






这里提出了一个简单而高效的端到端网络架构来实现CLIP到视觉定位任务的无监督和全监督迁移。该方法在单源和多源场景下的RefCOCO/+/g数据集上都明显优于当前最先进的无监督方法,提升幅度分别为从6.78%至10.67%和11.39%至14.87%,同时优于现有的弱监督方法。此外,在全监督设置下也具有显著能效优势。端到端网络架构CLIP-VG开源:简单高效实现CLIP到视觉定位任务的无监督和全监督迁移
发表期刊: IEEE Transactions on Multimedia 中科院/JCR一区顶刊
论文发表链接: https://ieeexplore.ieee.org/abstract/document/10269126
Arxiv: https://arxiv.org/abs/2305.08685
代码: https://github.com/linhuixiao/CLIP-VG(已开源)
第一作者: 肖麟慧(中科院自动化所博士)
作者单位: 中国科学院自动化所多模态人工智能系统全国重点实验室;鹏城实验室;中国科学院大学人工智能学院
摘要
视觉定位(VG)是视觉语言领域的一个重要课题,它涉及到在图像中定位由表达句子所描述的特定区域。为了减少对人工标记数据的依赖,无监督的方法使用伪标签进行学习区域定位。然而,现有的无监督方法的性能高度依赖于伪标签的质量,并且这些方法总是遇到可靠性低多样性差的问题。
为了利用视觉语言预训练模型来解决定位问题,并合理利用伪标签,我们提出了一种新颖的方法CLIP-VG,它可以使用伪语言标签对CLIP进行自步式课程自适应。我们提出了一个简单而高效的端到端网络架构来实现CLIP到视觉定位任务的迁移。在以CLIP为基础的架构上,我们进一步提出了单源和多源课程自适应算法,这些算法可以逐步找到更可靠的伪语言标签来学习最优模型,从而实现伪语言标签的可靠度和多样性之间的平衡。
我们的方法在单源和多源场景下的RefCOCO/+/g数据集上都明显优于当前最先进的无监督方法,提升幅度分别为从6.78%至10.67%和11.39%至14.87%。同时,我们的方法甚至优于现有的弱监督方法。此外,我们的模型在全监督设置下也具有一定的竞争力,同时达到SOTA的速度和能效优势。代码和模型可在https://github.com/linhuixiao/CLIP-VG上获得。
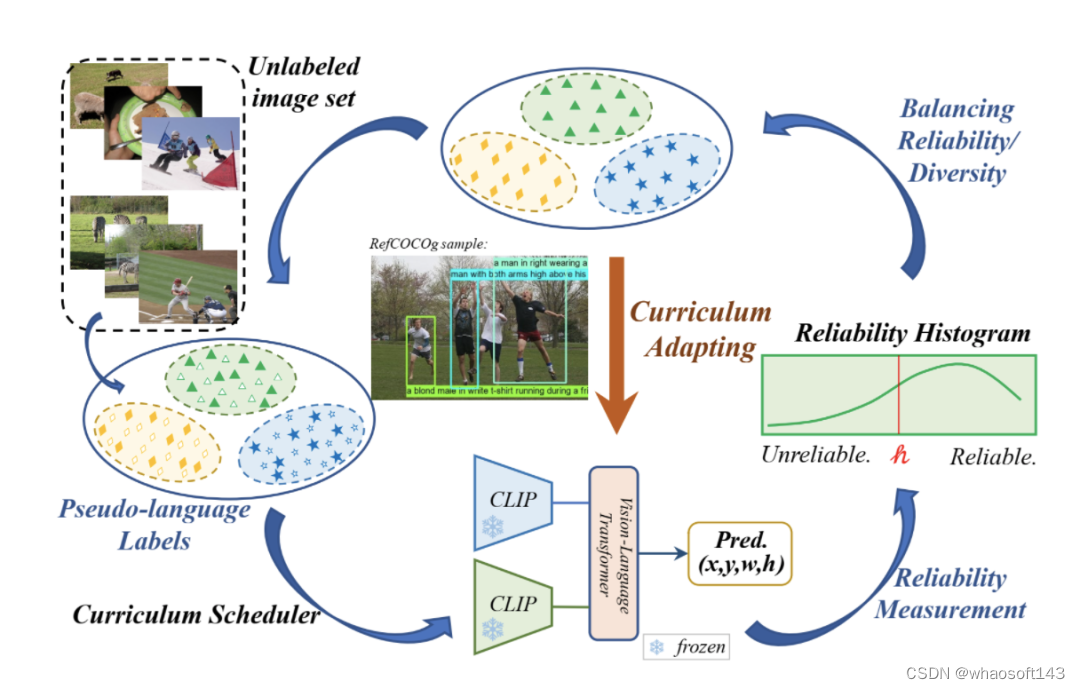
图1. CLIP-VG的主要思想,它在自步课程自适应的范式中使用伪语言标签来实现CLIP在视觉定位任务上的迁移学习
一、引言
视觉定位(Visual Grounding,VG),又称指代表达理解(Referring Expression Comprehension,REC),或短语定位(Phrase Grounding, PG),是指在特定图像中定位文本表达句子所描述的边界框(bounding box,即bbox)区域,这一技术已成为视觉问答、视觉语言导航等视觉语言(Vision-Language, V-L)领域的关键技术之一。
由于其跨模态的特性,定位需要同时理解语言表达和图像的语义,这一直是一项具有挑战性的任务。考虑到其任务复杂性,现有的方法大多侧重于全监督设置(即,使用手工三元组数据作为监督信号)。然而,有监督的定位要求使用高质量的手工标注信息。具体来说,表达句子需要与bbox配对,同时在指代上是唯一的,并且需要具有丰富的语义信息。为了减少对手工高成本的标记数据的依赖,弱监督(即,仅给定图像和查询对,没有配对的bbox)和无监督定位(即,不使用任何与任务相关的标注信息去学习定位图像区域)最近受到越来越多的关注。
现有的无监督定位方法主要是利用预训练的检测器和额外的大规模语料库实现对未配对数据的指代定位。最先进的无监督方法提出使用人工设计的模板和空间关系先验知识来匹配目标和属性检测器,再与相应的目标bbox匹配。这将生成文本表达和bbox的伪配对数据,它们被用作为伪标签,进而以监督的方式学习定位模型。然而,这些现有方法中的伪标注信息有效与否严重依赖于在特定数据集上预训练的目标或属性检测器。这可能会限制语言词汇和匹配模式的多样性,以及上下文语义的丰富度,最终损害模型的泛化能力。
在过去的几年里,视觉语言预训练(Vision-Language Pre-trained, VLP)基础模型(如CLIP)通过适应(adapting)或提示(prompting)的范式在使用少量任务相关数据的基础上进行迁移,在许多下游任务上取得了出色的结果。这些基础模型的主要优点是,它们可以通过自监督约束从网络数据和各种下游任务数据(例如,BeiT-3)中学习通用的知识。这启发我们考虑迁移VLP模型(本工作中使用CLIP),以无监督的方式解决下游定位问题。然而由于缺乏与任务相关的标记数据,因此,这是一项具有挑战性的任务。一个直接的解决方案是利用以前的无监督定位方法中生成的伪标签来微调预训练模型。然而,这将影响预训练模型的泛化能力,因为特定的伪标签和真实特定任务的标签之间存在差距。
在本文中,我们提出了CLIP-VG,如图 1 所示,这是一种新颖的方法,它可以通过利用伪语言标签对CLIP进行自步地课程自适应,进而解决视觉定位问题。首先,我们提出一个简单而高效的端到端纯 Transformer 且仅编码器的网络架构。我们只需要调整少量的参数,花费最少的训练资源,就能实现CLIP向视觉定位任务的迁移。其次,为了通过寻找可靠的伪标签来实现对CLIP网络架构更稳定的自适应迁移,我们提出了一种评估实例级标签质量的方法和一种基于自步课程学习(SPL)的渐进自适应算法,即可靠度评估(III-C部分)和单源自步自适应算法(SSA,III-D部分)。实例级可靠度被定义为特定标签源学习的评估器模型对其样本正确预测的可能性。具体而言,我们学习一个初步的定位模型作为可靠度评估器,以CLIP为模型的主干,然后对样本的可靠度进行评分,构建可靠度直方图(RH)。接下来,根据构建的直方图,以自步的方式执行SSA算法,逐步采样更可靠的伪标签,以提高定位的性能。为了有效地选择伪配对的数据子集,我们设计了一种基于改进的二叉搜索的贪心样本选择策略,以实现可靠度和多样性之间的最优平衡。
我们所提出的CLIP-VG的一个主要优点是其渐进式自适应框架,其不依赖于伪标签的特定形式或质量。因此,CLIP-VG可以灵活扩展,从而可以访问多个伪标签源。在多源场景中,我们首先独立学习每个伪标签源特定源的定位模型。然后,我们提出了源级复杂度的评估标准。具体而言,在SPL的不同步骤中,我们根据每个表达文本中实体的平均数量,从简单到复杂逐步选择伪标签源。在SSA的基础上,我们进一步提出了特定源可靠度(SR)和跨源可靠度(CR),以及多源自适应(MSA)算法(III-E节)。特定源的可靠度定义为使用当前标签源学习的定位模型正确预测当前伪标签的近似可能性。相应的,交叉源可靠度的定义是通过与其他标签源学习的定位模型正确预测当前源伪标签的近似可能性。因此,整个方法可以渐进式地利用伪标签以由易到难的课程范式来学习定位模型,最大限度地利用不同源的伪标签,从而保证基础模型的泛化能力。
在RefCOCO/+/g、RefitGame和Flickr30K Entities这五个主流测试基准中,我们的模型在单源和多源场景下的性能都明显优于SOTA无监督定位方法Pseudo-Q,分别达到6.78% ~ 10.67% 和11.39% ~ 14.87%。所提出的SSA算法和MSA算法的性能增益为3%以上。此外,我们的方法甚至优于现有的弱监督方法。与全监督SOTA模型QRNet相比,我们仅使用其更新参数的7.7% 就获得了相当的结果,同时在训练和推理方面都获得了显著的加速,分别高达26.84倍和7.41倍。与最新报道的结果相比,我们的模型在速度和能效方面也达到了SOTA。综上所述,本文的贡献有四个方面:
- 据我们所知,我们是第一个使用CLIP实现无监督视觉定位的工作。我们的方法可以将CLIP的跨模态学习能力迁移到视觉定位上,而且训练成本很小。
- 我们首次在无监督视觉定位中引入自步课程学习的范式。我们提出的可靠度评估和单源自步自适应的方法可以通过使用伪标签在由易到难的学习范式中逐步增强基于CLIP的视觉定位模型。
- 我们首先提出了多源自步自适应算法来扩展了我们的方法,同时可以获取多个伪标签源的信息,进而灵活地提高语言分类的多样性。
- 我们进行了大量的实验来评估我们方法的有效性。结果表明,我们的方法在无监督环境下取得了显著的改进,同样,我们的模型在全监督环境下也具有一定的竞争力。
二、方法
我们提出CLIP- VG,它是一种可以通过利用伪语言标签进行自步课程自适应来解决视觉定位问题的新颖方法。我们的方法主要包括: (1)、一个简单而高效的基于CLIP的纯Transformer的视觉定位模型; (2)、一个样本可靠度评估方案; (3)、一个单源场景下的自适应算法; (4)、一个进一步扩展的多源自适应算法。
A. 任务定义
我们的方法遵循之前的无监督方法Pseudo-Q的设置,即在训练期间不使用任何与任务相关的手工标注。

B.网络架构
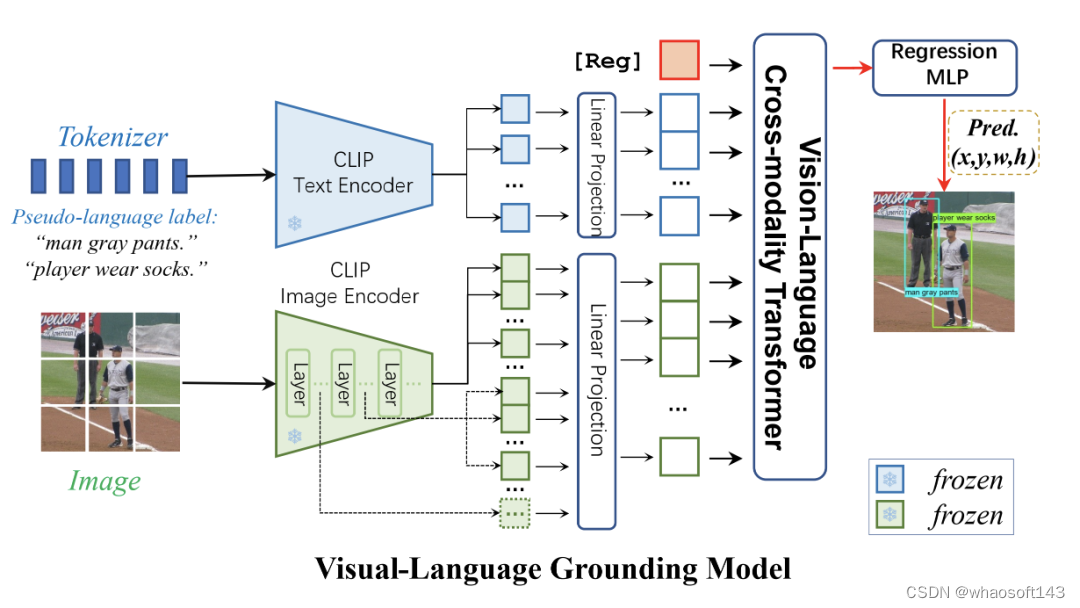
图2. CLIP-VG的模型架构

C. 可靠度评估(Reliability Measurement)
我们的方法建立在通用的课程学习范式的基础上,其中模型通过利用自己过去的预测,经过多轮由易到难的训练。为了促进定位任务中的无监督迁移,我们首先利用一个在原始伪标签上训练过的模型,应用伪标签质量评估来选择伪标签子集,然后在自训练循环中迭代重复这一过程。
在单模态任务中,我们可以很容易地通过预定义的规则来衡量数据的难度,例如句子长度、NLP中的词性熵、CV中的目标数量等,但由于跨模态定位数据的语义相关性,无法直接评估视觉定位中伪标签的质量。因此,我们定义了一个度量方法来评估伪标签的质量,称为可靠度,它被定义为通过特定标签源学习到的定位模型对其本身伪标签样本正确预测的可能性。我们认为,可靠度越高,伪标签越接近正确的标签,而更加不是噪音或不可靠的数据。

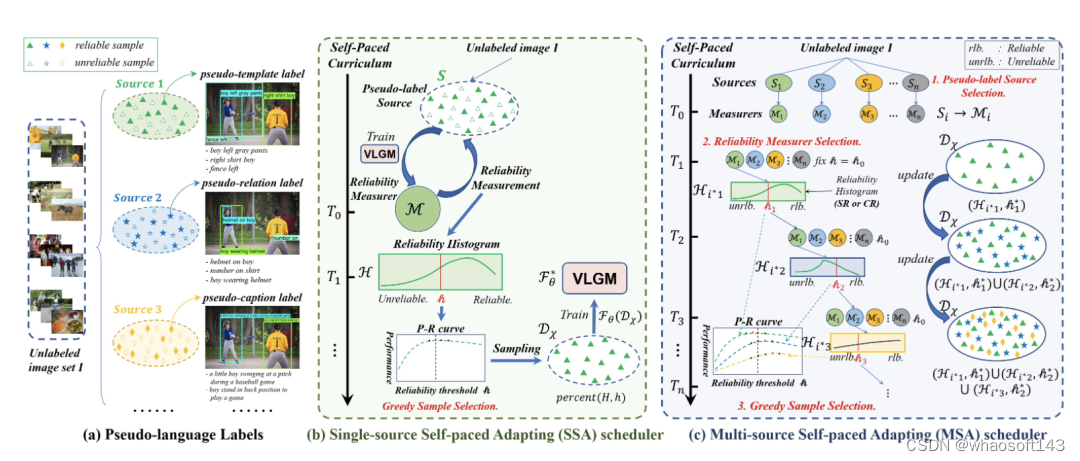
图3. 利用伪语言标签和自步课程学习实现无监督视觉定位。
图中,(a) 伪语言标签的示意图;(b)单源自步自适应(Single-source self-paced Adapting, SSA)利用视觉语言定位模型(VLGM)对伪模板标签进行可靠度评估和贪心样本选择,通过寻找可靠的伪标签实现对CLIP的自适应迁移;(c)多源自适应(Multi-source Self-paced Adapting, MSA)在SSA的基础上进一步提出了特定源可靠度(SR)和跨源可靠度(CR)。它依次进行伪标签源选择、可靠度评估器选择和贪心样本选择,从而达到可靠度和多样性的最佳平衡。
D.单源自步课程自适应算法 (Single-source Self-paced Adapting,SSA)
算法1. 单源自步课程自适应算法(SSA算法)

为了通过寻找可靠的伪标签来实现对基于CLIP的网络架构的稳定自适应,我们提出了单源自步课程自适应算法(Single-source Self-pace Curriculum Adapting algorithm, SSA),通过基于可靠度评估的课程选择的方式,逐步采样可靠的三元组伪标签。

E.多源自步课程自适应算法(Multi-source Self-paced Adapting,MSA)
算法2. 多源自步课程自适应算法(MSA算法)

我们提出的自步自适应算法不依赖于伪标签的具体形式和质量,因此可以灵活扩展用于访问多个伪标签源。使用多个伪标签源将增加语言分类和匹配模式的多样性,以及上下文语义的丰富性,从而提高视觉定位模型的泛化能力。在真实场景中,从各种视觉和语言上下文中获取多个来源的伪语言标签并不困难(如大规模语料库、视觉问答、图像描述、场景图生成、视觉语言导航等)。我们将在实验部分中详细介绍如何获得多个伪语言标签源。
随着多源伪标签的加入,不可靠数据的影响将更加严重。此外,由于不同标签源在语言分类上的分布差异,解决这一问题并不容易。因此,我们提出了基于SSA的多源自适应算法(MSA),如图3-(c) 和算法 2 所示。


三、实验
多源伪语言标签的生成
在单源情况下,我们使用Pseudo-Q中模块生成的模板伪标签。这些标签是由空间关系先验知识和检测器提供的目标标签合成的,包括类别信息和属性信息。然而,模板伪标签缺乏语法和逻辑结构,而语言词汇受到检测器识别类别的限制。
在多源情况下,除了模板伪标签外,我们利用基于场景图生成(SGG)工作RelTR生成的场景图关系作为伪关系标签,利用基于图像字幕(IC)工作M2 / CLIPCap 生成的标题作为伪标题标签。

图4. RefCOCO/+/g数据集(val split)中ground-truth查询标签的文本特征和定位难度定性对比图
A. 与最先进方法的比较
在本节中,我们在五个主流基准上验证了我们的方法,分别是 RefCOCO/+/g,ReferItGame和Flickr30K Entities。图 4 显示了RefCOCO/+/g数据集中的验证样本,这可以清晰表明三种数据集的真实定位查询标签的语言特征和定位困难程度存在显著差异。从RefCOCO到RefCOCOg,随着语言实体数量的增加,其语言复杂度也增加。
我们将我们的方法应用于单源伪模板标签和多源伪语言标签,以验证我们的方法在无监督设置中的有效性。此外,我们同样使用手工高质量的三元组手工标注在全监督设置下比较目前主流的SOTA模型,以证实我们的模型在速度和能效方面的优势。
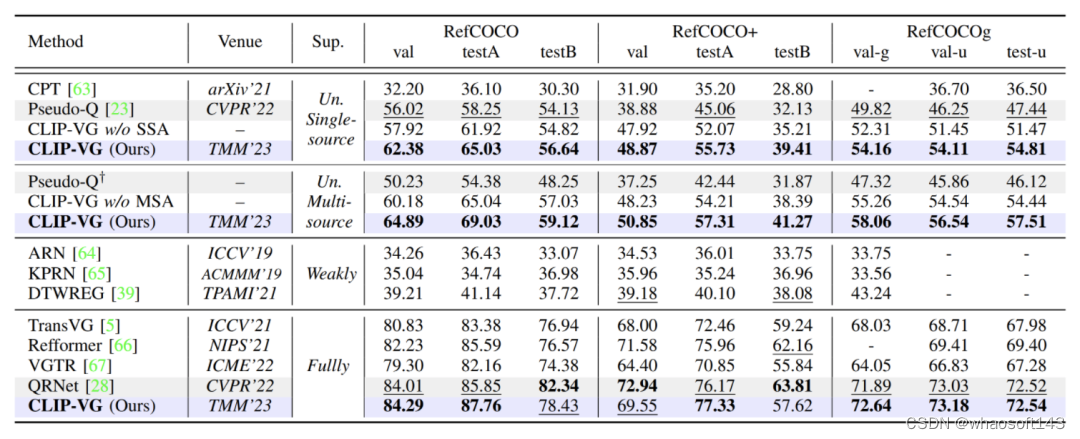
表1. 与SOTA方法在RefCOCO/+/g三个数据集上Top-1精度(Accu@0.5%)的对比结果
A.1 RefCOCO / RefCOCO + / RefCOCOg
如表1所示,我们在全监督和无监督两种情况下都提供了实验结果。我们将我们的方法与现有的SOTA无监督方法 Pseudo-Q 在单源和多源场景下进行了比较。虽然 Pseudo-Q 与之前的工作相比有了很大的提升,但我们所提方法在三个数据集上的性能都优于 Pseudo-Q,在单源数据集上分别提升了6.78%(testA)、10.67%(testA)、7.37%(test-u),在多源数据集上分别提升了14.65%(testA)、14.87%(testA)、11.39%(test-u)。伪标签很容易导致模型过拟合,从表中可知,从单源到多源,由于不可靠数据的影响,Pseudo-Q的性能下降(参见表 VIII),而我们的模型避免了多源不可靠伪标签的影响。此外,我们的结果也优于所有的弱监督方法,并且这一模型在全监督环境下也具有竞争力。
值得注意的是,我们没有在全监督的情况下比较MDETR,因为MDETR利用预训练方法通过使用来自多个数据集的混合定位数据来重新训练主干。因此,将其结果与我们的工作进行比较是不公平的。
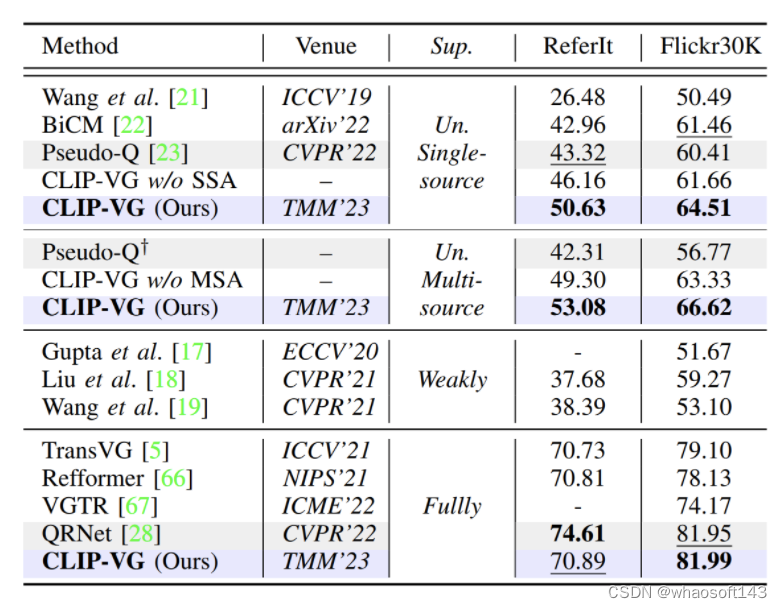
表2. 与SOTA方法在RferItGame和Flickr30K Entity两个数据集上基于Top-1精度(Accu@0.5%)的对比结果
A.2 ReferItGame 和 Flickr30K Entity
在表II中,在单源数据集和多源数据集上,我们所提方法分别比Pseudo-Q方法提高了7.31%和4.1%,以及9.77%和9.85%,并且优于所有弱监督方法。

表3. 模型的能效、推理训练速度的优势对比
B. 训练/推理成本和速度
如表 III 所示,我们比较了目前基于Transformer 的竞争模型在视觉和语言主干、模型参数、训练成本和推理速度方面的差异。其结果是在单个 NVIDIA 3090 GPU上得到的。Pseudo-Q、TransVG和 MDETR 使用的预训练主干是Resnet、BERT和DETR,而QRNet使用Resnet、Swin Transformer和BERT,而我们只使用 CLIP-ViT-B/16。从结果中我们可以看到,现有的全监督SOTA模型(如QRNet,MDETR)在训练和推理方面都特别慢。与QRNet相比,我们仅更新了其7.7%的参数,并取得了出色的训练和推理速度,分别高达26.84倍和7.41倍,同时还获得了具有竞争力的结果。基于 YORO 报告的结果,我们的模型在速度和能效方面也是最先进的。
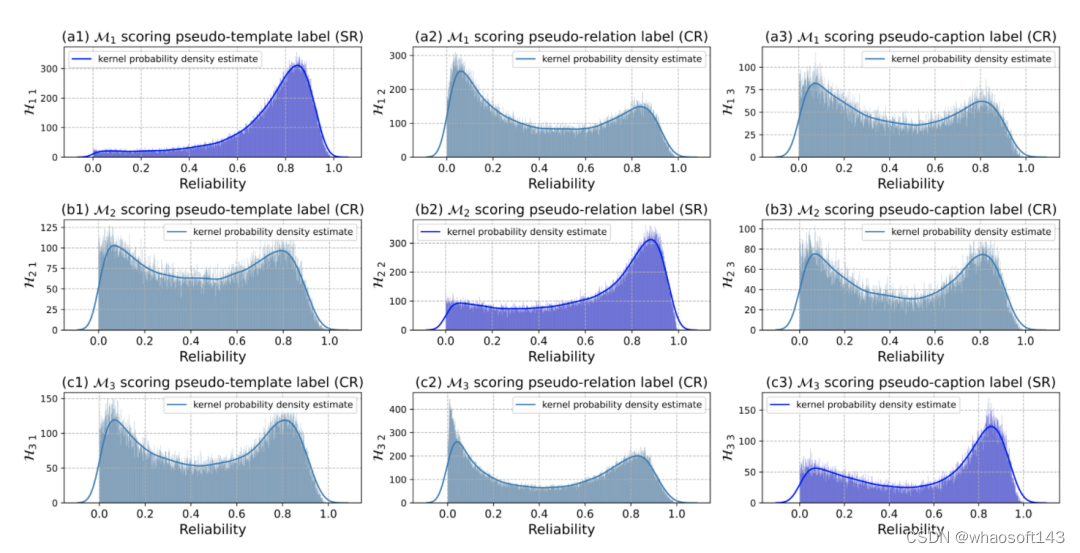
图5. 特定源可靠度和跨源可靠度分布直方图
C. 可靠度直方图的可视化
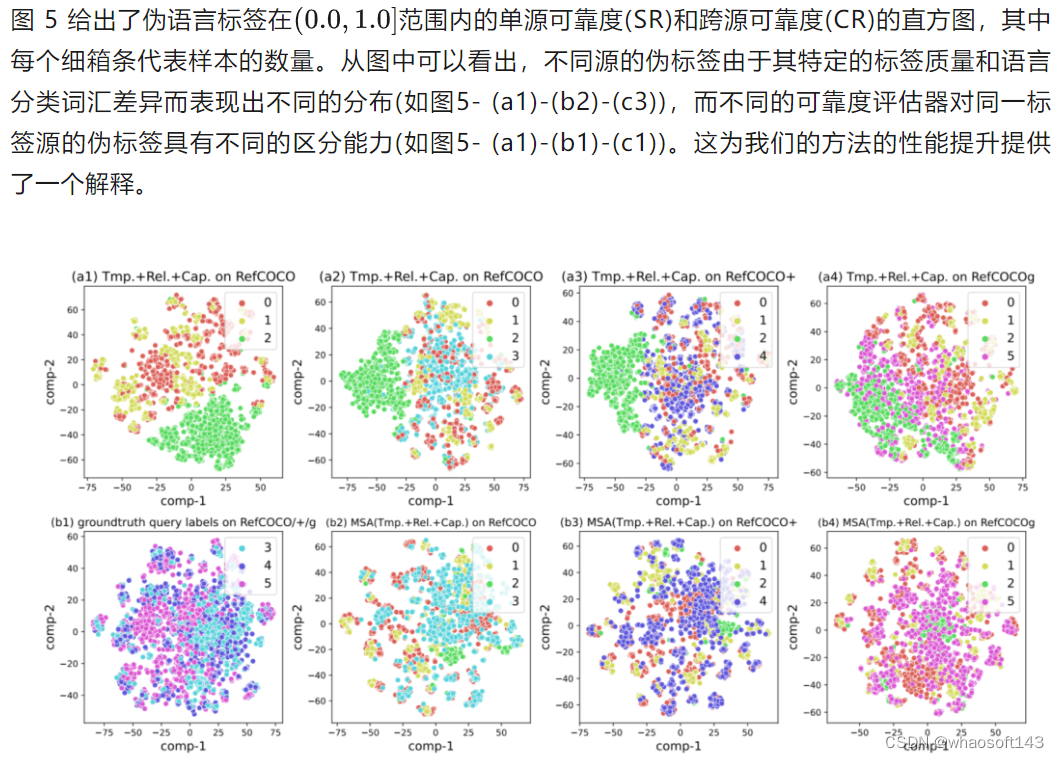
图6. 利用t-SNE对RefCOCO/+/g数据集上的伪语言标签和真实查询标签的CLIP文本特征可视化对比图
D. MSA泛化能力的可视化
如图 6 所示,我们使用 t-SNE 可视化RefCOCO/+/g数据集上伪语言标签和真值查询标签的CLIP文本特征。图6-(a1)是在RefCOCO数据集上的三个伪标签的特征,图6-(b1)是在RefCOCO/+/g在验证集上的ground-truth查询标签的特征,我们分别展示了3个伪标签源的特征分布与3个真实查询标签的特征分别的差异。图6-(a2)至(a4)和图6-(b2)至(b4)分别是在RefCOCO/+/g数据集上使用 MSA 前后三个伪标签来源和真实查询标签的特征分布对比。在MSA算法执行前,伪语言标签和真实查询标签的分布差异较大,但在MSA算法执行后,分布差异明显变小。这表明MSA可以有效地选择更可靠或更接近真实查询标签分布的伪标签。
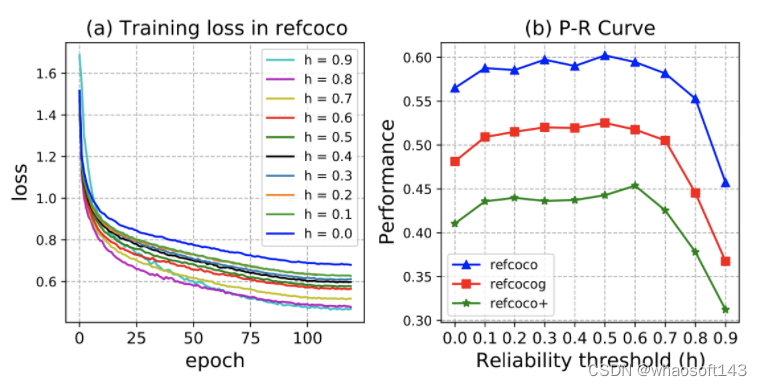
图7. 在RefCOCO/+/g数据集上执行SSA算法时,可靠性阈值 h 在 0.9 ~ 0 之间的结果。
E. 性能-可靠度(P-R)曲线与收敛性

F. 最不可靠样本分析
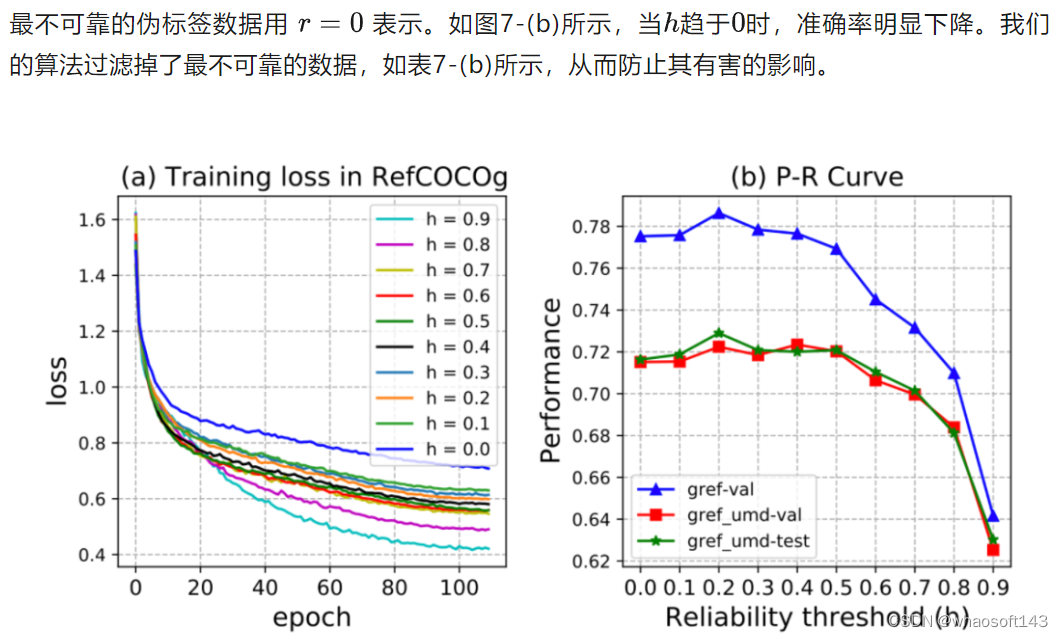
图7. 在RefCOCOg全监督数据集上执行SSA算法时,可靠性阈值 h 在 0.9 ~ 0 之间的结果。
G. 全监督设置下不可靠样本分析

图9. 最不可靠伪模板标签示意图

图10. 最不可靠伪关系标签示意图

图11. 最不可靠伪标题标签示意图
H. 不可靠伪语言标签的定性分析

在伪模板标签(图9)中,我们将不可靠数据大致分为四类:(a)、表达文本不明确,即缺乏唯一性; (b)、检测结果不正确导致的错误标签; (c)、先验信息不完整(例如,Pseudo-Q中定义的空间关系,如“前端”、“中间”、“底部”等不准确); (d)、其他问题,如偏僻的词汇、不重要或小规模的目标等。
在伪关系标签(图10)中,我们将不可靠数据大致分为(a)、模棱两可的表达文本和(b)、不显著或小尺度的目标。
在伪标题标签(图11)中,我们将不可靠数据大致分为(a)、描述整个图像的伪语言标签和(b)、边界框与标题之间的不匹配。
在各种类型的不可靠伪语言标签中,指代歧义的频率最高,特别是在具有相似分类目标的图像中。如果未来的研究希望进一步提高模型性能,解决模糊性是一个关键问题。
四、讨论
对性能提升的解释。 完成定位任务的关键在于理解语言表达文本与目标区域之间的对应关系。我们的方法为无监督设置引入了伪语言标签和伪标签质量评估方法。SSA和MSA算法实现了可靠和不可靠伪标签之间的最优平衡,使得基于CLIP的视觉定位模型学习更加稳定,进而显著提高了模型的泛化能力。
局限性。 我们提出了三种类型的伪标签,但它们的质量仍然很低。为了在可靠和不可靠的标签之间取得平衡,我们直接过滤了后者,并没有进一步使用它们,即使它们仍然可能包含有价值的信息。此外,SSA和MSA所采用的贪婪样本选择策略体现了训练成本和最优解之间的权衡。这些可以在未来的研究中进一步探索。
五、结论
在本文中,我们提出了一种新颖的CLIP-VG方法,该方法通过结合伪语言标签来实现CLIP到定位任务的无监督迁移。我们是第一次尝试在视觉定位任务中应用自步课程自适应的概念。随着下游视觉和语言文本多样性的不断演变,多源的伪标签很可能成为未来的趋势。 本文提出的多源伪语言标签和课程自适应的方法为未来的研究提供了一个新的视角。我们方法的思想简单而有效,未来可以作为即插即用的插件用于各种跨模态伪标签任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









