制进行了适当的修改。
如图2中红框所示,训练的时候所有的符号以及文本转化成向量后输入到基于 Transformer 的语言模型中:
H
t
0
=
E
w
t
+
E
c
t
+
E
p
t
+
E
s
t
+
E
g
t
\mathbf{H}^0_t = \mathbf{E}_{w_t}+\mathbf{E}_{c_t}+\mathbf{E}_{p_t}+\mathbf{E}_{s_t}+\mathbf{E}_{g_t}
Ht0=Ewt+Ect+Ept+Est+Egt
其中
0
0
0 是层数,
t
t
t 是状态索引。
E
∗
\mathbf{E}_*
E∗ 是输入
∗
*
∗ 的嵌入向量。
w
t
w_t
wt 是位置
t
t
t 的真实字符。
c
c
c,
p
p
p 和
s
s
s 是三种预定义的符号。
g
g
g 是和 Transformer 中相同的全局位置表示。
如图2中蓝框所示,为了让模型在自回归的动态过程中能够看到模板的未来信息,我们还引入了另一个变量
F
0
\mathbf{F}^0
F0,该变量只融合了预先定义的符号信息,没有输入的文本信息,避免了右侧信息泄露:
F
t
0
=
E
c
t
+
E
p
t
+
E
s
t
\mathbf{F}^0_t = \mathbf{E}_{c_t}+\mathbf{E}_{p_t}+\mathbf{E}_{s_t}
Ft0=Ect+Ept+Est
然后通过两个注意力层对输入信息进行建模,第一层是自回归中带 mask 的注意力机制:
Masked 多头注意力层:
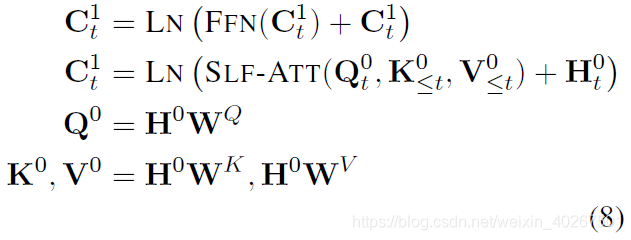
其中 SLF-ATT(
⋅
\cdot
⋅),LN(
⋅
\cdot
⋅),和 FFN(
⋅
\cdot
⋅) 分别表示自注意力机制,层归一化和前馈神经网络。注意我们仅使用
t
t
t 之前的状态作为关注上下文。
在得到式(8)中的
C
t
1
\mathbf{C_t^1}
Ct1 之后,其将会被送入通过
F
0
\mathbf{F^0}
F0 能够看到模板全局信息的第二个注意力层:
全局注意力层:
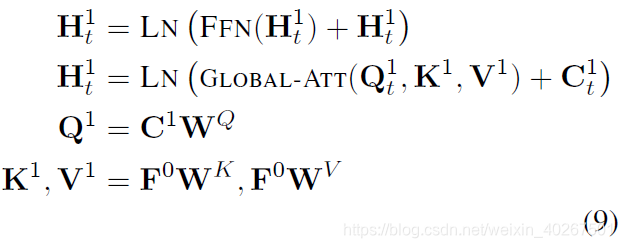
由此,我们可以发现来自
F
0
\mathbf{F^0}
F0 的所有上下文信息都被考虑到了。我们可以将这两个注意层迭代地应用于整个
H
L
\mathbf{H}^L
HL 模型层,直到获得最终表示
H
L
\mathbf{H}^L
HL。注意,
H
\mathbf{H}
H 是逐层更新的,但是全局变量
F
0
\mathbf{F}^0
F0 是固定的。
最后,优化目标是最小化整个序列的负对数似然函数:
L
n
l
l
=
−
∑
t
=
1
n
log
P
(
y
t
∣
y
<
t
)
\mathcal{L}^{\mathrm{nll}} = -\sum^{n}_{t=1} \log P(\mathrm{\bf y}_t|\mathrm{\bf y}_{<t})
Lnll=−t=1∑nlogP(yt∣y<t)
预训练和微调
尽管我们的框架可以完全在目标语料库的训练数据集上进行训练,但是通常语料库的规模是有限的。 例如,莎士比亚十四行诗语料库中只有大约150个样本。因此,我们还设计了预训练和微调框架,以进一步提高生成质量。
在生成任务中,会遇到给定部分文本,补充其他文本的局部补全需求。例如,在模板中,给定部分句子,补全其他句子;在句子中,知道了部分词,补充其他词。为了使得模型有解决该类需求的能力,即在第2节中提到的精炼和润色的能力,我们在预训练阶段,设计了 mask 策略:模板中保留部分词,模型来学习预测其他的词。这样模型就可以根据两侧的context信息进行预测生成,近似的有了双向语言模型的能力。具体来说,我们随机 (假设20%) 选择部分原始内容在构建格式符号$ C $时使它们保持不变。例如,对于示例句子,我们将获得一个新的符号集
C
′
C'
C′:
C
′
=
{
c
0
,
c
0
,
c
0
,
l
o
v
e
,
c
1
,
⟨
/
s
⟩
b
e
n
d
s
,
c
0
,
c
0
,
c
0
,
c
0
,
r
e
m
o
v
e
,
c
1
,
⟨
/
s
⟩
,
⟨
e
o
s
⟩
}
\small \begin{aligned} C' = \{&c_0, c_0, c_0, love, c_1, \langle /s \rangle \\ &bends, c_0, c_0, c_0, c_0, remove, c_1, \langle /s \rangle, \langle eos \rangle \} \end{aligned}
C′={c0,c0,c0,love,c1,⟨/s⟩bends,c0,c0,c0,c0,remove,c1,⟨/s⟩,⟨eos⟩}
其中 “love”,“bends” 和 “remove” 在格式
C
′
C'
C′ 中保持不变。
在预训练阶段之后,我们可以直接在目标语料库上进行微调,而无需调整任何模型结构。
生成
我们可以分配任何格式和押韵符号 C C C来控制生成。给定 C C C,我们将自动获得 P P P 和 S S S。 并且该模型可以迭代地从特殊 token ⟨ b o s ⟩ \langle bos \rangle ⟨bos⟩ 进行生成,直到遇到结束标记 ⟨ e o s ⟩ \langle eos \rangle ⟨eos⟩。解码过程采用 beam-search 算法和截断的 top-k 采样。
实验设置
设置
模型参数大小在预训练和微调阶段保持不变。总层数为 L = 12 L=12 L=12,隐层大小为 768。两个注意力层都用了 12 个头。预训练阶段采用了 Adam 优化方法,Noam 学习率衰减策略以及 10,000 warmup steps。
数据集
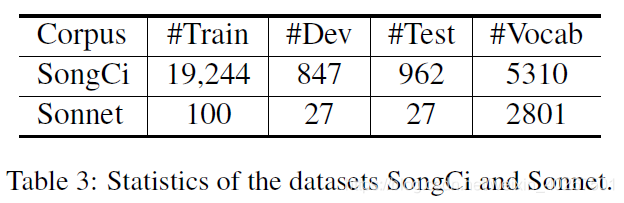
中文我们以宋词生成作为预测目标;英文生成莎士比亚十四行诗 (sonnet)。模型分预训练和微调两个阶段。在预训练阶段,中文语料主要是新闻和维基百科,英文语料是维基百科和 BooksCorpus。
评价指标
除了常用的文本生成评测指标如ppl、distinct外,我们还专门设计了度量模板准确率 (Format)、韵律准确率 (Rhyme) 和句子完整度 (integrity) 的指标。(详见论文)
对比模型
S2S 带注意力机制的 Sequence-to-sequence 框架。我们将模板和韵律符号 C C C 作为输入序列,目标句作为输出序列。
GPT2 我们分别在 SongCi 和 Sonnet 上进行了微调。
SongNet 我们的框架,包含预训练和微调两个阶段。
我们同时进行了消融实验用于对比我们定义的符号以及不同模型之间的表现。
- SongNet (only pre-tuning) 无微调阶段
- SongNet (only fine-tuning) 无预训练阶段
- SongNet-GRU 用 GRU 代替 Transformer 的主要结构
- SongNet w/o C 去除模板和韵律符号 C C C.
- SongNet w/o P 去除内部位置符号 P P P.
- SongNet w/o S 去除句子符号 S S S.
- SongNet w/ inverse-P 内部位置符号采用升序
结果和讨论
结果
表1和表2分别描述了 SongNet 以及 baseline 方法 S2S 和 GPT2 在语料库 SongCi 和 Sonnet 的结果。显然,我们的预训练和微调框架 SongNet 在大多数自动指标上均获得了最佳性能。尤其是在格式精度的度量标准上,SongNet甚至可以获得 98%+ 的值,这意味着我们的框架可以进行与预定义格式严格匹配的生成。在 PPL,韵律准确度和句子完整性方面,SongNet 也要比 S2S 和 GPT2 等 baseline 方法以及仅包含预训练或微调阶段的模型变体具有更好的性能。
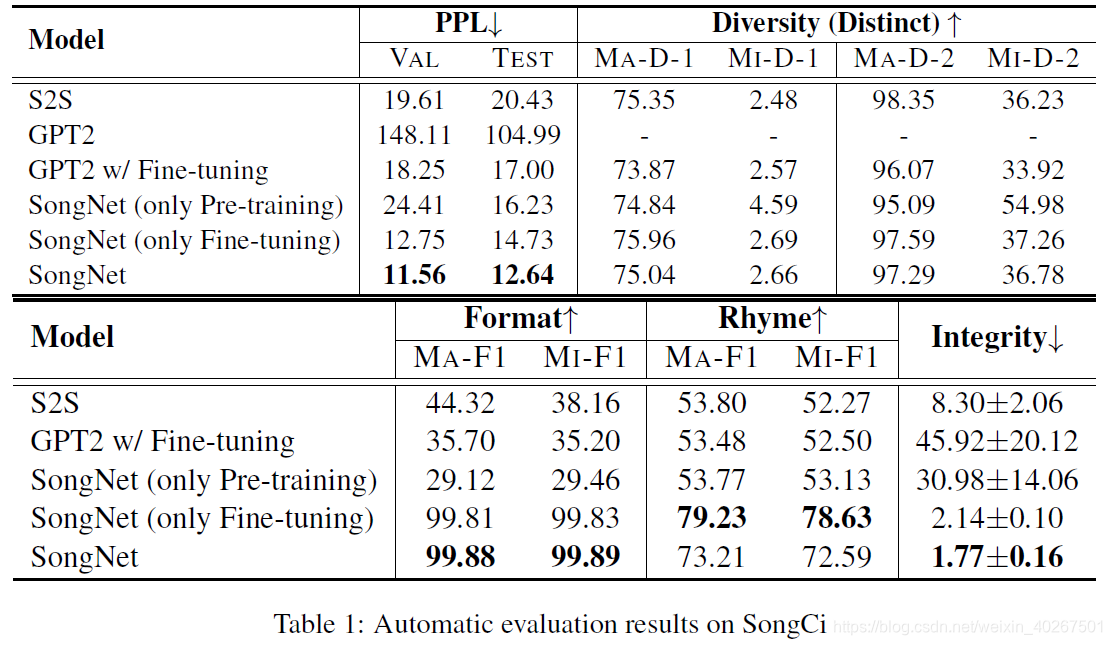
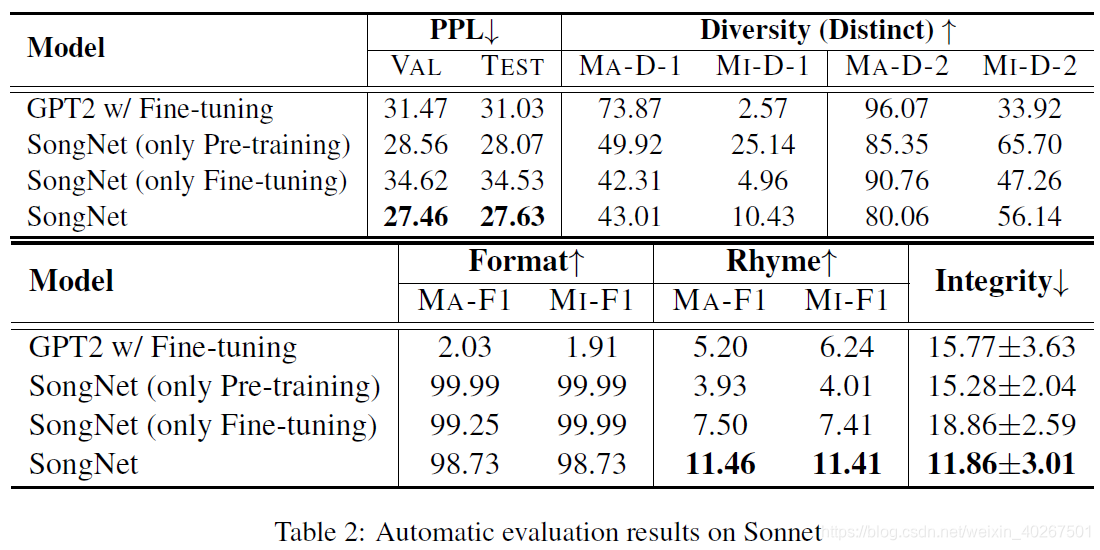
另一个观察结果是,语料库 Sonnet 上的某些结果不如 SongCi 上的结果好。主要原因是 Sonnet 在训练集中仅包含100个样本,如表3中所示。因此,该模型无法捕获足够有用的特征,尤其是对于押韵问题。
消融分析
我们对语料库 SongCi 进行消融研究,并在表4中描述了实验结果。 应该注意的是,所有模型都完全在 SongCi 语料库上训练,没有任何预训练阶段。 从结果中我们可以得出结论,引入的符号
C
C
C,
P
P
P 和
S
S
S 确实在提高整体性能方面起着至关重要的作用,尤其是在格式,韵律和句子完整性方面。即使某些组件无法在所有指标上同时提高性能,但将它们组合使用可以获得最佳性能。

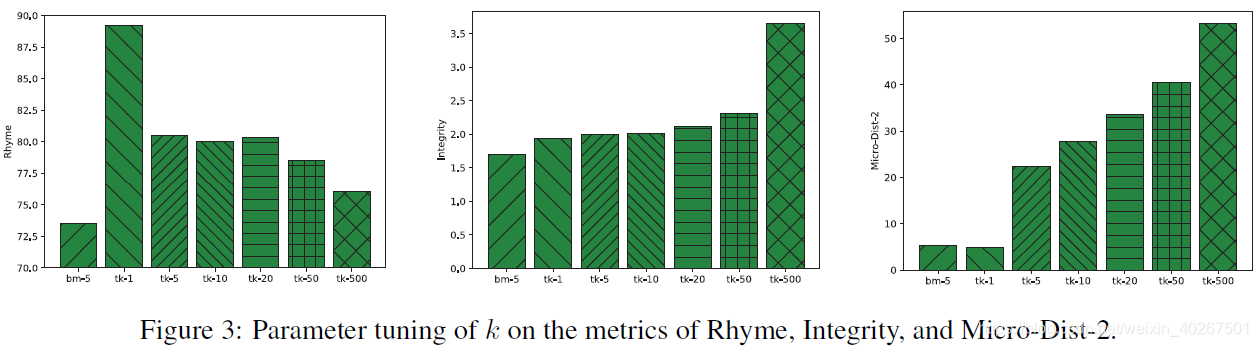
参数调整
由于我们采用 top- k k k 采样作为主要解码策略,因此我们设计了几个实验来对 k k k 进行参数调整。我们将 k k k 分别设为 1、5、10、20、50、500。 我们还提供 beam-search (beam = 5) 的结果,以供比较和参考。
参数调整结果如图3所示,从结果中我们可以看到,较大的
k
k
k 可以显著增加结果的多样性。但是押韵的准确性和句子的完整性同时会下降。 因此,在实验中,我们让
k
=
32
k = 32
k=32 以获得多样性和一般质量之间的权衡。
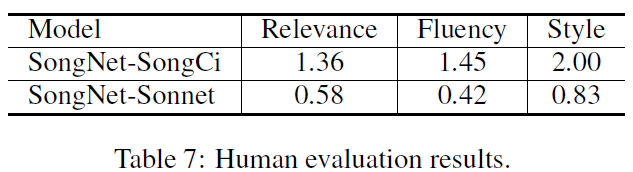
人工评测
为了进行人工评估,我们仅对最终模型 SongNet 生成的结果进行判断。 从结果中我们可以看到,在语料库 SongCi 上的结果比在语料库 Sonnet 上的结果要好得多,这是因为语料库规模不同,而小规模也导致所有指标急剧下降。
实例分析
表5分别描述了 SongCi 和 Sonnet 的几个生成的示例。对于 SongCi,格式 (词牌) 均为冷启动样本,它们不在训练集中,甚至是新定义的。 我们的模型仍然可以在格式、韵律和完整性上产生高质量的结果。但是,对于十四行诗的语料,即使该模型可以生成 14 行文本,但由于训练集不足 (仅100个样本),其质量也不如 SongCi。我们将在未来解决这个有趣且具有挑战性的 few-shot 问题。
另外,之前提到,给定包含某些固定文本信息的格式
C
C
C,我们的模型具有精炼和润色的功能。表6中显示了在此设置下生成的结果的示例,这些示例表明我们的模型 SongNet 可以生成令人满意的结果,尤其是在 SongCi 上。


结论
我们提出了解决一个具有挑战性的任务,称为刚性格式控制的文本生成。我们设计了一个包含预训练和微调架构的 SongNet 模型用来解决该问题。为了提高格式、韵律和句子完整性的性能,我们设计了一些特定的符号集。在收集到的两个语料库上进行的大量实验表明,在给定任意冷启动格式的情况下,我们的框架在自动度量和人工评估方面均产生明显更好的结果。
Ref:
[1] Rigid Formats Controlled Text Generation
[2] [ACL2020] SongNet:格式控制下的文本生成
[3] AI歌词生成 | SongNet简述


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









