







准备三台虚拟机。
本文中ip分别设置为192.168.137.101、192.168.137.102、192.168.137.103.
步骤1-4使用root用户,步骤5及以后使用hadoop用户。
1、配置主机名和域名,开通防火墙端口
#修改主机名
hostnamectl set-hostname hadoop01 #第一台
hostnamectl set-hostname hadoop02 #第二台
hostnamectl set-hostname hadoop03 #第三台
#重启虚拟机
init 6
#配置域名(三台均配置,配置内容相同)
vim /etc/hosts
192.168.137.101 hadoop01
192.168.137.102 hadoop02
192.168.137.103 hadoop03
#开通hadoop01的端口——只操作hadoop01即可
firewall-cmd --zone=public --add-port=9870/tcp --permanent #namenode web-ui端口
firewall-cmd --zone=public --add-port=9868/tcp --permanent #secondary namenode web-ui端口
firewall-cmd --zone=public --add-port=8020/tcp --permanent #namenode通讯端口
firewall-cmd --zone=public --add-port=9864/tcp --permanent #datanode web-ui端口,另外两台机器也可以开下9864端口
firewall-cmd --zone=public --add-port=9866/tcp --permanent #datanode的数据传输接口
firewall-cmd --zone=public --add-port=8088/tcp --permanent
firewall-cmd --zone=public --add-port=8031/tcp --permanent
firewall-cmd --zone=public --add-port=8042/tcp --permanent #另外两台机器也可以开下8042端口
firewall-cmd --reload
2、创建用户和用户组(3台均配置)
#创建hadoop用户组
groupadd hadoop
#创建hadoop用户,并归属于hadoop用户组
useradd -m -g hadoop hadoop
#设置hadoop用户密码
passwd hadoop
3、创建环境搭建目录,并设置权限给hadoop用户(3台均配置)
mkdir /data
chown -R hadoop:hadoop /data
#后续所有操作均使用hadoop用户
su - hadoop
4、时钟同步(3台均配置)
yum -y install ntp
systemctl enable ntpd
systemctl start ntpd
timedatectl set-timezone Asia/Shanghai
ntpdate -u time.nist.gov
date
5、ssh免密登录(3台均配置)
cd /home/hadoop/.ssh
ssh-keygen -t rsa -C "邮箱"
#输入3次回车
#拷贝当前机器ssh公钥信息至另外两台虚拟机
ssh-copy-id hadoop01 #hadoop01需要拷贝至自己机器,不然hdfs-start.sh报错
ssh-copy-id hadoop02
ssh-copy-id hadoop03
6、安装jdk(3台均配置)
cd /data
#上传jdk-8u341-linux-x64.tar.gz
tar -zxvf jdk-8u341-linux-x64.tar.gz
vim ~/.bash_profile
#在文件结尾追加以下内容
export JAVA_HOME=/data/jdk1.8.0_341
export PATH=$JAVA_HOME/bin:$PATH
#:wq 保存退出
source ~/.bash_profile
java -version

7、上传hadoop安装包并解压(3台均配置)
cd /data
#上传hadoop-3.3.6.tar.gz
tar -zxvf hadoop-3.3.6.tar.gz
8、配置文件修改(3台均配置)
(1)hadoop配置文件
cd /data/hadoop-3.3.6/etc/hadoop
vim workers
#输入以下内容
hadoop01
hadoop02
hadoop03
vim hadoop-env.sh
#编辑以下内容
export JAVA_HOME=/data/jdk1.8.0_341
export HADOOP_HOME=/data/hadoop-3.3.6
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
vim core-site.xml
#添加以下内容
#hadoop01节点为NameNode节点,DataNode与NameNode的8020端口通讯
#io操作文件缓冲区大小为131072bit
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为“你想要进行删除操作的用户名” -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
(2)hdfs配置文件
vim hdfs-site.xml
#添加以下内容
#dfs.datanode.data.dir.perm——hdfs文件系统默认创建文件权限设置
#dfs.namenode.name.dir——NameNode元数据的存储位置
#dfs.namenode.hosts——NameNode运行哪些节点的DataNode连接
#dfs.blocksize——hdfs默认大小256MB
#dfs.namenode.handler.count——namenode处理的开发线程数
#dfs.datanode.data.dir——从节点datanode的数据存储目录
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>hadoop01,hadoop02,hadoop03</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
(3)yarn配置文件
vim yarn-site.xml
<configuration>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
<description>历史服务器路径</description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>hadoop01:8089</value>
<description>代理服务器主机和端口</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开始日志聚合</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志HDFS的存储路径</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
<description>ResoucesManager的所在节点</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器</description>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManager中间数据本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManager数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为Mapreduce程序开启Shuffle服务</description>
</property>
<!-- 设置yarn历史日志保存时间 7天 -->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>302400</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<!-- 设置MR程序默认运行模式,yarn集群模式,local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MR程序历史服务web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<!-- yarn环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- map环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- reduce环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
9、配置环境变量(3台均配置)
vim ~/.bash_profile
export HADOOP_HOME=/data/hadoop-3.3.6
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH
source ~/.bash_profile

10、创建hdfs存储文件路径
#创建NameNode文件目录(只需在hadoop01上创建)
mkdir -p /data/nn
#创建DataNode文件目录(3台均需创建)
mkdir -p /data/dn
11、初始并启动hdfs和yarn集群(只需在hadoop01上操作)
(1)初始化
#格式化NameNode
hadoop namenode -format
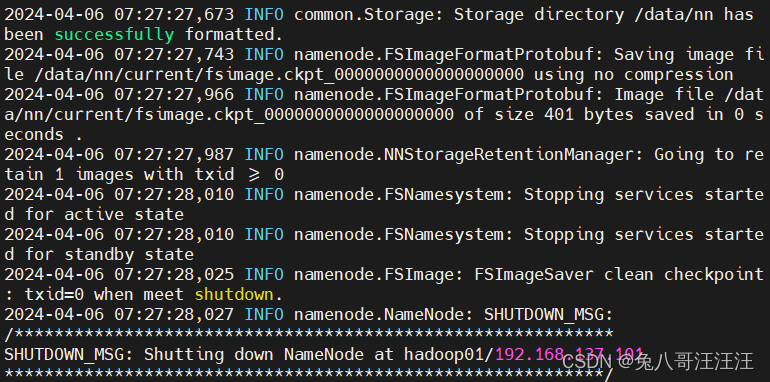
(2)启动集群
#启动hdfs集群
start-dfs.sh
#启动yarn集群
start-yarn.sh
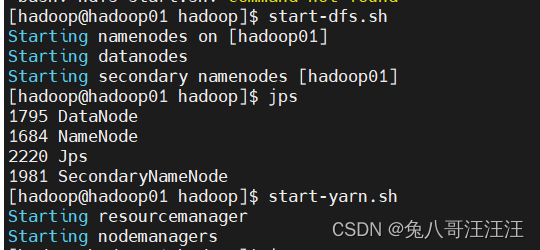
(3)验证
#验证
#hadoop01有NameNode\SecondaryNameNode\DataNode\ResourceManager\NodeManager\WebAppProxyServer进程
#hadoop02和hadoop03有DataNode\NodeManager进程
jps
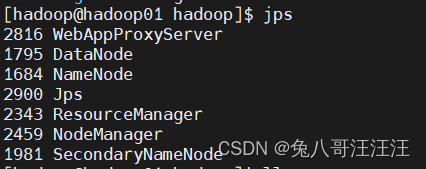
访问 http://192.168.137.101:9870/dfshealth.html#tab-datanode
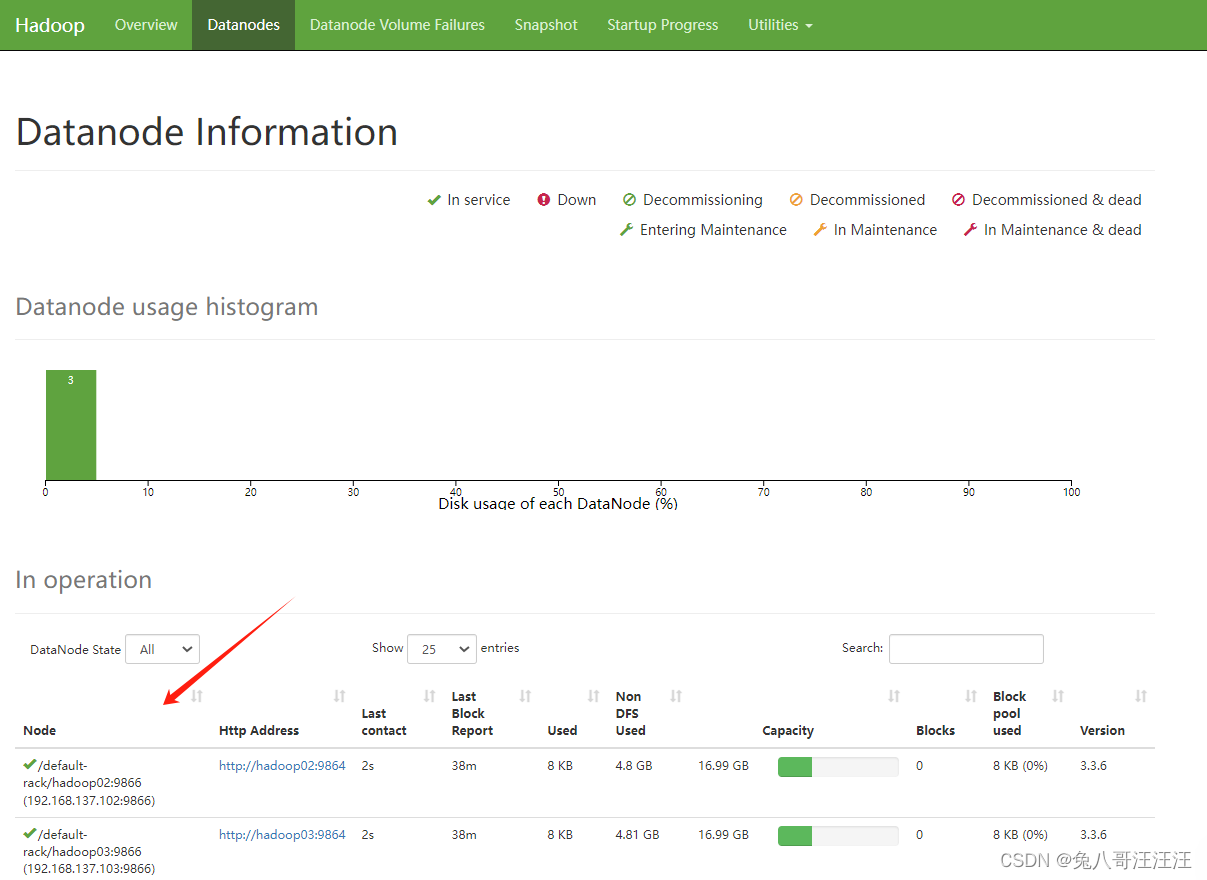
访问 http://192.168.137.101:8088/cluster/nodes
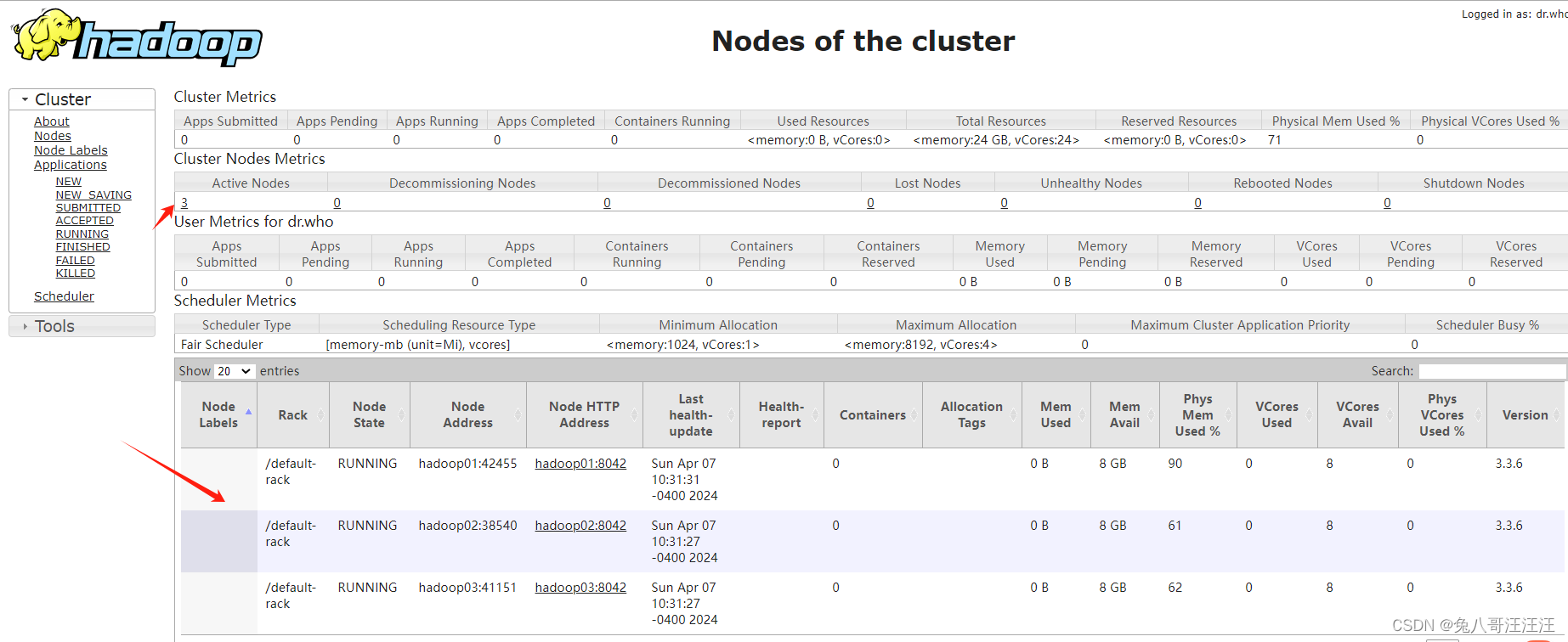

12、关闭hdfs集群和yarn集群
#一键关闭hdfs集群
stop-dfs.sh
#一键关闭yarn集群
stop-yarn.sh


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









