







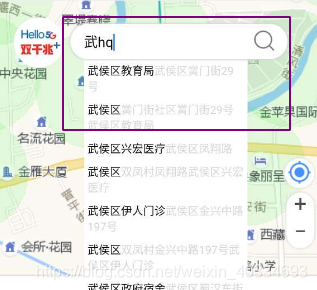
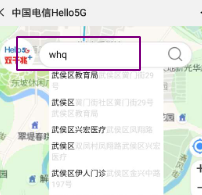
在这里如果你想通过elasticsearch使用中文+拼音的分词,但是对于大家来说中文分词,拼音分词单独使用的时候会能合理运用,但是如果混合搜索就会出现一些问题,如果你有图中的这个样子的需求,那本文就是能帮助到你的了
我在这里是通过修改拼音插件分词的源码之后进行打包上传,然后安装之后就可以进行图中的搜索了.
es的版本:
elasticsearch 6.8.4
如果你正好是6.8.4,你就可以通过百度云盘下载下来直接使用了.
链接: https://pan.baidu.com/s/1GVtK6LeFuYWfbL5B6BotVQ 提取码: k4i8 复制这段内容后打开百度网盘手机App,操作更方便哦
如果不是这个版本之后,那么就是需要自己修改源码并编译了,我是通过这位大佬的博客中,你们也可以查看这个大佬的代码提示修改,我觉得已经很详细了:
[es 修改拼音分词器源码实现汉字/拼音/简拼混合搜索时同音字不匹配]
接下来就是在安装好了之后就是可以了,接下来就是贴代码了
@Test
public void setPyService() {
String content = "武houq";
HighlightBuilder highlightBuilder = new HighlightBuilder();
/** 拼音字段 */
SearchRequestBuilder searchRequestBuilderPy =
client.prepareSearch("address").setTypes("address");
BoolQueryBuilder boolQueryBuilderPy = QueryBuilders.boolQuery();
highlightBuilder
.field("region")
.field("town")
.field("villag")
.field("road")
.field("plotName");
MatchPhraseQueryBuilder matchQueryBuilderRegionPy = QueryBuilders.matchPhraseQuery("region", content);
MatchPhraseQueryBuilder matchQueryBuilderTownPy = QueryBuilders.matchPhraseQuery("town", content);
MatchPhraseQueryBuilder matchQueryBuilderVillagPy = QueryBuilders.matchPhraseQuery("villag", content);
MatchPhraseQueryBuilder termQueryBuilderRoad = QueryBuilders.matchPhraseQuery("road", content);
MatchPhraseQueryBuilder matchQueryBuilderPnPy = QueryBuilders.matchPhraseQuery("plotName", content);
boolQueryBuilderPy
.should(matchQueryBuilderRegionPy)
.should(matchQueryBuilderTownPy)
.should(matchQueryBuilderVillagPy)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









