









背景
公司项目中有用到caffeine cache 所以来了解一下。
本地缓存也就是我们适用内存缓存一些热点数据,使应用程序的程序处理的更加的快。以及保护我们的一些有磁盘/网络IO操作的函数/方法,以达到减小我们服务的响应时间的目的。
对于java技术栈来讲我们通常使用到的本地缓存都有 一些原有的容器HashMap,google的guava cache等等。今天了解一下caffine缓存。
简介
Caffeine 是基于Java 8 开发的、提供了近乎最佳命中率的高性能本地缓存组件,Spring5 开始不再支持 Guava Cache,改为使用 Caffeine。
我们先看一下github 官方:Caffeine 是一个高性能Java 缓存库,提供近乎最佳的命中率。 对于高性能我们很容易理解,最直接的理解就是快,然后支持的并发量很高。但是对于近乎最佳的命中率,为什么这么说呢?
官方文档: https://maven-badges.herokuapp.com/maven-central/com.github.ben-manes.caffeine/caffeine
Maven centry :https://maven-badges.herokuapp.com/maven-central/com.github.ben-manes.caffeine/caffeine
Caffeine 原理
既然是缓存,并且是缓存到的是java进程中,对于java进程中,一般在jvm 动态运行时的存储区域为我们的堆内存中,那这份资源是相当珍贵的,不可能让缓存资源导致我们的程序OOM,随意本地缓存一般都是有淘汰策略的,其实包括我们的JVM垃圾回收机制,包括java的四种(强软弱虚)引用类型都是为了节约我们珍贵的内存资源而有的。言回正传们,那Caffeine cache的是通过什么淘汰算法实现的呢?
缓存淘汰策略
常见的缓存策略
- FIFO(First In First Out):先进先出。
它是优先淘汰掉最先缓存的数据、是最简单的淘汰算法。缺点是如果先缓存的数据使用频率比较高的话,那么该数据就不停地进进出出,因此它的缓存命中率比较低。这也就是caffenie所描述的近乎最佳的命中率
- LRU(Least Recently Used):最近最久未使用。
它是优先淘汰掉最久未访问到的数据。缺点是不能很好地应对偶然的突发流量。有一批数据在59秒都没有被访问,然后到1分钟的时候过期了,但在1分01秒来了大批量的访问,导致穿透缓存,打垮数据库。
- LFU(Least Frequently Used):
最近最少频率使用。它是优先淘汰掉最不经常使用的数据,需要维护一个表示使用频率的字段。 就凭这个字段对于缓存来说就是很不友好的,因为我们的内存资源是真的很可贵的。
-
W-TinyLFU (WFLU)算法
-
Caffeine 使用了 W-TinyLFU 算法,解决了 LRU 和LFU上述的缺点。W-TinyLFU 算法由论文《TinyLFU: A Highly Efficient Cache Admission Policy》提出。
-
解决第一个问题是采用了 Count–Min Sketch 算法。降低频率信息带来的内存消耗;
-
解决第二个问题是让记录尽量保持相对的“新鲜”(Freshness Mechanism),并且当有新的记录插入时,可以让它跟老的记录进行“PK”,输者就会被淘汰,这样一些老的、不再需要的记录就会被剔除。PK机制保障新上的热点数据能够缓存。
1、统计频率 Count–Min Sketch 算法
Count-Min Sketch 是数据库中用到的一种 Sketch,所谓 sketch 就是用很少的一点数据来描述全体数据的特性,牺牲了准确性但是代价变得很低。算是有点理解了,那这其实会让我们想到 bloom Filter 他也就通过少量的数据描述一个相对存储较大的数据特征。
bloom Filter 原理基本是一个数组,而CM-Sketch 的内部数据结构是一个二维数组count,宽度w,深度d,此外还需要d个两两独立的哈希函数 ,更新的时候,用这些哈希函数算出 d个不同的哈希值,然后把对应的行的值加上c
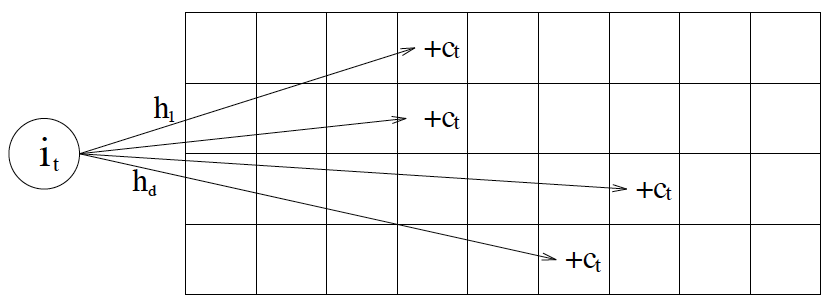
如下图缓存访问频率存储主要分为两大部分,即 LRU 和 Segmented LRU 。新访问的数据会进入第一个 LRU,在 Caffeine 里叫 WindowDeque。当 WindowDeque 满时,会进入 Segmented LRU 中的 ProbationDeque,在后续被访问到时,它会被提升到 ProtectedDeque。当 ProtectedDeque 满时,会有数据降级到 ProbationDeque 。数据需要淘汰的时候,对 ProbationDeque 中的数据进行淘汰。具体淘汰机制:取ProbationDeque 中的队首和队尾进行 PK,队首数据是最先进入队列的,称为受害者,队尾的数据称为攻击者,比较两者 频率大小,大胜小汰。
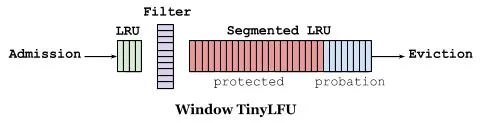
总的来说,通过 reset 衰减,避免历史热点数据由于频率值比较高一直淘汰不掉,并且通过对访问队列分成三段,这样避免了新加入的热点数据早早地被淘汰掉。那就是通过
高性能读
在github上的简介第一句话就是高性能读写,我们现在来看一下 高性能读写是如何实现的
Caffeine 认为读操作是频繁的,写操作是偶尔的,读写都是异步线程更新频率信息。
读缓冲
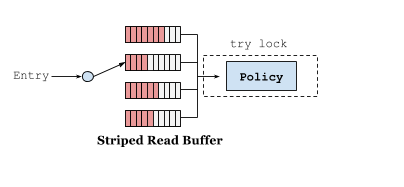
传统的缓存实现将会为每个操作加锁,以便能够安全的对每个访问队列的元素进行排序。一种优化方案是将每个操作按序加入到缓冲区中进行批处理操作。读完把数据放到环形队列 RingBuffer 中,为了减少读并发,采用多个 RingBuffer,每个线程都有对应的 RingBuffer。环形队列是一个定长数组,提供高性能的能力并最大程度上减少了 GC所带来的性能开销。数据丢到队列之后就返回读取结果,类似于数据库的WAL机制,和ConcurrentHashMap 读取数据相比,仅仅多了把数据放到队列这一步。异步线程并发读取 RingBuffer 数组,更新访问信息,这边的线程池使用的是下文实战小节讲的 Caffeine 配置参数中的 executor。
写缓冲
与读缓冲类似,写缓冲是为了储存写事件。读缓冲中的事件主要是为了优化驱逐策略的命中率,因此读缓冲中的事件完整程度允许一定程度的有损。但是写缓冲并不允许数据的丢失,因此其必须实现为一个安全的队列。Caffeine 写是把数据放入MpscGrowableArrayQueue 阻塞队列中,它参考了JCTools里的MpscGrowableArrayQueue ,是针对 MPSC- 多生产者单消费者(Multi-Producer & Single-Consumer)场景的高性能实现。多个生产者同时并发地写入队列是线程安全的,但是同一时刻只允许一个消费者消费队列。
Caffeine 实战
配置参数
Caffeine 借鉴了Guava Cache 的设计思想,如果之前使用过 Guava Cache,那么Caffeine 很容易上手,只需要改变相应的类名就行。构造一个缓存 Cache 示例代码如下:
Cache cache = Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(6, TimeUnit.MINUTES).softValues().build();Caffeine 类相当于建造者模式的 Builder 类,通过 Caffeine 类配置 Cache,配置一个Cache 有如下参数:
-
expireAfterWrite:写入间隔多久淘汰;
-
expireAfterAccess:最后访问后间隔多久淘汰;
-
refreshAfterWrite:写入后间隔多久刷新,该刷新是基于访问被动触发的,支持异步刷新和同步刷新,如果和 expireAfterWrite 组合使用,能够保证即使该缓存访问不到、也能在固定时间间隔后被淘汰,否则如果单独使用容易造成OOM;
-
expireAfter:自定义淘汰策略,该策略下 Caffeine 通过时间轮算法来实现不同key 的不同过期时间;
-
maximumSize:缓存 key 的最大个数;
-
weakKeys:key设置为弱引用,在 GC 时可以直接淘汰;
-
weakValues:value设置为弱引用,在 GC 时可以直接淘汰;
-
softValues:value设置为软引用,在内存溢出前可以直接淘汰;
-
executor:选择自定义的线程池,默认的线程池实现是 ForkJoinPool.commonPool();
-
maximumWeight:设置缓存最大权重;
-
weigher:设置具体key权重;
-
recordStats:缓存的统计数据,比如命中率等;
-
removalListener:缓存淘汰监听器;
-
writer:缓存写入、更新、淘汰的监听器。
总结
- Caffeine cache是一个本地缓存。
- 相对于其他的本地缓存,他有高性能和近乎完全命中的优势
- 高性能来源于他的缓冲查和缓冲写机制
- 高命中率来源于WLRU缓存淘汰机制
- 以及算法的原理和原油淘汰机制的劣势。
参考
- https://zhuanlan.zhihu.com/p/348695568
- https://titanssword.github.io/2018-02-23-Bloom%20Filter%20and%20Count-Min%20Sketch.html
- https://nan01ab.github.io/2018/04/TinyLFU.html
- https://github.com/ben-manes/caffeine
-















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









