






关键字: [Amazon Web Services re:Invent 2023, SageMaker HyperPod, Foundation Models, Distributed Training, Model Training, Hyperpod, Resilience]
本文字数: 1200, 阅读完需: 6 分钟
视频
如视频不能正常播放,请前往bilibili观看本视频。>> https://www.bilibili.com/video/BV17u4y1g7pP
导读
Amazon SageMaker HyperPod 是专门为加速基础模型(FM)训练而设计的。参加这个课程,了解如何在 Amazon SageMaker HyperPod 上连续数周或数月无中断地训练基础模型。了解它如何持续监控集群健康状况,并即时修复和替换故障节点,以自动恢复训练而不会丢失进度。了解它如何预配置了 SageMaker 分布式训练库,通过将训练数据和基础模型分割成更小的块并在集群节点上并行处理,从而充分利用集群的计算和网络基础设施,提高基础模型训练性能变得十分简单。
演讲精华
以下是小编为您整理的本次演讲的精华,共900字,阅读时间大约是4分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。
Ian Gibbs开始介绍了Amazon SageMaker HyperPod,这是一种针对大型基本模型训练的全新管理服务。他指出,随着Transformer架构的发展,如BERT和GPT-3,训练日益复杂的模型所需的计算能力正在迅速增长。仅在过去两年内,训练需求就已增长了100倍。
训练过程中面临着诸多挑战,包括组装数十TB的大型数据集,配置数百或数千个节点的集群以分布式处理工作负载,以及开发使用PyTorch和TensorFlow等框架协调分布式处理的代码。在模型架构经过数百次实验迭代的过程中,还需要在合理的几天或周内时间内训练具有数十亿参数的模型,并在每次实例故障时及时保存检查点。硬件故障可能导致严重的性能下降,甚至可能使整个任务崩溃并停滞数小时或数天。
为了解决这些问题,SageMaker HyperPod提供了一个弹性的训练环境。其自愈能力允许在无用户干预的情况下自动恢复失败的实例,从而将总体训练时间减少高达20%。例如,它可以检测故障节点并在几分钟内重新启动替换节点,而手动管理的集群可能需要数小时或数天。此外,该服务还能优化在亚马逊云科技基础设施上的分布式训练性能,从而额外加速20%的训练时间。HyperPod还通过SSH访问、自定义脚本和与SageMaker Studio的直接集成,实现了对环境的完全控制,从而实现快速迭代。
一些客户已经成功地使用了HyperPod的功能:
-
Stability AI使用HyperPod训练生成性AI模型。过去,硬件故障曾导致数百小时的浪费并打断他们团队的工作流程。现在,使用HyperPod后,他们的训练时间和成本减少了50%,这主要得益于自动恢复功能。
-
Perplexity AI(一家开发了对话AI引擎的公司)在使用HyperPod中优化的亚马逊云科技分布式训练库的基础上,将其实验吞吐量提高了2倍。
Hugging Face的研究人员利用HyperPod的可定制性,安装专用框架和工具以优化基础模型训练。这种自由创新的能力加速了他们的发展。吉布斯先生向同事Py详细介绍了HyperPod的功能。用户首先上传自定义脚本并定义头部节点和计算节点的配置,例如实例类型、节点数量等。通过API调用,HyperPod处理配置实例、网络连接以及高达100Gbps的FSx for Luster共享存储。运行工作负载时,用户可以通过SLURM调度器提交批处理任务,交互地分配集群资源,或者使用像PyTorch Lightning和Ray这样的框架。多个用户可以同时共享集群,调度器在作业之间高效地分配资源。HyperPod的一个关键优势是自动从故障中恢复。如果在训练过程中实例发生故障,HyperPod的代理会在分钟内检测它并重新启动替代实例,以便从最后一个检查点继续执行任务。这最小化了训练中断,避免了浪费几天或几周的时间。对于性能,HyperPod结合了优化的EC2实例(如P4d)、高达100Gbps的EFA网络带宽、提供数百万IOPS的FSx存储以及可以提高训练速度10-20%的SageMayer分布式训练库。CloudWatch、DCGM和SageMayer提供了关于利用率指标(如GPU使用率、内存等)的可观察性。接下来,Hugging Face的Mario Lopez Ramos讨论了他们使用HyperPod的经验。Hugging Face运营着一个为超过600万名用户服务的开放AI模型平台。其集群在1000个GPU上运行来自数据科学家的60个并发训练任务。HyperPod的弹性通过在故障后快速恢复任务来节省大量时间。一个实际例子是恢复了因硬件故障而损失的50%的训练时间。自定义环境的能力赋予他们的研究人员迅速迭代的能力。在880个GPU上训练CodeGen模型时,他们实现了每GPU400多兆FLOPS的利用率,将检查点保存到NVMe然后保存到S3。总的来说,HyperPod满足了他们对共享容量、最大化利用率、故障后的快速恢复以及可定制环境的需求。
本次演示以HyperPod自修复功能实时展示为结尾。在一个集群上启动了一个训练任务。一旦诱发到一个GPU故障,HyperPod的代理将自动检测到这个故障并在数分钟内启动一个替代实例,使得任务能够从最后一个检查点恢复。这样避免了由于自定义训练基础设施可能导致数日停机的困扰。
总的来说,通过提供一种无缝地从故障中恢复的弹性环境,优化性能并提供完全自定义控制,Amazon SageMaker HyperPod已经简化了大规模基础模型训练。这个托管服务让用户摆脱了基础设施管理的负担,让他们可以专注于创新和发展模型。HyperPod特别解决了长期训练时间、频繁中断和复杂集群配置等现实挑战——使得像Hugging Face这样的用户能够更快速地训练模型并加速AI应用的上市时间。
下面是一些演讲现场的精彩瞬间:
艾安·吉布斯(Ian Gibbs)作为Amazon SageMaker的产品经理,详细介绍了该服务所提供的高效构建、训练和调整机器学习模型的超参数优化功能。

在训练大型人工智能模型的过程中,管理者需要应对复杂的分布式系统以及对模型设计的不断迭代,而硬件问题的出现可能会给这一过程带来困扰。
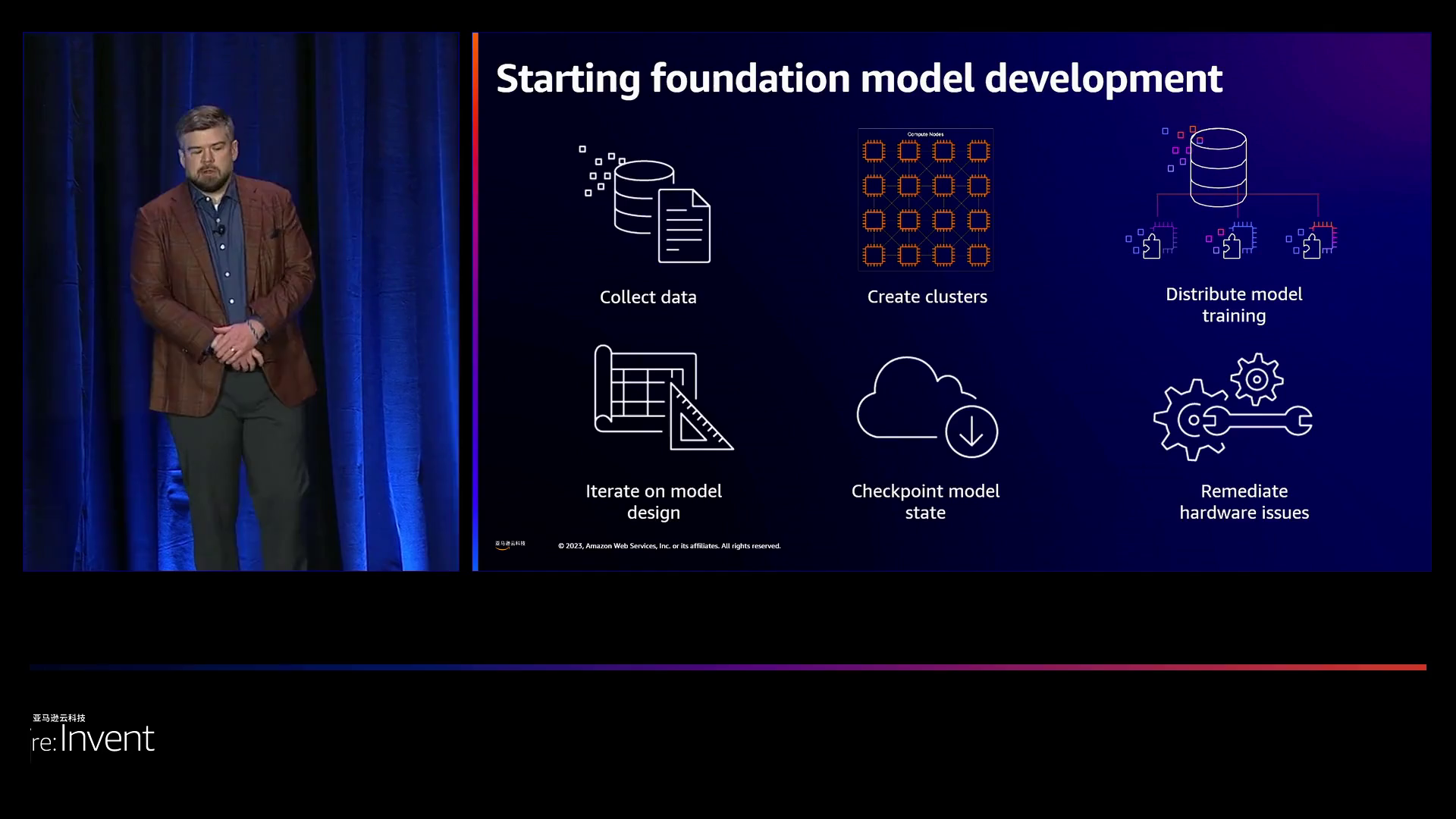
然而,SageMaker HyperPod的引入使得稳定性得到提高,能够自动替换故障实例,从而节省高达50%的训练时间和成本。

这一点从一张截图中可以看出,Amazon云科技的领导者描述了Hugging Face如何受益于SageMaker的使用,从而在无基础设施限制的条件下实现快速创新。

Amazon Cloud Technology开发出了SageMaker IP,旨在优化分布式机器学习训练工作的性能、稳定性、可用性和灵活性。
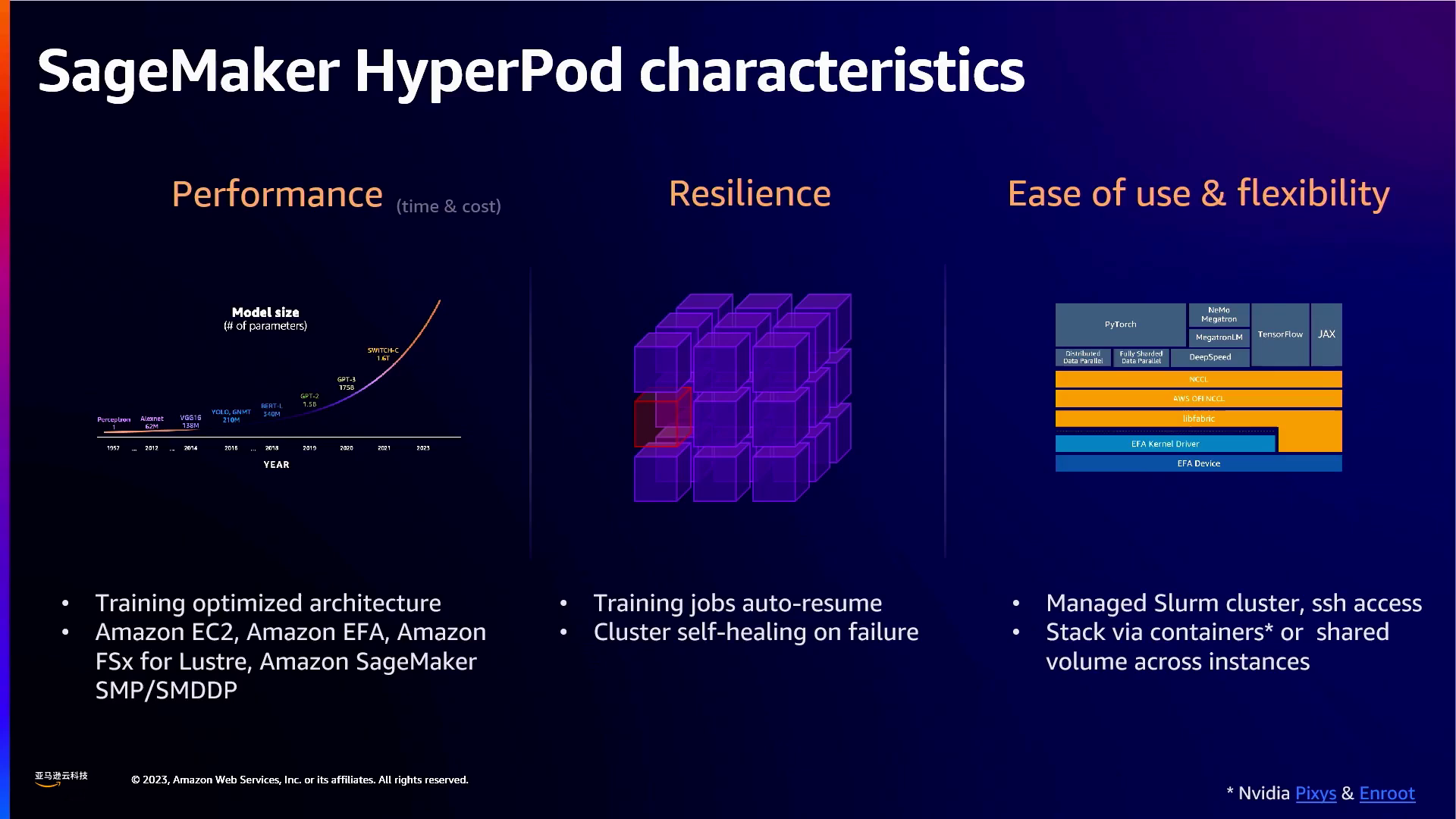
此外,他们还提供了在EKS集群上管理软件部署的多种灵活选项,包括生命周期脚本、共享文件系统和容器等。

这些功能有助于为用户的基础模型训练设定最佳实践的计算环境。

总结
亚马逊SageMaker HyperPod是一种创新的托管服务,为大规模基础模型训练提供了一个具有弹性和优化过的工作环境。HyperPod具备自动恢复硬件故障的自修复集群能力,从而能将训练时间缩短最多达20%。此外,它还提供了对SageMaker的分布式训练库(如SMP和SMDDP)的访问,这些库针对亚马逊云科技网络进行了优化,从而实现高达20%的训练速度提升。该服务支持完全定制的技术栈,使得研究人员能够快速进行创新,例如安装框架和调试工具。HyperPod已经成功的吸引了许多知名的客户,比如Stability AI,通过避免硬件故障节省了50%的成本和时间;Perplexity AI,他们的实验吞吐量提高了两倍,使用的是优化后的库;还有Hugging Face,他们的研究人员可以自由地定制优化方案。一个演示展示了HyperPod能够在2-3分钟内从诱导故障中自动恢复,而如果缺乏这一功能,可能需要几天的时间才能恢复。HyperPod降低了配置、管理和优化基础设施的复杂性,使团队能够专注于开发新的AI模型。
演讲原文
https://blog.csdn.net/just2gooo/article/details/134838479
想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
2023亚马逊云科技re:Invent全球大会 - 官方网站
点击此处,一键获取亚马逊云科技全球最新产品/服务资讯!
点击此处,一键获取亚马逊云科技中国区最新产品/服务资讯!
即刻注册亚马逊云科技账户,开启云端之旅!
【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”
亚马逊云科技是谁?
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者,自 2006 年以来一直以不断创新、技术领先、服务丰富、应用广泛而享誉业界。亚马逊云科技可以支持几乎云上任意工作负载。亚马逊云科技目前提供超过 200 项全功能的服务,涵盖计算、存储、网络、数据库、数据分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体,以及应用开发、部署与管理等方面;基础设施遍及 31 个地理区域的 99 个可用区,并计划新建 4 个区域和 12 个可用区。全球数百万客户,从初创公司、中小企业,到大型企业和政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本,加快创新,提升竞争力,实现业务成长和成功。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











