






一种全新掩码生成方式下的特征蒸馏-MasKD。 语义掩码知识蒸馏,检测、分割、分类三大任务领先
链接:https://arxiv.org/pdf/2205.14589.pdf
论文代码:https://github.com/hunto/MasKD
特征蒸馏作为通用且有效的蒸馏方式,可以提取注意力信息、上下文信息以及关联的特征,相比单一的标签蒸馏,更有丰富的维度优势。然而学生一成不变地学习教师的特征并不是最佳方案,原因是每个像素点包含着不同的语义信息,对预测有着不同的贡献。例如,Mimicking只对学生的区域建议网络(RPN, Region Proposal Network)提出的正样本区域进行蒸馏,FGFI和TADF使学生模仿靠近标签前景框附近的有价值区域,Defeat借助标签前景框将前景和背景解耦,并赋予两者不同的蒸馏注意力。上述方法有着共同的特点:依赖于标签边界框的先验。但是,并不是所有在标签边界框内的像素点都是必要且对蒸馏是有价值的。我们在Faster RCNN-R101 neck的5个stage截取特征图可视化,我们发现:(1)每个边界框内的激活区域(红色区域)是远小于该框的(2)不同的维度或网络层,甚至是在特征金字塔不同的尺度,蒸馏的兴趣域都是不同的(3)未被边界框标注的物体会被当成“背景”降权蒸馏,而实际上他们也包含着关键性区别特征的信息(如第一行中仍有一些炊具未被标注,但它们却包含了前景拥有的特征)。
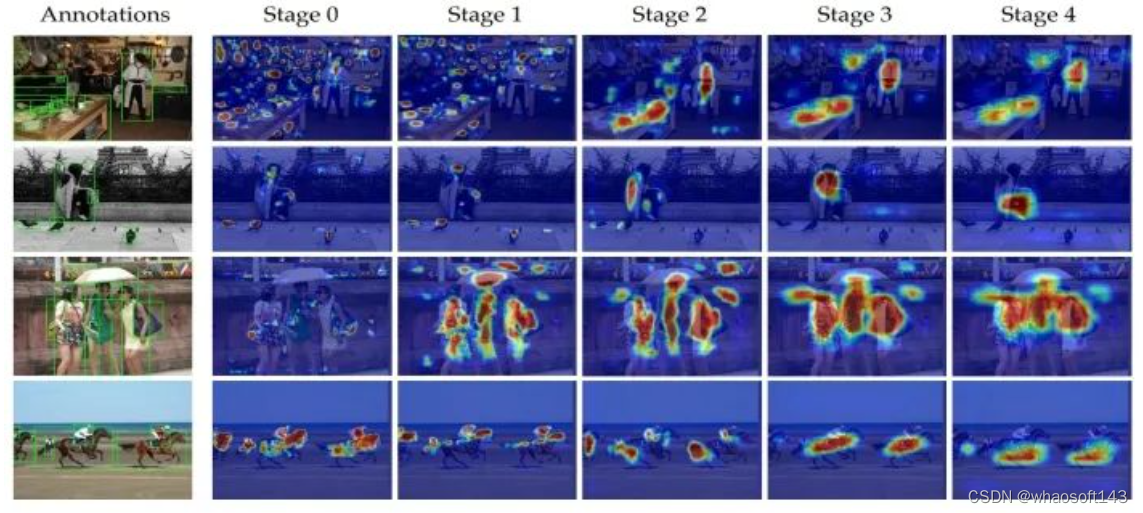
因此我们应该摒弃标签边界框作为特征蒸馏的掩码,而是依据细粒度的像素语义信息,自适应地选择蒸馏兴趣区域,此时将问题转化为:学生模型在特征蒸馏过程中,应该学习教师模型哪些像素点以及学习到什么样的程度。
方法
1 Learning Masks with Receptive Tokens

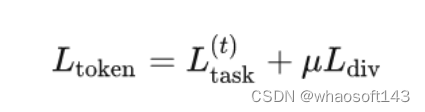
2 Distillation with Learned Masks
(2.1)学习掩码Token后,我们获得了多组不同的蒸馏兴趣域,但是他们之间的重要程度是不同的,例如我们会把更多的注意力放在前景物体而非背景噪声,因此我们提出Mask weighting module(图2(a))。对于每张特征图中的每一张掩码Token,掩码加权模块会计算出对应的权重,在蒸馏时相乘表其重要程度。
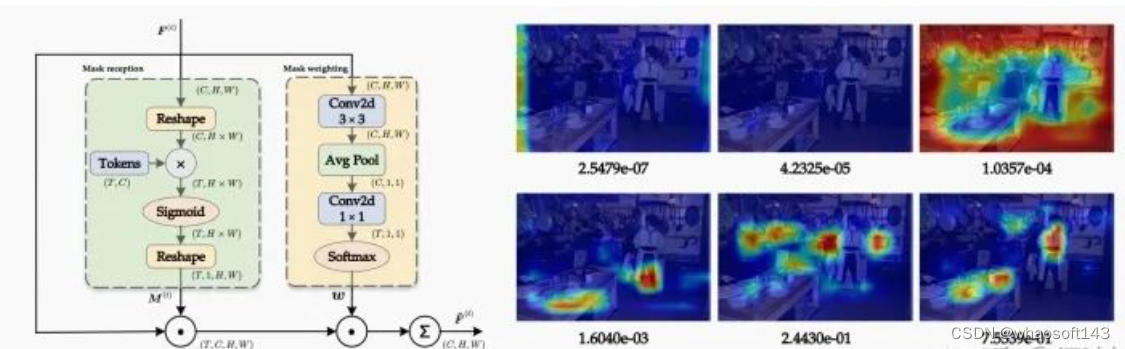
如图2(b)所示,我们截取FPN最后一个stage兴趣域可视化,并标记其对应的重要程度。我们发现:包含背景区域以及无意义空区域的掩码被赋予极小的权重(e-07),而与真实物体联系紧密的掩码则有着更大的权重(e-01),进一步证明了掩码加权模块的有效性。借助学习到的语义Mask以及掩码重要性,我们自然地采用这些重要性权重作为每个掩码的损失权重。
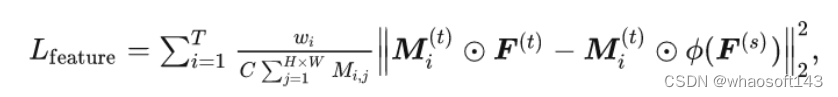
(2.2)此外,目前的掩码仅来自于教师的语义信息,会存在如下问题:
- 在特征蒸馏中,由于教师与学生的能力差距,学生很难完全地精细重建教师所有的特征图,强迫学生向老师学习,只会干扰对难以重建的像素的优化;
- 存在一些对学生没有意义的像素(如噪声),若对它们进行不必要的重构会削弱蒸馏性能。
因此,我们通过基于学生的语义掩码来优化上述问题,因此,最终的掩码特征蒸馏损失如下式所示:
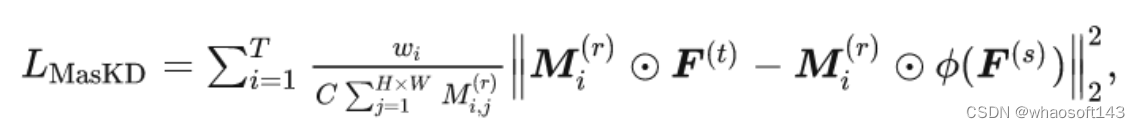
在实际蒸馏过程中,为了避免学生掩码在早期训练阶段错误掩盖关键区域,我们设置了Warmup阶段(Epochs=1)
(2.3)学生知识蒸馏的损失函数如下式所示,在特征蒸馏的基础上添加了回归蒸馏(L1 Loss)
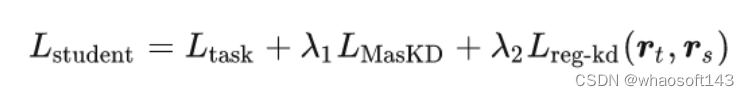
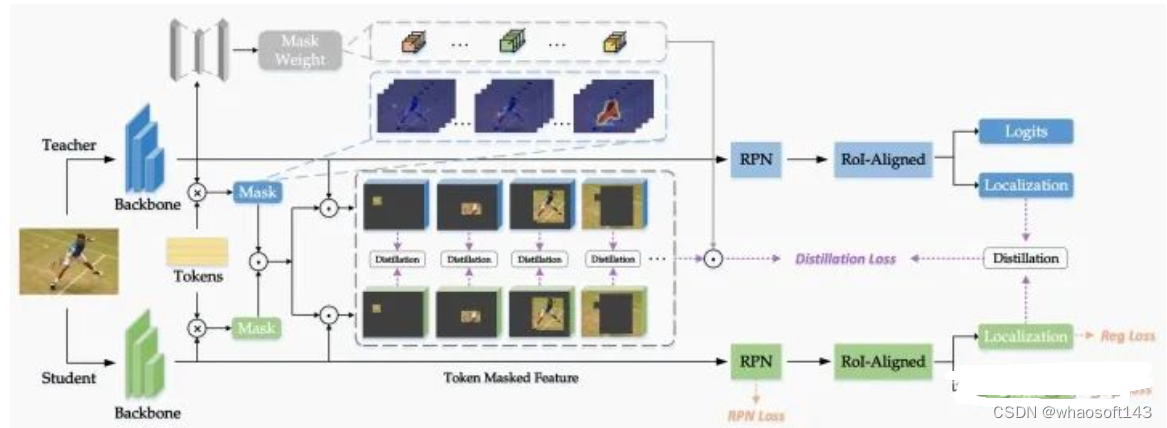
MasKD的算法架构图:首先,冻结教师权重,根据教师的语义特征学习生成黄色模块(Receptive Tokens);接着,Tokens与教师特征图进行矩阵乘,生成基于教师的语义掩码 ,再与学生特征图进行矩阵乘,生成基于学生的语义掩码;然后,两者进行对应元素相乘,选取教师兴趣域与学生兴趣域的交集,在语义掩码下,进行一一对应的特征蒸馏;最后,计算各掩码的重要性作为各蒸馏子损失的权重,进行加权得到最后的特征蒸馏损失。
实验
Detection
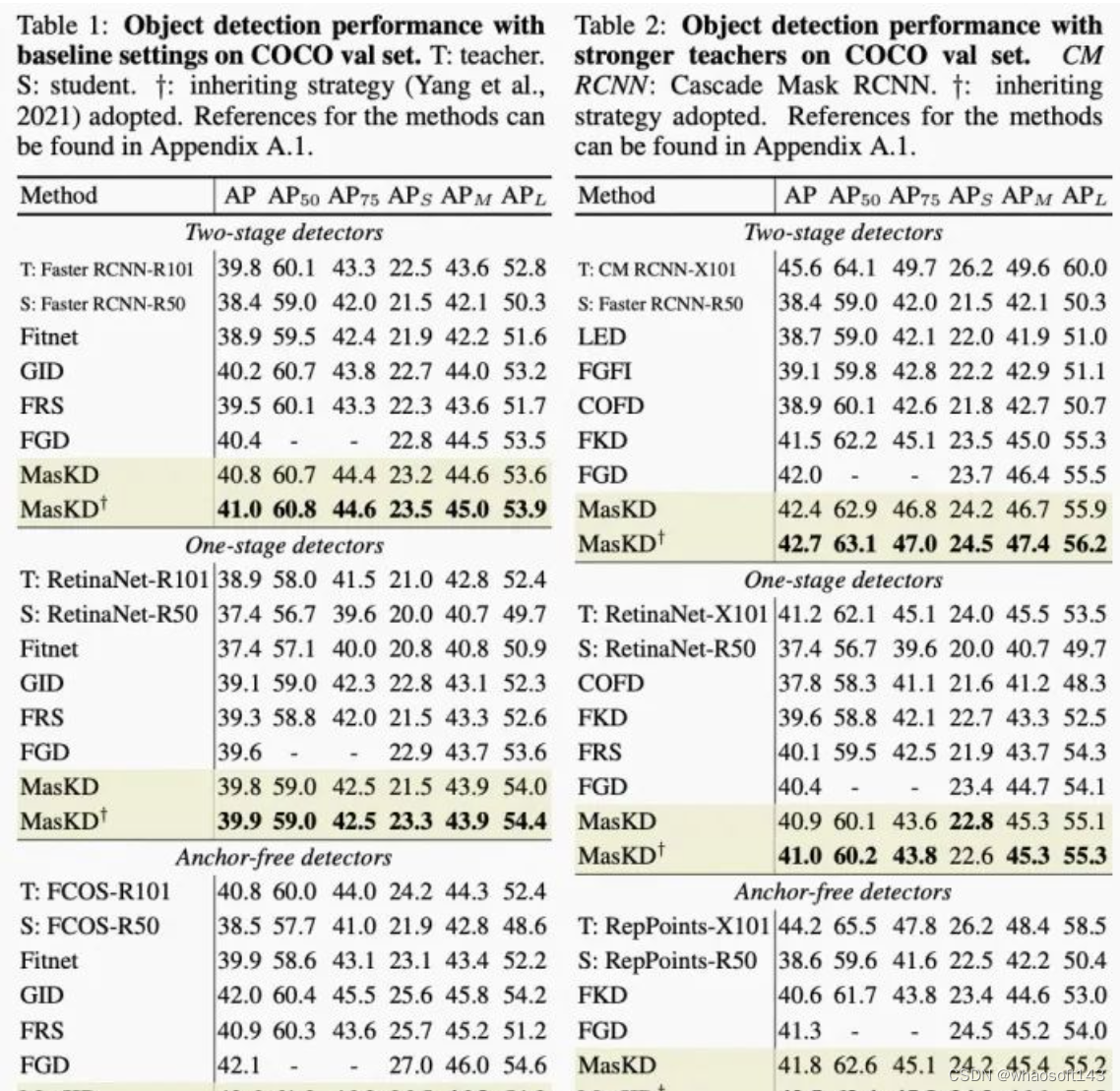
为了验证MasKD方法在目标检测任务上的有效性,本文在目标检测数据集COCO上进行精度验证,包含不同的检测框架与教师模型。
首先,我们以ResNet-101(R101)作为基础教师的主干,ResNet-50(R50)作为学生模型的主干,并采用以下三种检测框架进行试验:(1)两阶段检测器 Faster-RCNN(2)一阶段检测器RetinaNet(3)无锚框检测器FCOS。接着,我们以ResNeXt-101(X101)作为较强教师的主干,ResNet-50(R50)作为学生模型的主干,并采用以下三种检测框架进行试验:(1)两阶段检测器Cascade Mask RCNN(2)一阶段检测器RetinaNet(3)无锚框检测器RepPoints。如下表所示,MasKD大幅超越了FGD,多个学生模型的涨幅达到0.5 AP。
Segmentation
为了验证MasKD方法在语义分割任务上的有效性,本文在分割数据集Cityscapes上进行精度验证,包含不同的检测框架与教师模型。如下表所示,MasKD大幅超越了CIRKD与CWD,最高涨幅达到5.77 mIoU。
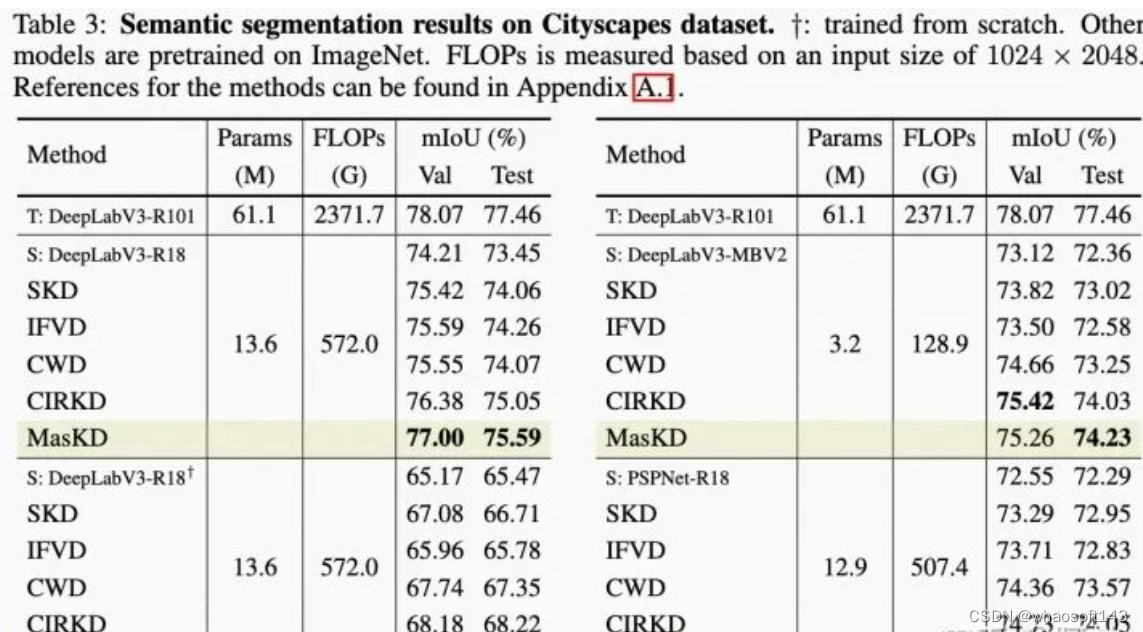
图5
Ablation Study
为了研究MasKD中各个模块对蒸馏性能的影响,如图6所示,本文进行了组件消融实验。我们以 Cascade Mask RCNN-X101作为教师,Faster RCNN-R50作为学生,训练时间为12 Epochs,知识迁移过程中仅涉及特征蒸馏。
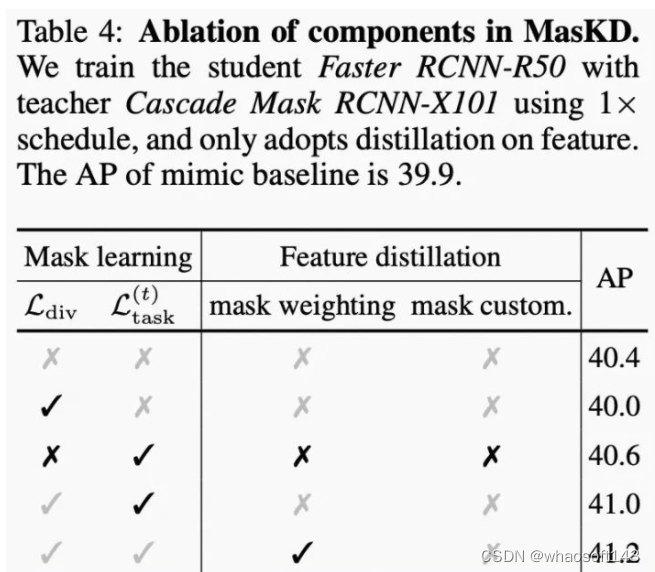
(1) 随机区域掩码的特征蒸馏。与MSE基线(39.9% AP)相比,使用随机初始化的掩码进行蒸馏仍可以获得精度上的提升(+0.5% AP),它具有较弱的捕获语义特征的能力(如图7(a)所示)。
(2) + 掩码区分损失函数。如图7(b)所示,在没有教师任务损失监督的情况下,学习到的掩码也可以获得相当好的语义信息,但是由于缺乏任务知识(例如它将背景和前景像素混淆到同一掩码中),精度甚至比随机掩码差0.4% AP,表明与任务相关的掩码在MasKD中很重要。
(3) + 教师任务损失函数。在教师任务损失的监督下,可以生成对任务更有意义的掩码,因此与随机掩码相比,可以提升0.6% AP。
(4) + 自适应掩码权重。加权掩码模块为蒸馏在区域选择上提供了更好的平衡,因此获得0.2% AP的增益。
(5) + 基于学生语义的掩码。我们通过基于学生语义的掩码来微调原本的掩码,即蒸馏兴趣域应由教师和学生认为都重要的像素点组成;结果表明,它可以获得0.2% AP的提升。
(6) 与MSE基线(39.9% AP)相比,由上述模块组成的MasKD最终可实现1.5% AP(41.4% AP 与39.9% AP)的显著精度提升。
















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









