






贝叶斯定理:
贝叶斯定理是关于随机事件A和B的条件概率(或边缘概率)的一则定理。其中P(A|B)是指在B发生的情况下A发生的可能性。贝叶斯定理也称贝叶斯推理,早在18世纪,英国学者贝叶斯(1702~1763)曾提出计算条件概率的公式用来解决如下一类问题:假设H[1],H[2]…,H[n]互斥且构成一个完全事件,已知它们的概率P(H[i]),i=1,2,…,n,现观察到某事件A与H[1],H[2]…,H[n]相伴随机出现,且已知条件概率P(A/H[i]),求P(H[i]/A)。以下是贝叶斯公式:
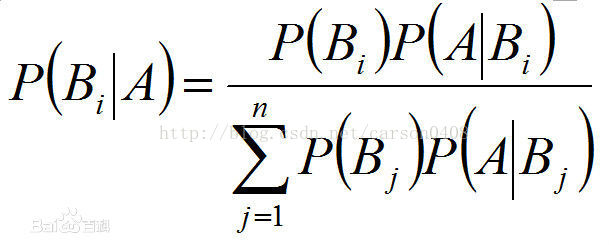

贝叶斯公式的例子:
1.一座别墅在过去的20年里,一共发生过2次被盗,别墅的主人有一条狗,狗平均每周晚上叫3次,在盗贼入侵时狗叫的概率为0.9,求狗叫时发生入侵的概率是多少。
令狗在晚上叫为A事件,则P(A)=3/7,盗贼入侵为B事件P(B)=2/(20*365)=1/3650,已知盗贼入侵狗叫的概率为0.9,即P(A|B)=0.9,根据贝叶斯公式:P(B|A)=P(A|B)P(B)/P(A)=(0.9*1/3650)/(3/7)=0.00058
2.现分别有A、B两个容器,在容器A里分别有7个红球和3个白球,在容器B里有1个红球和9个白球,现已知两个容器里任意抽出一个球,问这个球是红球且来自容器A的概率有多少?
假设摸到红球为事件A,来自A容器为事件B,P(A)=8/20,P(B)=1/2,P(A|B)=7/10表示这个球来自A容器是红球的概率,P(B|A)=P(A|B)/P(A)=(1/2)*(7/10)/(8/20)=7/8
朴素贝叶斯分类器:对已知类别,假设所有属性相互独立。求在属性影响概率最大的类别。
关键求出P(y1|x),......,p(yn|x):x表示属性集合,yi指的是类别,即表示属性对不同类别的影响概率,求出概率最大的即为相应的类别。根据公式P(yi|x)=P(x|yi)/P(x),因为对于每种类别,x都相同,即P(x)都相同,所以求P(yi|x)最大,就是求P(x|yi)最大。而P(x|yi)可以转化为P(x|yi)=P(x1|yi)*P(x2|yi)*.......*P(xn|yi),而P(xj|yi)表示yi类别下,xj存在的概率。
根据以上过程可以将朴素贝叶斯分类器对数据集处理可以分为三步骤:
1.预处理:对数据集按特征属性进行划分,形成训练样本集合,分类器的质量由特征属性、特征属性划分以及训练样本质量决定
2.训练分类器:计算每个类别在训练样本中出现的频率以及每个特征划分时每个类别的条件概率估计。输入是特征属性和训练样本,输出是分类器
3.进行数据预测,模型应用。输入是分类器和待分类项,输出是待分类项与类别的关系。
以上分类器训练模型以及模型应用调用的是朴素贝叶斯算法:其算法实现的步骤:
1.计算先验概率的估计值以及条件概率的估计值:
2.对于给定的实例x进行计算不同类别下的概率
3.比较各个概率值,求最大值,返回最大值对应的分类
朴素贝叶斯分类器的优缺点:
优点:
1.朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定分类效率
2.朴素贝叶斯模型所需估计的参数很少,对缺失数据不太敏感,算法比较简单
3.无需复杂的迭代求解框架,适用于规模巨大的数据集
缺点:
1.属性之间的独立性假设往往不成立(可考虑用聚类算法先将相关性比较的属性进行聚类)
2.需要知道先验概率,分类决策存在错误率
朴素贝叶斯分类器的应用:新闻分类、病人分类、账号分类、性别分类、投资决策
贝叶斯判定准则:为最小化总体风险,只需在每个样本上选择能使条件风险R(c|x)最小的类别标记:
/-------------------------------极大似然估计---------------------------------/
估计类的常用策略:先假定其具有某种确定的概率分布形式,再基于训练样本对概率分布的参数进行估计。即概率模型的训练过程就是参数估计过程。
参数估计两大学派:频率主义学派和贝叶斯学派。
(1)频率主义:参数虽然未知,但却是客观存在的固定值,因此,可通过优化似然函数等准则来确定参数值(最大似然)。(2)贝叶斯学派:参数是未观察到的随机变量,本身也可以有分布,因此,可假定参数服从一个先验分布,然后基于观察到的数据来计算参数的后验分布。
/*-----------------------------朴素贝叶斯------------------------------------*/
朴素贝叶斯:
(1)思想:对于给定的待分类项x,通过学习到的模型计算后验概率分布,即:在此项出现的条件下各个目标类别出现的概率,将后验概率最大的类作为x所属的类别。后验概率根据贝叶斯定理计算。
(2)关键:为避免贝叶斯定理求解时面临的组合爆炸、样本稀疏问题,引入了条件独立性假设。
(3)工作原理:
(4)工作流程:1)准备阶段:确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本。 2)训练阶段:对每个类别计算在样本中的出现频率p(y),并且计算每个特征属性划分对每个类别的条件概率p(yi | x); 3)应用阶段:使用分类器进行分类,输入是分类器和待分类样本,输出是样本属于的分类类别。
采用了属性条件独立性假设,
d:属性数目,xi为x在第i个属性上的取值。
贝叶斯估计:
极大似然估计中,直接用连乘计算出的概率值为0,该样本的其他属性值将失效。为了避免其他属性携带的信息被训练集中未出现的属性值“抹去”,在估计概率值需要“平滑”,
优点: 高效、易于训练。对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点: 分类的性能不一定很高,对输入数据的表达形式很敏感。(离散、连续,值极大之类的)
Note:为什么属性独立性假设在实际情况中很难成立,但朴素贝叶斯仍能取得较好的效果?
1)对于分类任务来说,只要各类别的条件概率排序正确、无需精准概率值即可导致正确分类;
2)如果属性间依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独立性假设在降低计算开销的同时不会对性能产生负面影响。
/*---------------------------半朴素贝叶斯-----------------------------------*/
提出:现实任务中,条件独立性假设很难成立,于是,人们对属性独立性假设进行一定程度的放松。
想法:适当考虑一部分属性间的相互依赖信息,从而既不需进行联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。
/*-----------------------------贝叶斯网------------------------------------*/
/*-------------------------------面试篇---------------------------------*/
1、贝叶斯分类器与贝叶斯学习不同:
前者:通过最大后验概率进行单点估计;后者:进行分布估计。
2、后验概率最大化准则意义?
3、朴素贝叶斯需要注意的地方?
(1)给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。
(2)计算要点:
4、经典提问:Navie Bayes和Logistic回归区别是什么?
前者是生成式模型,后者是判别式模型,二者的区别就是生成式模型与判别式模型的区别。
1)首先,Navie Bayes通过已知样本求得先验概率P(Y), 及条件概率P(X|Y), 对于给定的实例,计算联合概率,进而求出后验概率。也就是说,它尝试去找到底这个数据是怎么生成的(产生的),然后再进行分类。哪个类别最有可能产生这个信号,就属于那个类别。
优点:样本容量增加时,收敛更快;隐变量存在时也可适用。
缺点:时间长;需要样本多;浪费计算资源
2)相比之下,Logistic回归不关心样本中类别的比例及类别下出现特征的概率,它直接给出预测模型的式子。设每个特征都有一个权重,训练样本数据更新权重w,得出最终表达式。梯度法。
优点:直接预测往往准确率更高;简化问题;可以反应数据的分布情况,类别的差异特征;适用于较多类别的识别。
缺点:收敛慢;不适用于有隐变量的情况。














 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









