






前言
本文针对刚刚了解深度学习并希望快速上手的同学,将对代码各个模块的内容做简单的讲解。
深度学习训练框架
- 给自己的数据集制作标签
- 对数据集进行训练集测试集分组
- 如果数据是小样本,需要进行数据增强(扩充样本集)
- 数据集加载
- 数据集迭代器
- 对resnet网络输出层进行全连接更改
- 训练网络
深度学习训练流程
这里给刚入门深度学习的同学一个简单的官方深度学习实例:
def train(data):
#将原始特征(数据),标签输入以tensor(张量)形式传入gpu中
inputs, labels = data[0].to(device=device), data[1].to(device=device)
# 对输入进行前向传播计算每次的back
outputs = model(inputs)
#根据你自己选定的损失函数计算loss(通俗讲就是和正确分类的偏差值)
loss = criterion(outputs, labels)
#这步是将之前的梯度归零,为下次梯度更新做准备
optimizer.zero_grad()
#进行反向传播,也就是训练的过程
loss.backward()
#进行参数的梯度的更新
optimizer.step()
正式代码结构部分
1.数据标签制作
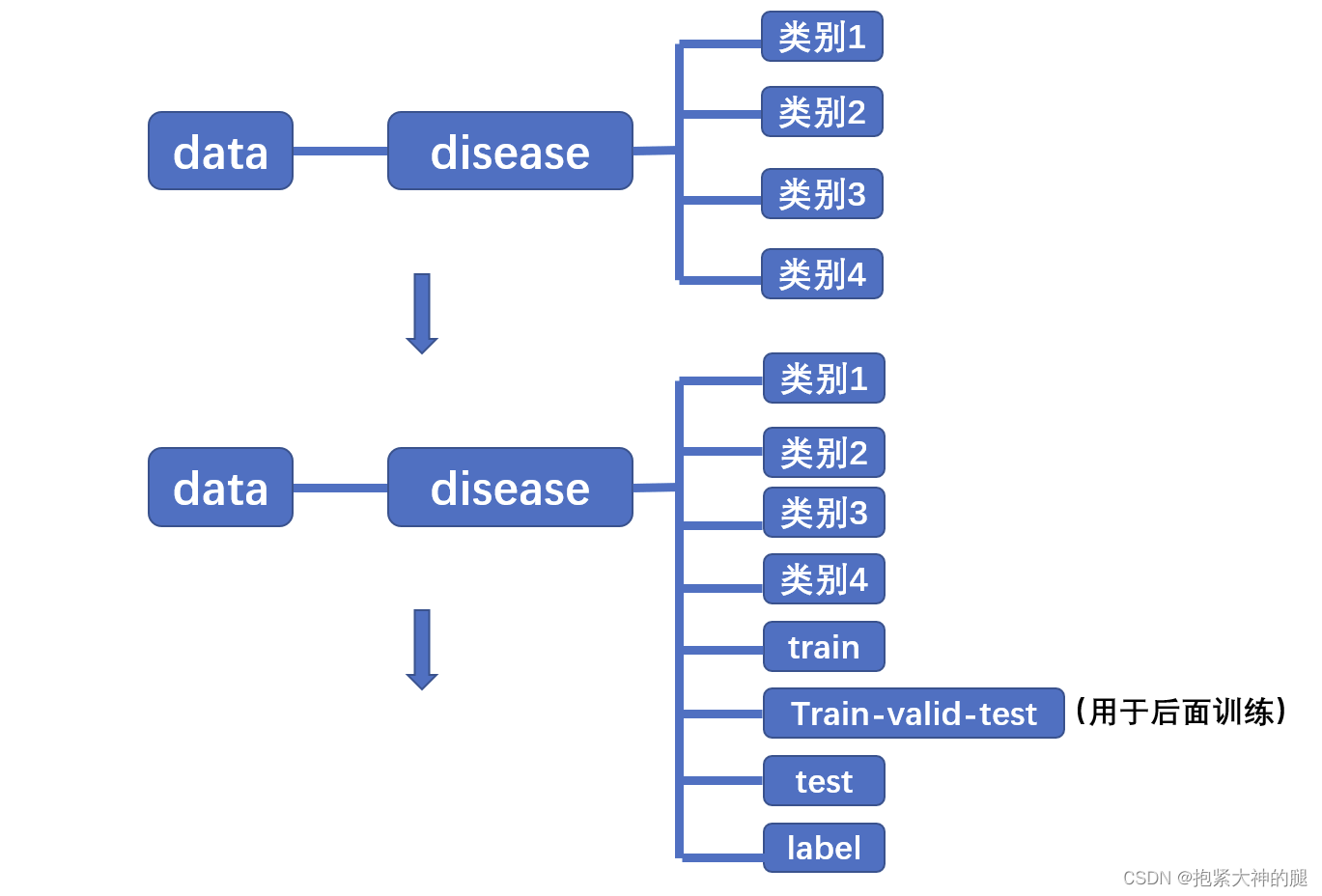
我这里用的水稻病害的数据集,一共四种病害类别
你的数据结构应该像下图,按照分类将每个照片归入类的文件夹,下图展示了初始文件结构和制作标签和数据分类之后的文件夹结构
 —
—
def make_label():
label={}
# 下面的是你的数据地址,要把你的主程序main放在data同级目录
#我这边的地址就是F:/文件夹名/data/Rice Leaf Disease Images
data_dir = os.path.join(os.getcwd(),'data','Rice Leaf Disease Images')
for file in os.listdir(data_dir):
temp_dir = os.path.join(data_dir,file)
for img in os.listdir(temp_dir):
name = img.split('.')[0]
label[name] = file
header = ['id','class']
csv_dir = os.path.join(data_dir,'label.csv')
with open(csv_dir,'w',newline='',encoding='utf-8') as f:
writer = csv.DictWriter(f,fieldnames=header)
writer.writeheader()
for i in range(len(label)):
temp_dic = {}
temp_dic['id'] = list(label.keys())[i]
temp_dic['class'] = list(label.values())[i]
writer.writerow(temp_dic)
return label
# 下面这行的地址也需要更改成你对应的数据地址,如果已经完成创建label则跳过
if os.access(os.path.join(os.getcwd(),'data','Rice Leaf Disease Images','label.csv'), os.F_OK):
pass
else:
make_label()
def copyfile(filename, target_dir):
"""Copy a file into a target directory.
Defined in :numref:`sec_kaggle_cifar10`"""
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
2.对数据集进行分组
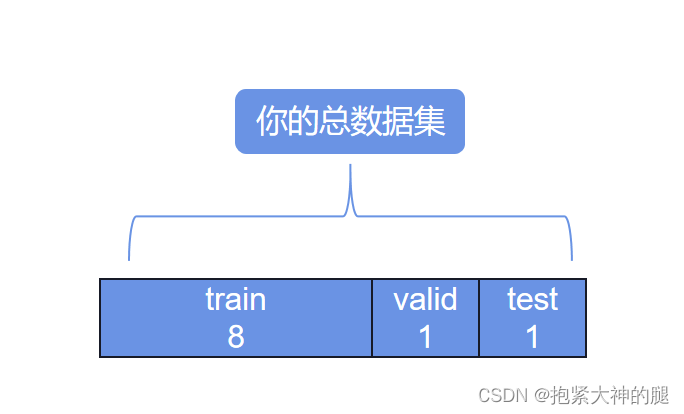
其中train用来训练,迭代多次,valid用来选择超参数(比如确定模型,学习率),test数据集用于测试,只使用一次。这里先手动分组train和test集,之后用ImageFolder模块可以自动生成一个新的文件夹用于正式测试。
def make_set():
data_dir = os.path.join(os.getcwd(), 'data', 'Rice Leaf Disease Images')
for dic in os.listdir(data_dir):
if dic != 'label.csv':
temp_dir = os.path.join(data_dir, dic)
for img in os.listdir(temp_dir):
r = random.random()
if r <=0.9:
fname = os.path.join(data_dir, dic,img)
copyfile(fname, os.path.join(data_dir, 'train'))
else:
fname = os.path.join(data_dir, dic, img)
copyfile(fname, os.path.join(data_dir, 'test'))
if os.access(os.path.join(os.getcwd(),'data','Rice Leaf Disease Images','train'), os.F_OK):
#如果已经完成set创建则跳过,上面的地址同样需要改成你自己的
pass
else:
make_set()
#-----------------数据分组
batchsize = 32
valid_ratio = 0.2
data_dir = os.path.join(os.getcwd(),'data','Rice Leaf Disease Images')
def reorg_data(data_dir,valid_ratio):
labels = d2l.read_csv_labels(os.path.join(data_dir,'label.csv'))
d2l.reorg_train_valid(data_dir,labels,valid_ratio)
d2l.reorg_test(data_dir)
reorg_data(data_dir,valid_ratio)
 在完成上述操作后你的文件夹会生成三个新文件(train,test和label.csv)
在完成上述操作后你的文件夹会生成三个新文件(train,test和label.csv)
3.数据增强
扩充数据集,同时把你的照片格式统一为resnet的输入尺寸
transform_train = transforms.Compose([
#随机裁剪
transforms.RandomResizedCrop(224),
#水平翻转
transforms.RandomHorizontalFlip(),
#随机亮度饱和度
transforms.ColorJitter(brightness=0.4,contrast=0.4,saturation=0.4),
#随机噪声
transforms.ToTensor(),
#标准化图层
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
transforms_test = transforms.Compose([
#增大至256再中心裁剪
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
4.数据集加载+数据迭代器
这部分用的是torchvision自带的模块,DateLoder和ImageFolder
train_set,train_valid_set = [ImageFolder(os.path.join(data_dir,'train_valid_test',folder),transform=transform_train) for folder in ['train','train_valid']]
valid_set,test_set = [ImageFolder(os.path.join(data_dir,'train_valid_test',folder),transform=transforms_test) for folder in ['valid','test']]
train_iter,train_valid_iter = [DataLoader(dataset,batchsize,shuffle=True,drop_last=True) for dataset in (train_set,train_valid_set)]
valid_iter = DataLoader(valid_set,batchsize,shuffle=True,drop_last=True)
test_iter = DataLoader(test_set,batchsize,shuffle=True,drop_last=True)
5.迁移学习resnet cifar10参数并改写网络最后全连接层
由于从头训练网络需要大量的样本及迭代次数,因此我们对网络进行预训练。通过网上下载resnet对cifar10数据集训练到的提取特征的参数,可以大大减少我们的网络收敛的时间。
def get_net(device):
finetune_net = nn.Sequential()
finetune_net.features = torchvision.models.resnet34(pretrained=True)
# 修改最后的全连接层,这里中的256可以改成任意数,最后的5是你的类别数
finetune_net.output_new = nn.Sequential(nn.Linear(1000,256),
nn.ReLU(),
nn.Linear(256,5))
# 选择cpu还是gpu
finetune_net = finetune_net.to(device)
# 冻结resnet前面参数
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
def try_gpu(i=0):
if torch.cuda.device_count() >= i+1:
return torch.device(i)
return torch.device('cpu')
device = try_gpu()
6.添加可视化组件,首先需要安装tensorboard(pip安装)
如果需要用gpu训练,需要下载python版本对应的cuda 和cudnn

def visiable_train(iter,train_loss=None,test_loss=None):
writer = SummaryWriter('log/log1')
if train_loss:
writer.add_scalar(tag='train loss',scalar_value=train_loss,global_step=iter)
if test_loss:
writer.add_scalar(tag='test_loss',scalar_value=test_loss,global_step=iter)
writer.close()
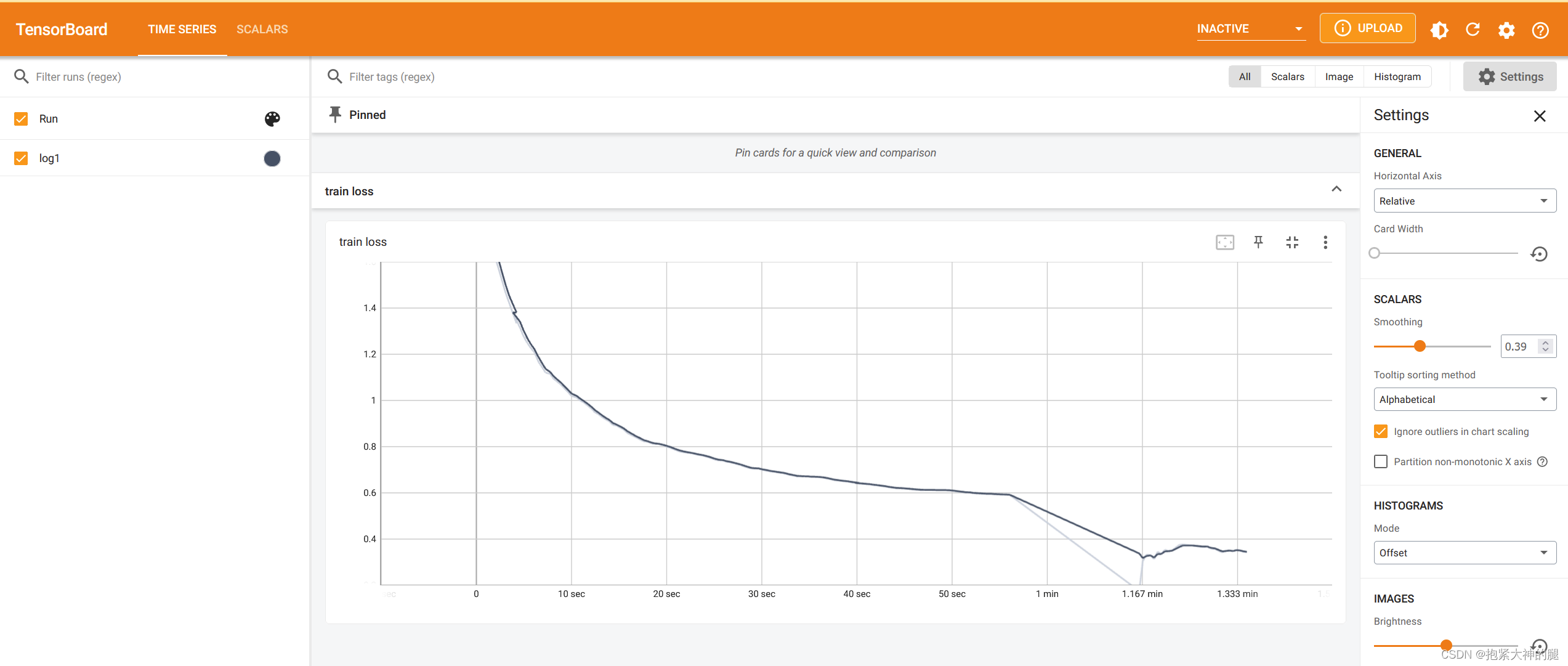
7.大功告成,训练网络实时查看train loss
tensorboard使用官方教程
https://pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html
安装好进入你的运行环境,cmd进入主程序文件夹后输入tensorboard --logdir=log
(log为之前设置的日志文件名)然后浏览器输入127.0.0.1:6060
参考部分及帮助阅读文档
数据集分组https://blog.csdn.net/qq_24884193/article/details/104071664
tensorboard使用明细https://blog.csdn.net/weixin_41809530/article/details/111253479
梯度裁剪https://blog.csdn.net/CVSvsvsvsvs/article/details/91137997
resnet网络最后全连接层调整https://zhuanlan.zhihu.com/p/35890660
cudnn和python版本对应https://blog.csdn.net/caiguanhong/article/details/112184290
完整代码地址
代码有点长,只选取了部分,这是代码地址仓库Github仓库。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









