






1|0写在前面
前段时间跟领导讨论技术债概念时不可避免地提到了代码的质量,而影响代码质量的因素向来都不是单一的,诸如项目因素、管理因素、技术选型、人员素质等等,因为是技术债务,自然就从技术角度来分析,单纯从技术角度来看代码质量,其实又细分很多原因,如代码设计、代码规范、编程技巧等等,但我个人觉得这些都是技,并不是代码混乱的根,代码之所以混乱的根要从最基础的层面说起,也就是代码架构。
但是好像代码架构也不像是技术选型的产物,它更像是“润物细无声”的环境影响产物,一个Java Web项目,不谈一个企业,甚至整个行业都有一个共识,应该是Controller、Service、Dao那一套,从代码目录结构到内部细节编写,也不知道是MVC架构的宣传深入人心还是培训机构或者企业培训的连带效应导致的这种浑然天成的共识。就是这种浑然天成的共识导致了一个很奇怪的现象,那就是 :使用标榜面向对象的Java语言所开发的项目却十分的不面向对象。这里也不是说面向对象就比面向过程要强,只是各自适用的领域不一样。超过操作系统到应用层级的应用,不论从需求延申角度、系统规模角度、落地实现角度、扩展维护角度,面向对象都要更好一些。
这也是Java这门语言高居榜首的理由。 Java自诞生之初,各自资料、书籍无一不是在讲它的面向对象特性和面向对象设计,随后的领域驱动设计更是面向对象的集成方法论,在这么多buff的加持下,为什么还是会出现使用面向对象去写面向过程的代码呢?答案就在上面的共识里,好像Java项目的开发和贫血模型一直是强绑定的。
严格来讲,概念上领域驱动其实只有一种概念,并没有贫血充血之分,DDD官方概念中并没有明确定义所谓的贫血模式,贫血模式的诞生其实是对于标准领域驱动的简化,而与之对应的标准的DDD就成了充血。
2|0贫血模型
贫血模式很多人不陌生, 即上文提到的传统的Controller、Service、Dao的框架基础之上,配合以Java的对象实体类概念,但实体类仅有属性和属性的get和set方法,在整个系统中,对象几乎只作传输介质的作用,不会影响到层次的划分,业务逻辑多集中在Service中;随之后续的数据库技术、ORM框架等等,都在这一体系上继续垒加,形成了当下最高复制率的JavaWeb项目结构。
还是转账这个经典的例子,使用贫血实现:
/**
* 账户业务对象
*/
public class AccountBO {
/**
* 账户ID
*/
private String accountId;
/**
* 账户余额
*/
private Long balance;
/**
* 是否冻结
*/
private boolean isFrozen;
public String getAccountId() {
return accountId;
}
public void setAccountId(String accountId) {
this.accountId = accountId;
}
public Long getBalance() {
return balance;
}
public void setBalance(Long balance) {
this.balance = balance;
}
public boolean isFrozen() {
return isFrozen;
}
public void setFrozen(boolean isFrozen) {
this.isFrozen = isFrozen;
}
}
/**
* 转账业务服务实现
*/
@Service
public class TransferServiceImpl implements TransferService {
@Autowired
private AccountMapper accountMapper;
@Override
public boolean transfer(String fromAccountId, String toAccountId, Long amount) {
AccountBO fromAccount = accountMapper.getAccountById(fromAccountId);
AccountBO toAccount = accountMapper.getAccountById(toAccountId);
/** 检查转出账户 **/
if (fromAccount.isFrozen()) {
throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN);
}
if (fromAccount.getBalance() < amount) {
throw new MyBizException(ErrorCodeBiz.INSUFFICIENT_BALANCE);
}
fromAccount.setBalance(fromAccount.getBalance() - amount);
/** 检查转入账户 **/
if (toAccount.isFrozen()) {
throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN);
}
toAccount.setBalance(toAccount.getBalance() + amount);
/** 更新数据库 **/
accountMapper.updateAccount(fromAccount);
accountMapper.updateAccount(toAccount);
return Boolean.TRUE;
}
}
2|1贫血模型的本质
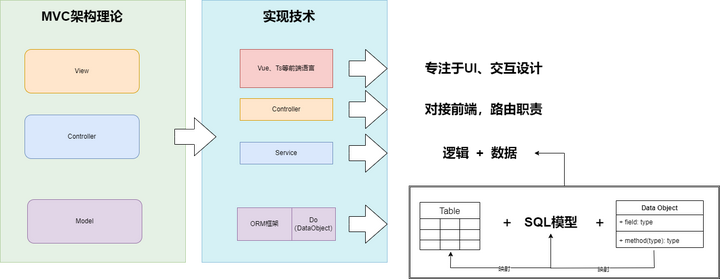
贫血模式本质是在架构指导下技术框架趋于成熟的演进产物;换句话说是MVC架构随着技术的发展而不断变体而来。MVC的初衷是一个三层架构,即包含数据结构和业务逻辑的模型Model层、应用程序的用户界面(UI)展示与交互的视图层View、用于协调Model与View的剧中调度层Controller,旨在将数据、逻辑和交互解耦。但伴随着ORM框架、Web框架的进步,慢慢形成了Controller、Service、Dao(ORM)的格局,之后前后端分离的浪潮袭来,导致Controller变成了路由,Dao变成了JDBC的简化,Do变成了数据结构,头和尾都明确定位的夹击下,所有的业务功能只能聚焦于中间的Service里,需求大都集中在了Service,“Service用来承载业务逻辑”的说法更加助长了设计懒惰,形成了 “service=数据+逻辑”的风格,学过C语言的或多或少都听过一句“程序=数据+算法”,所以贫血就是在输入输出都固定框架模式下的面向过程。
2|2贫血模型下的开发特点
贫血模式的service层的定义导致它的底层思维是 “程序=算法+数据” ,与之而来的开发流程或者说特点也就十分明了了。即 功能与数据密不可分、代码与数据密不可分。最后面向数据编程。

聚焦功能忽视业务
长期使用贫血模式开发的人员,眼里看到的多是UI原型或者功能,对于系统的全貌,永远是站在功能的角度去描述和了解。往往专注于功能的开发,尽可能地去简化实现,点到实现功能为止,不做过多的设计与业务的扩展思考。实现往往是单维度的,仅仅是为了满足某个功能或某个页面,当需求分析和系统规划不够优秀时,后续功能开发时,不可避免会陷入前后矛盾的情景。
面向数据开发
在接手系统时,程序员一般先看两部分,数据库里的表和功能,最后才是代码,或者接到需求时,首先做的就是根据UI或者产品的描述去设计存储用的表结构,然后再基于表结构去进行代码设计。也就是说,在实现角度,数据库的表结构才是根基。
另一方面就是SQL建模,其实也可以说是重SQL轻代码,绝大多数做Java Web开发地研发人员从根据需求设计表结构、到实现时进行SQL建模十分娴熟,甚至我见过很多高手,能用一个SQL完成功能开发,把功能和数据的关系极尽所能地压缩到一个或者几个SQL中,代码反而只是一个传输媒介。
贫血模式的开发者倾向于将注意力集中在数据上,他们直接在数据表上建模。语言框架更多的功能在于数据库的访问和UI的绘制,虽然语言可能是Java这种完全面向对象语言,但其实应用里并没有什么客观对象,除了数据库的容器和访问者
2|3贫血模型的合理性
说到这好像显得贫血模式一无是处,其实也不绝对,毕竟 “存在即合理”,裁剪了繁重体系的领域驱动后,贫血模式就变得十分轻便,本身面向过程的特点又让它复制性和落地效率十分突出,开发人员只需要UI页面和数据库的表结构,随便一个研发都可以快速接手并完成一个功能的开发 ,降低了软件设计的复杂度,这恰恰和很多开发团队快速响应的诉求不谋而合。
贫血得以盛行的另一个助力就是Spring,Spring家族作为Java系的行业老大哥框架,积累和沉淀非常丰富,各方面已经封装的很全面,所以留出的“自由度”就比较少,它的宗旨就是让开发人员减少重复造轮子,仅仅专注功能的开发就好;这些特点使得Spring本身就带有限制性质,例如Spring的根基Bean管理机制,把对象的管控牢牢把握在框架中,这种将实体类的管理也交由Spring本身也降低了二次开发时面向对象的属性,导致在Spring中进行bean之间的引用改造会面临大范围的bean嵌套构造器的调用问题。所以使用Spring也就大概率默认使用贫血。
2|4贫血模型的问题
不可否认,面对大多数简单而生命周期短暂的项目面向数据开发是一种高效的方式,且当需求发生变动,Service按部就班地追加相应的逻辑也是可以快速响应,可是这些都是建立在系统简单、项目周期短的前提下,一旦面临长生命周期且业务复杂的大型系统,贫血模式的问题就是:
- 随着系统体积的增长和需求的蔓延,部分功能设计问题显露,贫血模式下的代码特点难以快速重构来响应这一级别的诉求
- 面向过程的形式,让代码陷入 “又臭又长的if else”死胡同,随着不断地开发,维护和改动成本指数级上涨
- 长时间的“水多了加面,面多了加水”的开发习惯,团队人员思维固化,难以提出有效地优化或改进,恶性循环
3|0充血模型
充血简单来讲就是OO思想的体系方法论,相比贫血的面向数据,它提出领域的概念,即将业务和数据拆开,对业务部分进行领域划分并进行OOA,代码上更重抽象出的领域实体类,将业务逻辑和判定等内容均内聚到实体类中,Service层仅仅充当组合实体对象的画布,负责简单封装部分业务和事务权限管理等;
为了更直观感受,使用充血模型,对上面的例子进行修改:
/**
* 账户业务对象
*/
public class AccountBO {
/**
* 账户ID
*/
private String accountId;
/**
* 账户余额
*/
private Long balance;
/**
* 是否冻结
*/
private boolean isFrozen;
/**
* 出借策略
*/
private DebitPolicy debitPolicy;
/**
* 入账策略
*/
private CreditPolicy creditPolicy;
/**
* 出借方法
*
* @param amount 金额
*/
public void debit(Long amount) {
debitPolicy.preDebit(this, amount);
this.balance -= amount;
debitPolicy.afterDebit(this, amount);
}
/**
* 转入方法
*
* @param amount 金额
*/
public void credit(Long amount) {
creditPolicy.preCredit(this, amount);
this.balance += amount;
creditPolicy.afterCredit(this, amount);
}
public boolean isFrozen() {
return isFrozen;
}
public void setFrozen(boolean isFrozen) {
this.isFrozen = isFrozen;
}
public String getAccountId() {
return accountId;
}
public void setAccountId(String accountId) {
this.accountId = accountId;
}
public Long getBalance() {
return balance;
}
/**
* BO和DO转换必须加set方法这是一种权衡
*/
public void setBalance(Long balance) {
this.balance = balance;
}
public DebitPolicy getDebitPolicy() {
return debitPolicy;
}
public void setDebitPolicy(DebitPolicy debitPolicy) {
this.debitPolicy = debitPolicy;
}
public CreditPolicy getCreditPolicy() {
return creditPolicy;
}
public void setCreditPolicy(CreditPolicy creditPolicy) {
this.creditPolicy = creditPolicy;
}
}
/**
* 入账策略实现
*/
@Service
public class CreditPolicyImpl implements CreditPolicy {
@Override
public void preCredit(AccountBO account, Long amount) {
if (account.isFrozen()) {
throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN);
}
}
@Override
public void afterCredit(AccountBO account, Long amount) {
System.out.println("afterCredit");
}
}
/**
* 出借策略实现
*/
@Service
public class DebitPolicyImpl implements DebitPolicy {
@Override
public void preDebit(AccountBO account, Long amount) {
if (account.isFrozen()) {
throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN);
}
if (account.getBalance() < amount) {
throw new MyBizException(ErrorCodeBiz.INSUFFICIENT_BALANCE);
}
}
@Override
public void afterDebit(AccountBO account, Long amount) {
System.out.println("afterDebit");
}
}
/**
* 转账业务服务实现
*/
@Service
public class TransferServiceImpl implements TransferService {
@Resource
private AccountMapper accountMapper;
@Resource
private CreditPolicy creditPolicy;
@Resource
private DebitPolicy debitPolicy;
@Override
public boolean transfer(String fromAccountId, String toAccountId, Long amount) {
AccountBO fromAccount = accountMapper.getAccountById(fromAccountId);
AccountBO toAccount = accountMapper.getAccountById(toAccountId);
//此处采用轻量化地方式解决了自身面向对象和Spring的bean管理权矛盾
fromAccount.setDebitPolicy(debitPolicy);
toAccount.setCreditPolicy(creditPolicy);
fromAccount.debit(amount);
toAccount.credit(amount);
accountMapper.updateAccount(fromAccount);
accountMapper.updateAccount(toAccount);
return Boolean.TRUE;
}
}
3|1充血模型的开发特点
抽象业务

相比于贫血聚焦于功能、UI页面,充血模式在面对设计时,需要更上升一层,聚焦于业务。将业务内容抽象出业务对象、对象关系、业务流程、对象依赖,以排列组合对象来满足业务需求。面对需求,需要层层分析,设计,模型场景推演,做到重业务对象,轻数据,从而实现业务、功能、代码、数据的清晰划分,避免直译式的粘连耦合实现。
通过领域概念将业务与技术分离

领域驱动中突出领域的概念,包含:通用域、支撑域、核心域三部分,其中通用域和支撑域则是纯技术流和通用内容,包括持久化、通信技、安全、性能、通用组件、规则等,核心域则是具体业务分析得出的业务块,其中包含通用的业务语言、领域内的上下文、复杂变化的业务逻辑等。通用域和支撑域负责数据管理、包装接口、绘制界面、收接消息等系统的基本技术能力,以此来支撑核心域的业务流转、运作。 通用域、支撑域不与核心域耦合,让技术归技术、业务归业务,做到技术和业务的分离。
3|2充血模型的问题
很多书籍和资料都是在说充血模型是解决贫血模型的良药,其实也过于吹捧了,之前也提到了,贫血模型有其存在的必要性,充血模型和贫血模型只是适用范围不同,如果贫血模型的缺点都是由于应用场景导致,那充血确是良药。但如果单纯是管理问题、团队人员技术问题导致的问题,那强行套用充血才是灾难,至于贫血换充血的理由,会在后面提到。这里单纯以批评视角说一说充血的问题。
单纯看充血模型存在的问题,就两点:
- 理论过于理想,实践较为困难
- 边界难以把控
其实这两点归于一点也不为过,那就是充血模型的实践土壤过于苛刻,因为其脱身于面向对象,着重以面向对象思想解决系统开发中熵增的问题,由此诞生了非常繁重的体系理论,而每一处体系理论都透露着对于团队人员素质以及业务场景理解的高要求;对于团队人员素质,这一点是最难的,因为在一个群体中很难把每个研发对于面向对象的理解拉到同一个维度,只能是不要有太大偏差。其次就是设计者很容易陷入到 “设计师的锤子”理论中,即 “手里有锤子,处处是钉子”,很容易过度设计,导致无意义地加重复杂度,毕竟把握“精准平衡” 这四个字对于 架构师、设计师、研发工程师的要求不是一纸证书那么简单。
4|0从贫血到充血的前制条件
聊怎么做之前,先谈一谈必要性,即贫血一定要切换为充血么,其实从贫血过度到充血也不是必须品,至于要不要使用充血模式,取决于两个方面:
- 领域特性
- 团队成熟度
4|1领域特性
衡量是否必要的第一点就是领域逻辑的复杂度,充血模式最适合具有复杂领域逻辑的应用。如果业务比较复杂,随着我们对领域逻辑的了解,就能很快感受到基于数据的做法带来的限制。仅从数据出发,CRUD系统无法创建出好的业务模型。业务的复杂性可以体现在精巧的商业模式、复杂的制造过程、精益的管理方法等方面。
第二点就是领域的稳定性,这里的稳定性是指内在商业逻辑是稳定的,未来的需求主要集中在支撑功能和业务量的扩展上。当然,稳定性指标并不是绝对的,要看它所处的阶段。有的软件功能在时间长度上,几年内将不断变化,但一旦改变就不是简单的变更,例如金融、政策领域的一些法规。或者,虽然业务现阶段处于变化之中,但它的商业模式一旦形成,将作为企业的核心资产,例如新兴的移动互联网应用中的各种商业模式。它们都适合采用DDD,即便业务逻辑处在变化之中,我们也可以从DDD的另一个特性——快速测试和验证领域逻辑中收益,它可以为高频发布类应用提供很好的支持。
4|2团队成熟度
另一个说必要性有点不够准确,应该说是前置条件,那就是团队的成熟度。
团队的成熟度首先表现在团队的技术素养上,如果团队大多数人还需要花费大量时间去学习和体会面向对象技术(这些技术包括UML语言、面向对象设计、理解面向接口编程、基于服务的架构、设计模式、开发流程、需求分析等),那么在构建通用语言、模型设计和架构解耦上投入的精力就会受到限制,冒然转为充血模式的领域驱动,将是灾难性质的。
其次就是团队中一定要有 “领域专家”角色,这个领域专家严格来说只是一种角色,它可以泛指那些对业务领域的政策、工作流程、关键节点和特性都有深刻理解的所有人。一个判断标准是,他们对领域的论述是有体系的,而不是散乱的,而且十分清楚规则的应用范围。没有领域专家,就不会有通用语言和与语言一致的模型和代码。谁来保证我们是“领域驱动”,还是过度设计?即便是最简的设计,谁来验证呢?这个“最简”只能是个伪概念,领域专家的重要性是不可替代的。
说起前置条件不得不提一下项目的周期。相对来说,领域驱动更适合周期长的项目。交付时间过于紧张的项目,团队成员的注意力都会集中在功能的开发上,这时候强调领域知识的学习和领域模型的精炼,显然会和各利益相关者产生工作安排重点的冲突。相反,周期越长的项目,比如核心产品的研发,随着时间的推移,提炼出的领域模型就会逐步释放出它的威力。因此,项目生命周期越长,收益越大。
5|0如何从贫血到充血
主要是思考角度的转换,角度转换主要指两方面:需求视角, 不要过分纠结具体的功能,而是上升一层,去理解业务,抽象出业务对象和它们之间的关系;实现视角不要拘泥于具体代码或实现框架,要站在架构一层上,屏蔽掉系统对于数据的依赖细节,以面向对象的思维去构建系统。
5|1设计视角
“重业务轻功能”
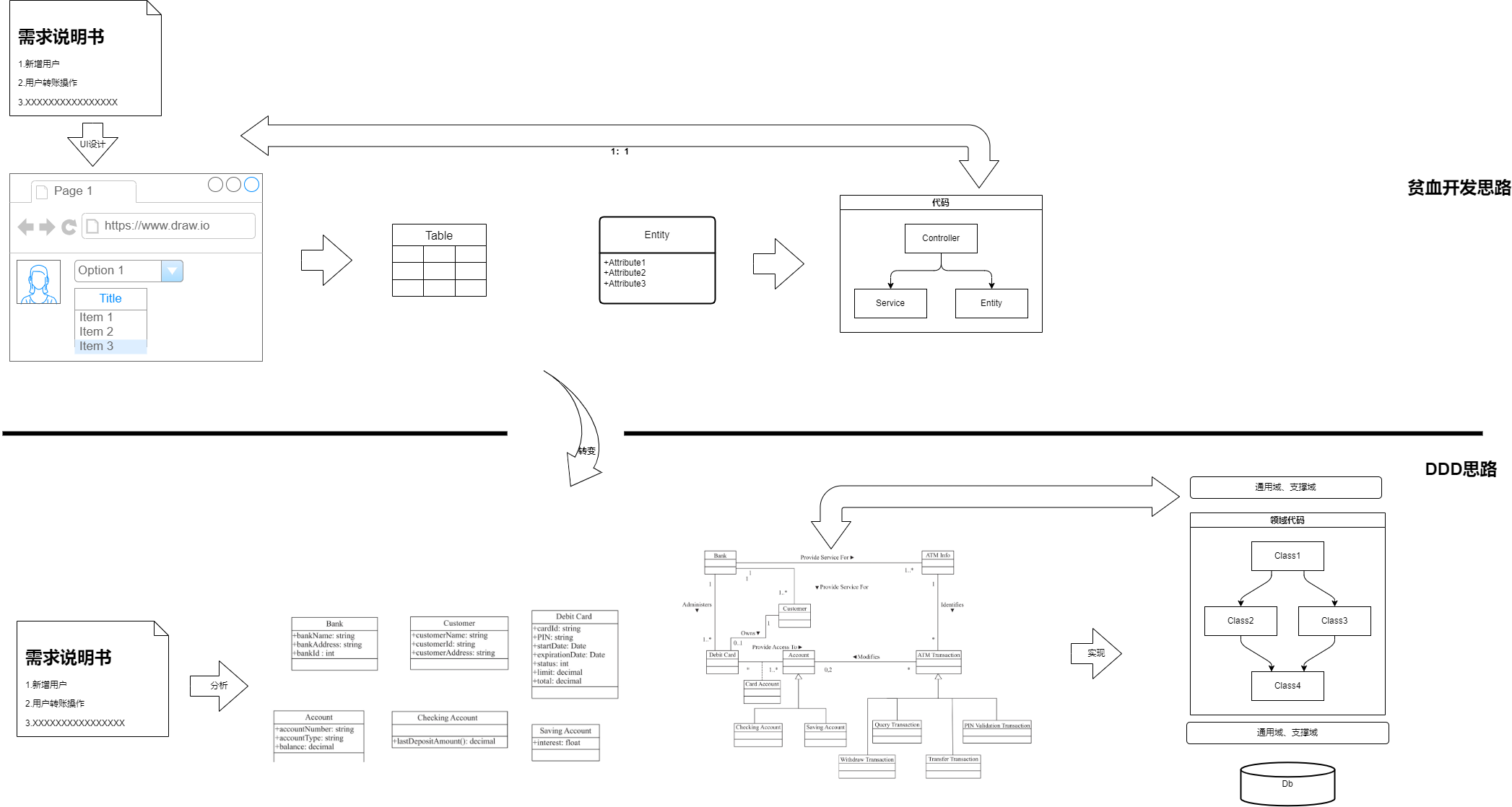
贫血模式所对应的开发方式更为“简单粗暴”,针对需求和功能页面,1:1的进行技术实现,直接针对功能复刻存储结构、参照MVC逐层进行编码开发,输出的成果本质上是对功能UI页面负责;这也是诸多研发人员即便参与工作或者某个项目很久,仍旧无法说清楚所谓“业务”的原因,因为在贫血模式下的开发都是公式化的功能代码转化,没有业务理解和设计。
而DDD实践的核心则是体系的业务逻辑,也就是说,在需求分析时尽可能的忽略实现细节与功能,转而进行业务逻辑的推演、建设,即重业务而轻功能。到具体实操上就是转换建模方式,舍弃ER数据建模转而使用OO建模。ER数据建模虽然也有一套分析设计方法论,但是由于过于注重数据库技术而忽视了业务上下文,极容易进入CRUD原子操作的思维。切换为DDD要做的就是转化这个思维角度,规避CRUD原子操作思维,进而使用日常思维模式、 业务术语来表达,例如使用“下单”替代“创建订单”,使用“发帖”替代“新增帖子”,使用“开票”替代“新增发票”等。从沟通传递开始就要有意识的进行转换, 如果纯粹以技术角度描述而脱离业务上下文,设计的逻辑性将很难去追溯和质疑,就好比说“穿的越少越好”,在冬天说和在夏天说的意义天差地别。在业务全貌的前提下,进行业务对象抽取而非表结构设计,结合抽取的业务对象和业务逻辑去绘制业务模型图,反向地验证业务理解的准确性。最终让输出的成果对业务模型图负责。
区分数据结构与对象
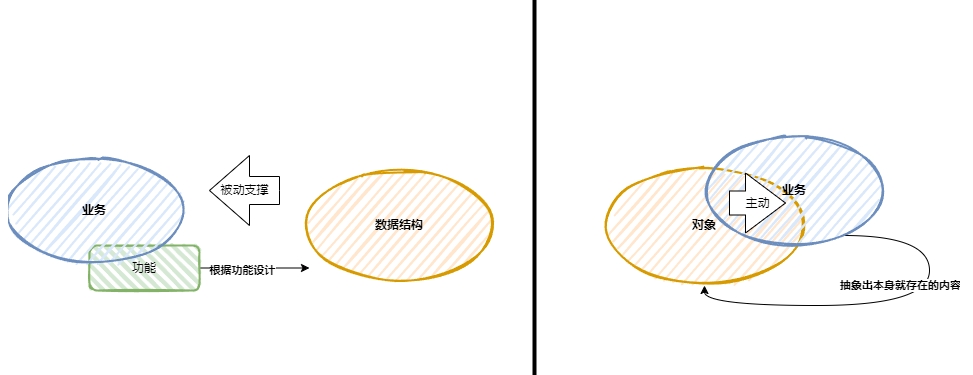
所有的模型、被二级制化的领域逻辑和数据都不可能一直活跃在内存中,而需要被存储在数据库或文件中。这时就要明确两个概念,数据表和对象。数据表是一种数据结构,而对象是数据和行为,也就是说,数据结构中的数据是被外部的某些行为或函数操作的;虽然对象或类中封装的属性其实也是数据,但对象或类有行为方法,这些行为可以保护被封装的属性数据,外界需要改变对象中的属性数据时,必须通过公开的行为方法才能实现。因此,对象和数据结构两者的区别之一就在于对数据的操作是主动还是被动——对象是主动操作数据,而数据结构的数据是被动操作。相对于复杂业务的系统,主动操作数据更容易表达业务,因为业务领域中的业务策略或业务规则都需要动态操作去保证,它们的逻辑性和完整性需要主动操作数据来完成。
5|2技术实现:
5|3切断数据与代码强耦合
贫血模型之所以“不面向对象”的一个重要原因就是持久化层的固化,之前也说过了,伴随着ORM和WEB技术的演进,数据持久层变得“公式化”,这种“公式化”造成了业务代码与持久化的耦合。 如果不能将这部分代码分离出去,领域层的独立性就无从谈起了。我们也不可能脱离技术复杂度而独立开发领域逻辑,所以领域模型要想保持自己的独立性,离不开存储库将其与持久化机制解耦。
贫血模式下很多情况是数据库表、SQL模型、ORM配置、实体类到Service逻辑集于一人开发,这就导致了一个问题,当个人拥有“穿透权限”时是很容易忽视边界感的,久而久之就会懈怠去维护层与层之间的边界,业务模型与底层数据通道耦合,难以重构和复用。

解决这种情况技术上就要建立DDD中支撑域的概念,在业务之下,创建真正的数据层,数据层需要反向依赖业务层中定义的需求接口,即数据层是纯技术实现层,实现参照就是各个领域中列出的interface类;对应的开发习惯也需要进行改变,即业务开发人员不要参与数据层的逻辑设计与开发,只需要在Domain中定义数据诉求接口即可,由专门的开发团队去完成数据层或者说数据底座的开发,这样能够保证边界感,同时也能防止代码泛滥。通过支撑域数据层和核心域业务层的依赖倒置,实现代码上的领域模型与数据的解耦。保证业务模型能够在不受底层技术影响的情况下进行演化,让我们可以独立开发领域模型,无须关注架构的技术细节。
利用领域概念进行技术整合
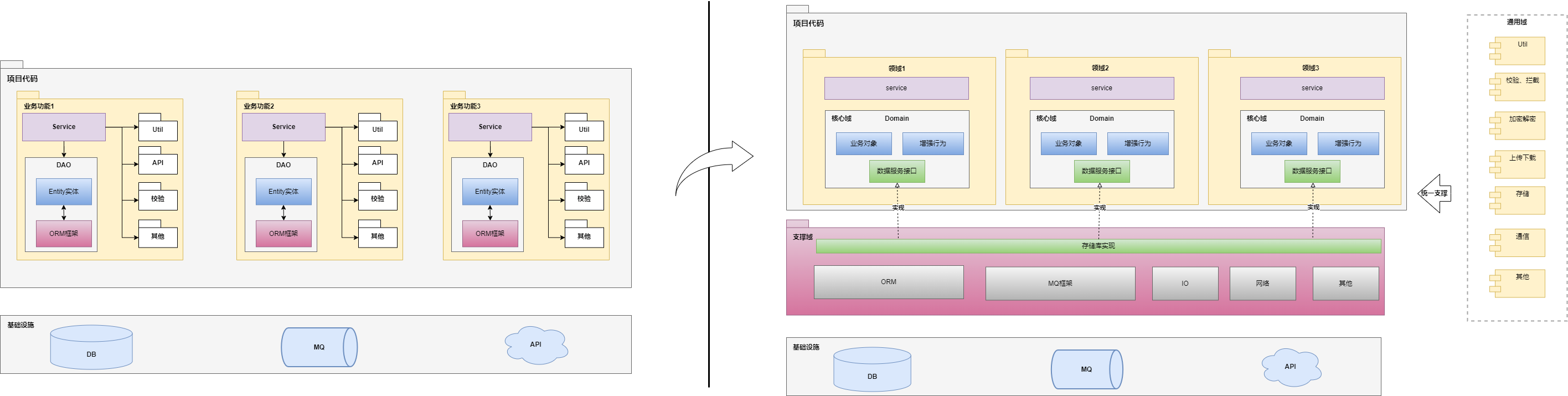
其实也不只是贫血模型,很多系统指数型熵增的一大原因就是技术、业务融为一体,业务除了本身的复杂性外还受限于技术的复杂性,两者相互纠缠,不死不休。可以先借助DDD思想进行架构的修正,DDD其实并没有给出明确的架构方案,只是提出了一个“立于不败”境地的思路——领域划分,而这种思路和“没有一成不变的架构,架构是动态演进的”正正契合。
领域划分中,可以有支撑域、通用域,此时,若是采取分层架构风格且体量较大的系统,则支撑域、通用域就可以作为基础底座,以纯技术的视角进行建设,对外部不可见。类似于上文中提到的数据层,仅仅对核心域暴露支撑接口,且这个接口还是由核心域提供。另外还包括包装接口、描绘界面、参数校验、数据封装、、安全、性能、各类Util工具包等等。而核心领域则可以在这个基座之上拆分为单独的module,配合整个平台统一的数据支撑域、组件通用域,形成模块化组装形态,各个领域不依赖数据结构、数据获取方式,而是提出数据需求,由支撑域完成核心域的需求,明确技术和业务的界限。
而对于微服务架构,DDD更多的是利用其领域划分提供服务划分依据(主要是核心域),技术上为保证各服务的独立性,需要弱化支撑域、通用域的概念,转而技术上将权限下放给各个服务,独立的各个微服务内部可以有自身独立的数据交互、数据持久化通道,保证各微服务的独立管理和演进,这也正是微服务的一个讨喜的点——技术上各服务不被条条框框所限制,发展空间较大。但是前提是微服务的划分是合理的,而这个合理与否,就在于业务领域划分是否合理。
6|0最后
最后补充一个点,就是心理角色的转换,切换领域驱动,不论是对研发还是产品经理亦或是其他设计分析人员都是个挑战,尤其研发人员,作为设计和落地的集中点,更要有成为领域专家的准备。意味着要有等同于产品的业务认识,一起参与需求的分析、业务领域的规划,而不是拘泥于“一招一式”的具体功能和编码。
__EOF__

本文链接: https://www.cnblogs.com/TheGCC/p/18282549.html
关于博主:评论和私信会在第一时间回复。或者 直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角 【推荐】一下。您的鼓励是博主的最大动力!

















 5950
5950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









