







一、sharding-jdbc与shardingproxy
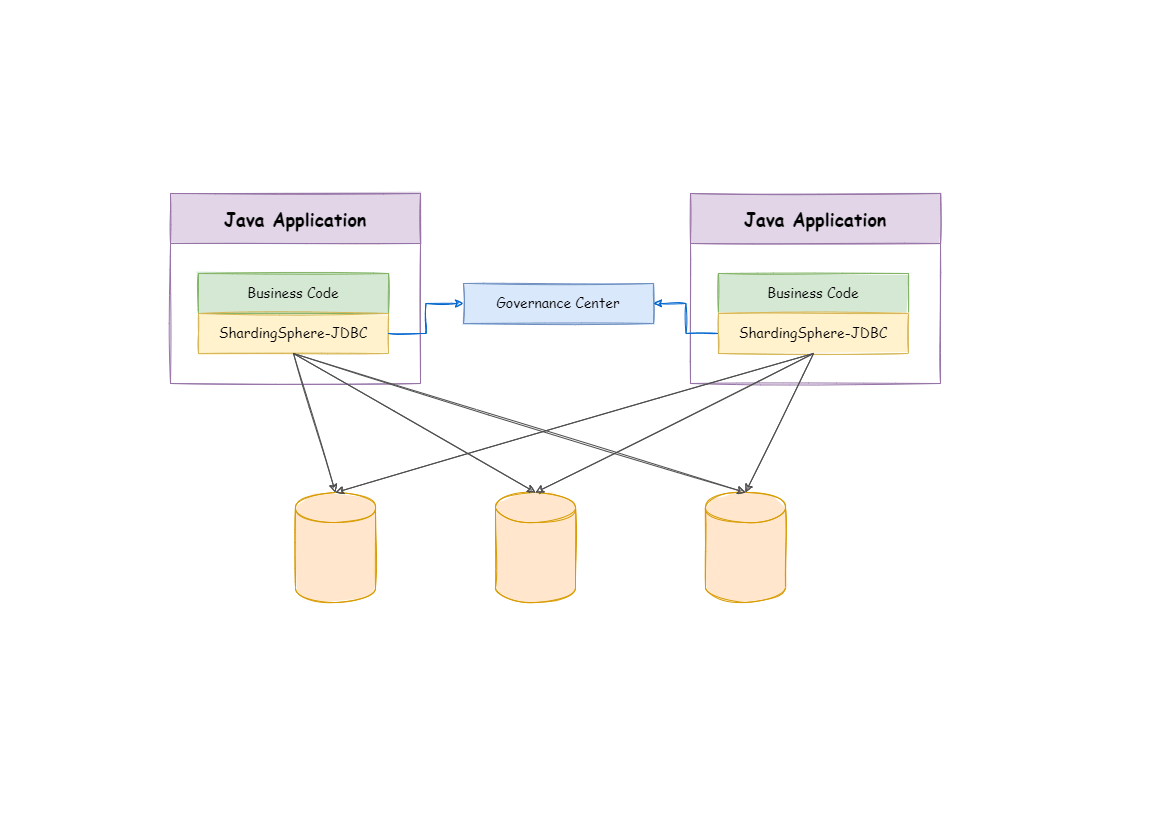
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架
适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持

向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。
ShardingSphere-JDBC | ShardingSphere-Proxy | |
数据库 | 任意 | MySQL/PostgreSQL |
连接消耗数 | 高 | 低 |
异构语言 | 仅 Java | 任意 |
性能 | 损耗低 | 损耗略高 |
无中心化 | 是 | 否 |
静态入口 | 无 | 有 |
二、核心概念
逻辑表:水平拆分的数据库的相同逻辑和数据结构表的总称
真实表:在分片的数据库中真实存在的物理表。
数据节点:数据分片的最小单元。由数据源名称和数据表组成
绑定表:分片规则一致的主表和子表。
广播表:也叫公共表,指素有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中都完全一致。例如字典表。
分片键:用于分片的数据库字段,是将数据库(表)进行水平拆分的关键字段。
SQL中若没有分片字段,将会执行全路由,性能会很差。
分片算法:通过分片算法将数据进行分片,支持通过=、BETWEEN和IN分片。分片算法需要由应用开发者自行实现,可实现的灵活度非常高。
分片策略:真正用于进行分片操作的是分片键+分片算法,也就是分片策略。在ShardingJDBC中一般采用基于Groovy表达式的inline分片策略,通过一个包含分片键的算法表达式来制定分片策略,如t_order$->{order_id%2}标识根据u_id模2,分成2张表,表名称为t_order0到t_order2。
db0
├── t_order0
└── t_order1
├── t_order_item0
├── t_order_item1
db1
├── t_order0
├── t_order1
├── t_order_item0
├── t_order_item1以上图为例,各种概念对应如下:
逻辑表:t_order
真实表: t_order0、t_order1、 t_order_item0、t_order_item1
数据节点:db0.t_order0、db0.t_order1、db0.t_order0、db1.t_order1
绑定表:t_order、t_order_item (都是按照order_id )分片
分片策略 = 分片键 + 分片算法
分片键:t_user_表中的uid (t_order$->{order_id%8})
分片算法:
自动化分片算法:便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现
自定义分片算法:提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。
标准分片算法:使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。
复合分片算法:使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
Hint 分片算法:用于处理使用 Hint 行分片的场景。
三、springboot整合sharding-jdbc
1、docker配置主从库

2、主服务创建表
CREATE TABLE `t_dict` (
`dict_id` bigint(0) PRIMARY KEY NOT NULL,
`ustatus` varchar(100) NOT NULL,
`uvalue` varchar(100) NOT NULL
);
CREATE TABLE `t_dict_1` (
`dict_id` bigint(0) PRIMARY KEY NOT NULL,
`ustatus` varchar(100) NOT NULL,
`uvalue` varchar(100) NOT NULL
);
CREATE TABLE `t_dict_2` (
`dict_id` bigint(0) PRIMARY KEY NOT NULL,
`ustatus` varchar(100) NOT NULL,
`uvalue` varchar(100) NOT NULL
);
CREATE TABLE `t_user` (
`user_id` bigint(0) PRIMARY KEY NOT NULL,
`username` varchar(100) NOT NULL,
`ustatus` varchar(50) NOT NULL,
`uage` int(3)
);
CREATE TABLE `t_user_1` (
`user_id` bigint(0) PRIMARY KEY NOT NULL,
`username` varchar(100) NOT NULL,
`ustatus` varchar(50) NOT NULL,
`uage` int(3)
);
CREATE TABLE `t_user_2` (
`user_id` bigint(0) PRIMARY KEY NOT NULL,
`username` varchar(100) NOT NULL,
`ustatus` varchar(50) NOT NULL,
`uage` int(3)
);
CREATE TABLE course (
cid BIGINT(20) PRIMARY KEY,
cname VARCHAR(50) NOT NULL,
user_id BIGINT(20) NOT NULL,
cstatus varchar(10) NOT NULL
);
CREATE TABLE course_1 (
cid BIGINT(20) PRIMARY KEY,
cname VARCHAR(50) NOT NULL,
user_id BIGINT(20) NOT NULL,
cstatus varchar(10) NOT NULL
);
CREATE TABLE course_2 (
cid BIGINT(20) PRIMARY KEY,
cname VARCHAR(50) NOT NULL,
user_id BIGINT(20) NOT NULL,
cstatus varchar(10) NOT NULL
);3、创建springbot项目中引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.demo</groupId>
<artifactId>ShardingSphereDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.3.1.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
</dependencies>
</project>4、通过mybatis-plus-generator反编译生成entity、mapper、service
5.1 单库分表
server.port=8080
#配置数据源
spring.shardingsphere.datasource.names=m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://192.168.2.133:3306/db1?useSSL=false
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
#配置真实表分布
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
#主键生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#配置分表策略
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
#
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
#其他运行属性
spring.shardingsphere.props.sql.show = true
spring.main.allow-bean-definition-overriding=true单测类
@Autowired
CourseMapper courseMapper;
@Test
public void addCourse(){
for(int i = 0 ; i < 10 ; i ++){
Course c = new Course();
c.setCname("test");
c.setUserId(Long.valueOf(""+(1000+i)));
c.setCstatus("1");
courseMapper.insert(c);
}
}主键id为奇数的分片到course_2,偶数course_1

5.2 多库分表,修改配置
#配置多个数据源
spring.shardingsphere.datasource.names=m1,m2
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://192.168.2.133:3306/db1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://192.168.2.133:3306/db1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123456
#真实表分布,分库,分表
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#inline分片策略
#spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
#spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
#inline策略--不支持范围查询
#spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=cid
#spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{cid%2+1}
#打印sql
spring.shardingsphere.props.sql.show = true
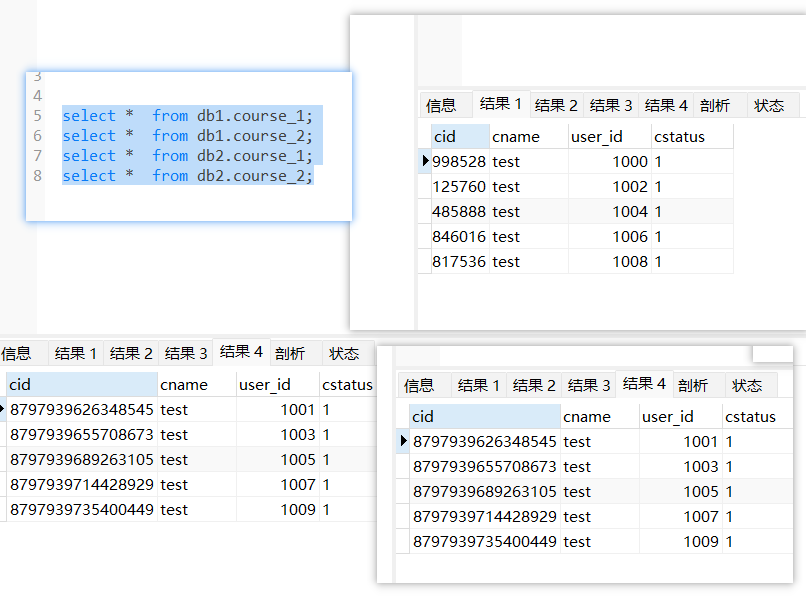
spring.main.allow-bean-definition-overriding=true主键为偶数进到db1.course_1,主键为奇数进到db2.course_2
5.3.分库、分表算法
实现 PreciseShardingAlgorithm 接口,并重写 doSharding() 方法,自行处理分库、分表逻辑。其他分片策略亦如此
select * from course where cid = ? or cid in (?,?)分库策略:通过对cid取模加1,计算落路由到那个库 ,使用的分库策略course_$->{cid%2+1)
public class MyPreciseDSShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
//select * from course where cid = ? or cid in (?,?)
@Override
public String doSharding(Collection<String> databaseNames, PreciseShardingValue<Long> cidValue) {
//实现 course_$->{cid%2+1)
BigInteger shardingValueB = BigInteger.valueOf(cidValue);
BigInteger resB = (shardingValueB.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = "m"+resB;
if(availableTargetNames.contains(key)){
return key;
}
}
}public class MyPreciseDSShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
//实现 course_$->{cid%2+1)
BigInteger cidValue = BigInteger.valueOf(shardingValue);
BigInteger resB = (cidValue.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = "m"+resB;
if(availableTargetNames.contains(key)){
return key;
}
}
}分库策略配置:databaseNames 参数为所有的数据库,cidValue为分片键
spring.shardingsphere.sharding.tables.course.database-strategy.standard.sharding-column=cid
spring.shardingsphere.sharding.tables.course.database-strategy.standard.precise-algorithm-class-name=com.kbp.shard.algorithem.MyPreciseDSShardingAlgorithmpublic class MyPreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
//select * from course where cid = ? or cid in (?,?)
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
//实现 course_$->{cid%2+1)
BigInteger cidValue = BigInteger.valueOf(cidValue);
BigInteger resB = (cidValue.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = logicTableName+"_"+resB;
if(availableTargetNames.contains(key)){
//couse_1, course_2
return key;
}
}
}分表策略配置:
spring.shardingsphere.sharding.tables.course.table-strategy.standard.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.standard.precise-algorithm-class-name=com.kbp.shard.algorithem.MyPreciseTableShardingAlgorithm5.3 分布式事务一致性
@Test
@Transactional(rollbackFor = Exception.class)
@ShardingTransactionType(TransactionType.XA)
public void addCourseTX(){
for(int i = 0 ; i < 10 ; i ++){
Course c = new Course();
c.setCname("test");
c.setUserId(Long.valueOf(""+(1000+i)));
c.setCstatus("1");
courseMapper.insert(c);
if(i == 4){
int a = 1/0;
}
}
}Sharding jdbc 可以通过@ShardingTransactionType(TransactionType.XA),加在方法上就可以;当抛出异常的时候,之前插入的数据全部回滚,避免部分插入














 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









